Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
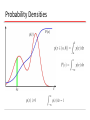
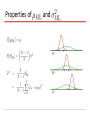
Machine Learning CMPT 726 Simon Fraser University CHAPTER 1: INTRODUCTION Outline • Comments on general approach. • Probability Theory. • Joint, conditional and marginal probabilities. • Random Variables. • Functions of R.V.s • Bernoulli Distribution (Coin Tosses). • Maximum Likelihood Estimation. • Bayesian Learning With Conjugate Prior. • The Gaussian Distribution. • Maximum Likelihood Estimation. • Bayesian Learning With Conjugate Prior. • More Probability Theory. • Entropy. • KL Divergence. Our Approach • The course generally follows statistics, very interdisciplinary. • Emphasis on predictive models: guess the value(s) of target variable(s). “Pattern Recognition” • Generally a Bayesian approach as in the text. • Compared to standard Bayesian statistics: • more complex models (neural nets, Bayes nets) • more discrete variables • more emphasis on algorithms and efficiency Things Not Covered • Within statistics: • Hypothesis testing • Frequentist theory, learning theory. • Other types of data (not random samples) • Relational data • Scientific data (automated scientific discovery) • Action + learning = reinforcement learning. Could be optional – what do you think? Probability Theory Apples and Oranges Probability Theory Marginal Probability Joint Probability Conditional Probability Probability Theory Sum Rule Product Rule The Rules of Probability Sum Rule Product Rule Bayes’ Theorem posterior likelihood × prior Bayes’ Theorem: Model Version • Let M be model, E be evidence. •P(M|E) proportional to P(M) x P(E|M) Intuition • prior = how plausible is the event (model, theory) a priori before seeing any evidence. • likelihood = how well does the model explain the data? Probability Densities Transformed Densities Expectations Conditional Expectation (discrete) Approximate Expectation (discrete and continuous) Variances and Covariances The Gaussian Distribution Gaussian Mean and Variance The Multivariate Gaussian Reading exponential prob formulas • In infinite space, cannot just form sum Σx p(x) grows to infinity. • Instead, use exponential, e.g. p(n) = (1/2)n • Suppose there is a relevant feature f(x) and I want to express that “the greater f(x) is, the less probable x is”. • Use p(x) = exp(-f(x)). Example: exponential form sample size • Fair Coin: The longer the sample size, the less likely it is. • p(n) = 2-n. ln[p(n)] Sample size n Exponential Form: Gaussian mean • The further x is from the mean, the less likely it is. ln[p(x)] 2(x-μ) Smaller variance decreases probability • The smaller the variance σ2, the less likely x is (away from the mean). ln[p(x)] -σ2 Minimal energy = max probability • The greater the energy (of the joint state), the less probable the state is. ln[p(x)] E(x) Gaussian Parameter Estimation Likelihood function Maximum (Log) Likelihood Properties of and Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares error, . Predictive Distribution Frequentism vs. Bayesianism • Frequentists: probabilities are measured as the frequencies of repeatable events. • E.g., coin flips, snow falls in January. • Bayesian: in addition, allow probabilities to be attached to parameter values (e.g., P(μ=0). • Frequentist model selection: give performance guarantees (e.g., 95% of the time the method is right). • Bayesian model selection: choose prior distribution over parameters, maximize resulting cost function (posterior). MAP: A Step towards Bayes Determine by minimizing regularized sum-of-squares error, . Bayesian Curve Fitting Bayesian Predictive Distribution Model Selection Cross-Validation Curse of Dimensionality Rule of Thumb: 10 datapoints per parameter. Curse of Dimensionality Polynomial curve fitting, M = 3 Gaussian Densities in higher dimensions Decision Theory Inference step Determine either or . Decision step For given x, determine optimal t. Minimum Misclassification Rate Minimum Expected Loss Example: classify medical images as ‘cancer’ or ‘normal’ Truth Decision Minimum Expected Loss Regions are chosen to minimize Why Separate Inference and Decision? • Minimizing risk (loss matrix may change over time) • Unbalanced class priors • Combining models Decision Theory for Regression Inference step Determine . Decision step For given x, make optimal prediction, y(x), for t. Loss function: The Squared Loss Function Generative vs Discriminative Generative approach: Model Use Bayes’ theorem Discriminative approach: Model directly Entropy Important quantity in • coding theory • statistical physics • machine learning Entropy Entropy Coding theory: x discrete with 8 possible states; how many bits to transmit the state of x? All states equally likely Entropy The Maximum Entropy Principle • Commonly used principle for model selection: maximize entropy. • Example: In how many ways can N identical objects be allocated M bins? Entropy maximized when Differential Entropy and the Gaussian Put bins of width ¢ along the real line Differential entropy maximized (for fixed in which case ) when Conditional Entropy The Kullback-Leibler Divergence Mutual Information