Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
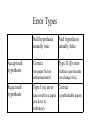
Introduction to Statistics Harry R. Erwin, PhD School of Computing and Technology University of Sunderland Resources • Crawley, MJ (2005) Statistics: An Introduction Using R. Wiley. • Gentle, J (2002) Elements of Computational Statistics. Springer. • Gonick, L., and Woollcott Smith (1993) A Cartoon Guide to Statistics. HarperResource (for fun). Who am I? • Dr. Harry Erwin BS MA PhD MIET MBCS • My PhD was awarded in bioinformatics. Although my research interests are in neuroscience, I've had the coursework and understand current research directions in computational biology and statistics. I’ve also had the coursework for a PhD in mathematics. • I teach computing and neuroscience here at the University of Sunderland. Doing Statistics • Usually you do statistics to explore the structure of data. The questions you might ask are rather openended. Your understanding is facilitated by a model. • A model embodies what you currently know about the data. You can formulate it either as a data-generating process or a set of rules for processing the data. • We’ll look at modelling in detail later. Statistical Models • Often expressed as a set of equations relating data elements. • Can include probability distributions for the elements. If this is the case, you have a stochastic model. • The model should be free to evolve based on data mining. Common Stochastic Models • Parameterized statistical distributions, such as the normal distribution, binomial distribution, or the chi-squared distribution. • Sometimes more complicated, where you might need to use simulation, resampling, and visualization to determine the parameters of the model. Structure-in-the-data • Of most interest…, for example: – – – – – – Modes Gaps Clusters Symmetry Shape Deviations from normality Visualization • Multiple views are necessary, particularly for multivariate data. • Be able to zoom in on the data as a few points can obscure the interesting structure. • Scaling of the axes may be necessary, since our eyes are not perfect tools for detecting structure. • Watch out for time-ordered or location-ordered data, particularly if time or location are not explicitly reported. Plots • Use simple plots to start with. • Watch for rounded data—shown by horizontal strata in the data. That often signals other problems. • There are a number of plotting tutorials, consult them. Statistical Activities • Data collection (ideally the statistician has a say on how they are collected) • Description of a dataset – Averages – Spreads – Extreme points • Inference within a model or collection of models • Model selection How to Do It • Start by determining what sort of statistical analysis you will be doing. You need to know: – – – – Which variable is the response variable? Which are the explanatory variables? What kind are the explanatory variables? What kind of response variable do you have? • If you have multiple response variables, you need to do multivariate analysis (more advanced). Basic Methods • If all explanatory variables are continuous, plan on a regression analysis. • If all explanatory variables are categorical, plan for an analysis of variance (ANOVA). • If you have a mix, plan for an analysis of covariance (ANCOVA) Effect of the Response Variable • If the response variable is continuous, then plan on a normal regression, ANOVA, or ANCOVA. • If the response variable is a proportion, do a logistic regression. • If a count, you need a log linear model. • If binary, you need a binary logistic analysis • If time to event or time at death, you will be doing a survival analysis. Variation • You want to understand how the response is dependent on variation in the explanatory variables, but you are also interested in lack of dependence. • Design the simplest model that explains the data adequately. Significance • You have to determine what the probability of a false alarm will be—that is, the chance that you will think something is significant which really is not. • Typical values are 5%, 1%, and 0.1%. • Don’t test every hypothesis. Some will be true by chance. Good and Bad Hypotheses • • • • ‘There are vultures in the local park.’ ‘There are no vultures in the local park.’ Which is testable? Discuss… Answer • The ‘null hypothesis’ is testable. • ‘There are no vultures in the local park.’ • You test it by taking measurements and showing that if the null hypothesis were true, the chance of those measurements would be close to zero. • Discuss further… Experimental Design • Replication – Increases reliability, so be thorough. Often the answer is ‘30’. – Discuss why. • Randomization – Reduces systematic bias, so do it properly – Almost never done properly – Discuss why. Controls • “No controls, no conclusions.” • A ‘control experiment’ is one where you don’t apply the treatment or don’t enable the part of your experiment that is supposed to produce the different outcome. • You’re comparing the results when the treatment is applied to the results with no treatment. Replication • • • • • Must be independent Not part of a time series Not grouped together in space Of an appropriate spatial scale Covers the normal variation in initial conditions. Error Types Null hypothesis actually true Null hypothesis actually false Accept null hypothesis Correct Type II () error (no paper but no embarrassment) (further experiments can change this) Reject null hypothesis Type I () error Correct (can result in a paper (a publishable paper) you have to withdraw) Typical and values • You usually want the probability of rejecting the null hypothesis () when it is true to be less than 5%. • You usually want the probability of accepting the null hypothesis () when it is false to be less than 20%. • The power of a test is 1- , or greater than 80% in this case. • Rule of Thumb: the number of replicates to reject the null hypothesis with probability 80% is about 8s2/d2, where s2 is the variance in the response and d is the size of the difference to be detected in a single sample. Inference • Strong inference – A clear hypothesis – An acceptable test • Weak inference – Natural experiments • Conclusions from natural experiments are hypotheses. Can still produce good papers. • Discuss How Long to Go On? • To stop the experiment as soon as a pleasing result is obtained? • To keep going until the theoretically correct result is obtained? • Discuss. • Gregor Mendel’s experiments with peas.