Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Group analyses of fMRI data
Klaas Enno Stephan
Laboratory for Social and Neural Systems Research
Institute for Empirical Research in Economics
University of Zurich
Functional Imaging Laboratory (FIL)
Wellcome Trust Centre for Neuroimaging
University College London
With many thanks for slides & images to:
FIL Methods group,
particularly Will Penny
Methods & models for fMRI data analysis
26 November 2008
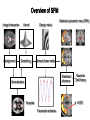
Overview of SPM
Image time-series
Realignment
Kernel
Design matrix
Smoothing
General linear model
Statistical parametric map (SPM)
Statistical
inference
Normalisation
Gaussian
field theory
p <0.05
Template
Parameter estimates
Why hierachical models?
fMRI, single subject
fMRI, multi-subject
EEG/MEG, single subject
ERP/ERF, multi-subject
Hierarchical models for all imaging
data!
Reminder: voxel-wise time series analysis!
model
specification
Time
parameter
estimation
hypothesis
statistic
BOLD signal
single voxel
time series
SPM
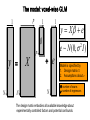
The model: voxel-wise GLM
p
1
1
1
p
y
N
=
N
X
y X e
e ~ N (0, I )
2
+
N
e
Model is specified by
1. Design matrix X
2. Assumptions about e
N: number of scans
p: number of regressors
The design matrix embodies all available knowledge about
experimentally controlled factors and potential confounds.
GLM assumes Gaussian “spherical” (i.i.d.) errors
sphericity = iid:
error covariance is
scalar multiple of
identity matrix:
Cov(e) = 2I
Examples for non-sphericity:
4 0
Cov(e)
0
1
non-identity
1 0
Cov(e)
0
1
2 1
Cov(e)
1
2
non-independence
Multiple covariance components at 1st level
V Cov(e)
e ~ N (0, V )
2
enhanced noise model
V
= 1
V iQi
error covariance components Q
and hyperparameters
Q1
+ 2
Q2
Estimation of hyperparameters with ReML (restricted maximum
likelihood).
t-statistic based on ML estimates
Wy WX We
̂ (WX ) Wy
c=10000000000
c ˆ
t
stˆd (cT ˆ )
T
W V
stˆd (cT ˆ )
ˆ c (WX ) (WX ) c
1 / 2
ˆ
2
V Cov(e)
2
2 T
T
Wy WXˆ
2
tr( R)
R I WX (WX )
X
V
Q
i
i
For brevity:
ReMLestimates
(WX ) ( X TWX )1 X T
Group level inference: fixed effects (FFX)
• assumes that parameters are “fixed properties of the
population”
• all variability is only intra-subject variability, e.g. due to
measurement errors
• Laird & Ware (1982): the probability distribution of the data
has the same form for each individual and the same
parameters
• In SPM: simply concatenate the data and the design
matrices
lots of power (proportional to number of scans),
but results are only valid for the group studied, can’t be
generalized to the population
Group level inference: random effects (RFX)
• assumes that model parameters are probabilistically
distributed in the population
• variance is due to inter-subject variability
• Laird & Ware (1982): the probability distribution of the data
has the same form for each individual, but the parameters
vary across individuals
• In SPM: hierarchical model
much less power (proportional to number of
subjects), but results can (in principle) be
generalized to the population
Recommended reading
Linear hierarchical models
Mixed effect models
Linear hierarchical model
Hierarchical model
Multiple variance components
at each level
y X (1) (1) (1)
(1) X ( 2) ( 2) ( 2)
C Q
(i)
(i)
( n 1) X ( n ) ( n ) ( n )
At each level, distribution of parameters
is given by level above.
What we don’t know: distribution of
parameters and variance parameters.
k
k
(i)
k
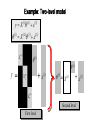
Example: Two-level model
1 1
yX
1
2 2
X
X 1(1)
y =
1
2
1
2
+ 1
X 2(1)
1 = X 2
+ 2
X 3(1)
Second level
First level
Two-level model
y X (1) (1) (1)
(1) X (2) (2) (2)
y X (1) X (2) (2) (2) (1)
X (1) X (2) (2) X (1) (2) (1)
random effects
Friston et al. 2002, NeuroImage
random effects
Mixed effects analysis
Non-hierarchical model
y X (1) X (2) (2) X (1) (2) (1)
ˆ(1) X (1) y
X (2) (2) (2) X (1) (1)
Estimating 2nd level effects
X (2) (2) (2)
Variance components at 2nd
level
Cov
(2)
C
(2)
X
(1)
(1)
C X
(1) T
between-level non-sphericity
Additionally: within-level nonsphericity at both levels!
C
(i )
k Qk(i )
(i )
k
Friston et al. 2005, NeuroImage
Estimation
y X
N 1
N p p1
EM-algorithm
N 1
C | y ( X T C1 X ) 1
| y C | y X C y
T
maximise L ln p( y | λ)
dL
d
d 2L
J 2
d
J 1 g
1
E-step
g
C k Qk
k
Assume, at voxel j:
M-step
jk j k
Friston et al. 2002, NeuroImage
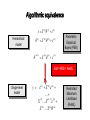
Algorithmic equivalence
y X (1) (1) (1)
Hierarchical
model
(1)
X
( 2)
( 2)
( 2)
Parametric
Empirical
Bayes (PEB)
( n 1) X ( n ) ( n ) ( n )
EM = PEB = ReML
Single-level
model
y (1) X (1) ( 2)
...
X (1) X ( n1) ( n )
X (1) X ( n ) ( n )
Restricted
Maximum
Likelihood
(ReML)
Mixed effects analysis
y data
X [ X (0)
V I
Summary
statistics
X [ X ( 0)
X (1) ]
X (1) X ( 2) ]
Q {Q1(1) ,, X (1) Q1( 2) X (1)T ,}
Step 1
ˆ (1) ( X TV 1 X ) 1 X TV 1 y
REML{ yyT n , X , Q}
Y ˆ (1)
X X ( 2)
V (i1) X (1) Qi(1) X (1) T (j2 )Q (j 2)
i
EM
approach
Friston et al. 2005, NeuroImage
j
Step 2
ˆ ( 2) ( X TV 1 X ) 1 X TV 1 y
ˆ(2)
Practical problems
Most 2-level models are just too big to
compute.
And even if, it takes a long time!
Moreover, sometimes we are only
interested in one specific effect and do
not want to model all the data.
Is there a fast approximation?
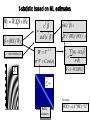
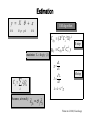
Summary statistics approach
First level
Data
Design Matrix
̂1
̂ 12
Second level
Contrast Images
t
cT ˆ
Vaˆr (cT ˆ )
SPM(t)
̂ 2
̂ 22
̂11
ˆ112
̂12
ˆ122
One-sample
t-test @ 2nd level
Validity of the summary statistics approach
The summary stats approach is exact if for each
session/subject:
Within-session covariance the same
First-level design the same
One contrast per session
All other cases: Summary stats approach seems to be
fairly robust against typical violations.
Reminder: sphericity
C Cov( ) E ( )
T
y X
Scans
„sphericity“ means:
Cov( ) I
2
i.e. Var ( )
i
2
Scans
2 1
2nd level: non-sphericity
Error
covariance
Errors are independent
but not identical:
e.g. different groups (patients,
controls)
Errors are not independent
and not identical:
e.g. repeated measures for each
subject (like multiple basis
functions)
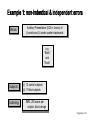
Example 1: non-indentical & independent errors
Stimuli:
Auditory Presentation (SOA = 4 secs) of
(i) words and (ii) words spoken backwards
e.g.
“Book”
and
“Koob”
Subjects:
Scanning:
(i) 12 control subjects
(ii) 11 blind subjects
fMRI, 250 scans per
subject, block design
Noppeney et al.
1st level:
Controls
Blinds
2nd level:
V
cT [1 1]
X
Example 2: non-indentical & non-independent errors
Stimuli:
Subjects:
Scanning:
Question:
Auditory Presentation (SOA = 4 secs) of words
1. Motion
2. Sound
3. Visual
4. Action
“jump”
“click”
“pink”
“turn”
(i) 12 control subjects
fMRI, 250 scans per
subject, block design
What regions are affected
by the semantic content of
the words?
1. Words referred to body motion. Subjects decided
if the body movement was slow.
2. Words referred to auditory features. Subjects
decided if the sound was usually loud
3. Words referred to visual features. Subjects
decided if the visual form was curved.
4. Words referred to hand actions. Subjects decided
if the hand action involved a tool.
Noppeney et al.
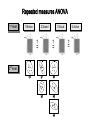
Repeated measures ANOVA
1st level:
1.Motion
2.Sound
?
=
3.Visual
?
?
=
=
X
2nd level:
4.Action
Repeated measures ANOVA
1st level:
1.Motion
2.Sound
?
3.Visual
?
?
=
4.Action
=
=
X
2nd level:
1 1 0 0
cT 0 1 1 0
0 0 1 1
V
X
Practical conclusions
•
Linear hierarchical models are general enough for typical multisubject imaging data (PET, fMRI, EEG/MEG).
• Summary statistics are robust approximation to mixed-effects
analysis.
– Use mixed-effects model only, if seriously in doubt about validity of
summary statistics approach.
• RFX: If not using multi-dimensional contrasts at 2nd level (Ftests), use a series of 1-sample t-tests at the 2nd level.
– To minimize number of variance components to be estimated at 2nd level,
compute relevant contrasts at 1st level and use simple test at 2nd level.
Thank you