Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
AI in game (IV)
Oct. 11, 2006
So far
• Artificial Intelligence: A Modern Approach
– Stuart Russell and Peter Norvig
– Prentice Hall, 2nd ed.
– Chapter 1: AI taxonomy
– Chapter 2: agents
– Chapter 3: uninformed search
– Chapter 4: informed search
From now on
• Artificial Intelligence: A Modern Approach
– Chapter 4.
– Chapter 6: adversarial search
• Network part
• Learning (maybe from the same textbook)
• Game AI techniques
Outline
• Ch 4. informed search
– Online search
• Ch 6. adversarial search
– Optimal decisions
– α-β pruning
– Imperfect, real-time decisions
Offline search vs. online search
• Offline search agents
– Compute a solution before setting foot in the
real world
–
• Online search agents
– Interleave computation and action
• E.g. takes an action and then observes
environments and then computes the next action
– Necessary for an exploration problem
• States and actions are unknown
• E.g. robot in a new building, or labyrinth
online search problems
• Agents are assumed to know only
– Actions(s): returns a list of actions allowed in states
– c(s,a,s’): this step-cost cannot be used until the agent knows that
s’ is the outcome
– Goal-test(s)
• The agent cannot access the successors of a state
except by actually trying all the actions in that state
• Assumptions
– The agent can recognize a state that it has visited before
– Actions are deterministic
– Optionally, an admissible heuristic function
online search problems
• If some actions are irreversible, the agent may reach a
dead end
• If some goal state is reachable from every reachable
state, the state space is “safely explorable”
online search agents
• Online algorithm can expand only a node that it
physically occupies
– Offline algorithms can expand any node in fringe
• Same principle as DFS
Online DFS
function ONLINE_DFS-AGENT(s’) return an action
input: s’, a percept identifying current state
static: result, a table of the next state, indexed by action and state, initially empty
unexplored, a stack that lists, for each visited state, the action not yet tried
unbacktracked, a stack that lists, for each visited state, the predecessor states
to which the agent has not yet backtracked
s, a, the previous state and action, initially null
if GOAL-TEST(s’) then return stop
if s’ is a new state then unexplored[s’] ACTIONS(s’)
if s is not null then do
result[a,s] s’
add s to the front of unbackedtracked[s’]
if unexplored[s’] is empty then
if unbacktracked[s’] is empty then return stop
else a an action b such that result[b, s’]=POP(unbacktracked[s’])
else a POP(unexplored[s’])
s s’
return a
Online DFS, example
•
•
•
•
s’
Assume maze problem on 3x3
grid.
s’ = (1,1) is initial state
result, unexplored (UX),
unbacktracked (UB), … are empty
s, a are also empty
Online DFS, example
•
GOAL-TEST((1,1))?
– s’ != G thus false
s’=(1,1)
•
(1,1) a new state?
– True
– ACTION((1,1)) → UX[(1,1)]
•
•
{RIGHT,UP}
s is null?
– True (initially)
•
UX[(1,1)] empty?
– False
•
s’
POP(UX[(1,1)]) → a
– a=UP
•
•
s = (1,1)
Return a
Online DFS, example
•
s’=(1,2)
GOAL-TEST((1,2))?
– s’ != G thus false
•
(1,2) a new state?
– True
– ACTION((1,2)) → UX[(1,2)]
•
•
s is null?
– false (s=(1,1))
– result[UP,(1,1)] ← (1,2)
– UB[(1,2)]={(1,1)}
s’
s
{DOWN}
•
UX[(1,2)] empty?
– False
•
•
a=DOWN, s=(1,2)
return a
Online DFS, example
•
s’=(1,1)
GOAL-TEST((1,1))?
– s’ != G thus false
•
(1,1) a new state?
– false
•
s
s is null?
– false (s=(1,2))
– result[DOWN,(1,2)] ← (1,1)
– UB[(1,1)] = {(1,2)}
•
UX[(1,1)] empty?
– False
s’
•
•
a=RIGHT, s=(1,1)
return a
Online DFS, example
•
s’=(2,1)
GOAL-TEST((2,1))?
– s’ != G thus false
•
(2,1) a new state?
– True, UX[(2,1)]={RIGHT,UP,LEFT}
•
s is null?
– false (s=(1,1))
– result[RIGHT,(1,1)] ← (2,1)
– UB[(2,1)]={(1,1)}
•
UX[(2,1)] empty?
– False
s
s’
•
•
a=LEFT, s=(2,1)
return a
Online DFS, example
•
s’=(1,1)
GOAL-TEST((1,1))?
– s’ != G thus false
•
(1,1) a new state?
– false
•
s is null?
– false (s=(2,1))
– result[LEFT,(2,1)] ← (1,1)
– UB[(1,1)]={(2,1),(1,2)}
•
s’
s
UX[(1,1)] empty?
– True
– UB[(1,1)] empty? False
•
a = an action b such that result[b,(1,1)]=(2,1)
– b=RIGHT
• a=RIGHT, s=(1,1)
• Return a
• And so on…
Online DFS
• Worst case each node is visited
twice.
• An agent can go on a long walk
even when it is close to the
solution.
• An online iterative deepening
approach solves this problem.
• Online DFS works only when
actions are reversible.
Online local search
• Hill-climbing is already online
– One state is stored.
• Bad performance due to local maxima
– Random restarts impossible.
• Solution1: Random walk introduces exploration
– Selects one of actions at random, preference to not-yet-tried action
– can produce exponentially many steps
Online local search
•
Solution 2: Add memory to hill climber
– Store current best estimate H(s) of cost to reach goal
– H(s) is initially the heuristic estimate h(s)
– Afterward updated with experience (see below)
•
Learning real-time A* (LRTA*)
The current
position of agent
Learning real-time A*(LRTA*)
function LRTA*-COST(s,a,s’,H) return an cost estimate
if s’ is undefined the return h(s)
else return c(s,a,s’) + H[s’]
function LRTA*-AGENT(s’) return an action
input: s’, a percept identifying current state
static: result, a table of next state, indexed by action and state, initially empty
H, a table of cost estimates indexed by state, initially empty
s, a, the previous state and action, initially null
if GOAL-TEST(s’) then return stop
if s’ is a new state (not in H) then H[s’] h(s’)
unless s is null
result[a,s] s’
H[s] min LRTA*-COST(s,b,result[b,s],H)
b ACTIONS(s)
a an action b in ACTIONS(s’) that minimizes LRTA*-COST(s’,b,result[b,s’],H)
s s’
return a
Outline
• Ch 4. informed search
• Ch 6. adversarial search
– Optimal decisions
– α-β pruning
– Imperfect, real-time decisions
Games vs. search problems
• Problem solving agent is not alone any more
– Multiagent, conflict
• Default: deterministic, turn-taking, two-player,
zero sum game of perfect information
– Perfect info. vs. imperfect, or probability
• "Unpredictable" opponent specifying a move
for every possible opponent reply
•
• Time limits unlikely to find goal, must
approximate
* Environments
with very many agents are best viewed as economies rather than games
•
Game formalization
• Initial state
• A successor function
– Returns a list of (move, state) paris
• Terminal test
– Terminal states
• Utility function (or objective function)
– A numeric value for the terminal states
• Game tree
– The state space
Tic-tac-toe: Game tree
(2-player, deterministic, turns)
Minimax
• Perfect play for deterministic games: optimal strategy
•
• Idea: choose move to position with highest minimax value
= best achievable payoff against best play
•
• E.g., 2-ply game: only two half-moves
•
Minimax algorithm
Problem of minimax search
• Number of games states is exponential to the
number of moves.
– Solution: Do not examine every node
– ==> Alpha-beta pruning
• Remove branches that do not influence final decision
• Revisit example …
Alpha-Beta Example
Do DF-search until first leaf
Range of possible values
[-∞,+∞]
[-∞, +∞]
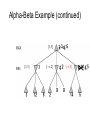
Alpha-Beta Example (continued)
[-∞,+∞]
[-∞,3]
Alpha-Beta Example (continued)
[-∞,+∞]
[-∞,3]
Alpha-Beta Example (continued)
[3,+∞]
[3,3]
Alpha-Beta Example (continued)
[3,+∞]
This node is worse
for MAX
[3,3]
[-∞,2]
Alpha-Beta Example (continued)
[3,14]
[3,3]
[-∞,2]
,
[-∞,14]
Alpha-Beta Example (continued)
[3,5]
[3,3]
[−∞,2]
,
[-∞,5]
Alpha-Beta Example (continued)
[3,3]
[3,3]
[−∞,2]
[2,2]
Alpha-Beta Example (continued)
[3,3]
[3,3]
[-∞,2]
[2,2]
Properties of α-β
• Pruning does not affect final result
•
• Good move ordering improves effectiveness of pruning
•
• With "perfect ordering," time complexity = O(bm/2)
doubles depth of search
Why is it called α-β?
• α is the value of the
best (i.e., highestvalue) choice found
so far at any choice
point along the path
for max
•
• If v is worse than α,
max will avoid it
•
prune that branch
The α-β pruning algorithm
The α-β pruning algorithm
Resource limits
• In reality, imperfect and real-time decisions are
required
– Suppose we have 100 secs, explore 104 nodes/sec
106 nodes per move
–
• Standard approach:
•
– cutoff test:
• e.g., depth limit
•
– evaluation function
Evaluation functions
• For chess, typically linear weighted sum of features
Eval(s) = w1 f1(s) + w2 f2(s) + … + wn fn(s)
• e.g., w1 = 9 for queen, w2 = 5 for rook, … wn = 1 for pawn
f1(s) = (number of white queens) – (number of black
queens), etc.
Cutting off search
MinimaxCutoff is identical to MinimaxValue except
1. Terminal-Test is replaced by Cutoff-Test
2. Utility is replaced by Eval
3.
Does it work in practice?
bm = 106, b=35 m ≈ 4
4-ply lookahead is a hopeless chess player!
–
4-ply ≈ human novice
Games that include chance
chance nodes
•
•
Backgammon: move all one’s pieces off the board
Branches leading from each chance node denote the possible dice rolls
– Labeled with roll and the probability
Games that include chance
• [1,1], [6,6] chance 1/36, all other chance 1/18
•
•
Possible moves (5-10,5-11), (5-11,19-24),(5-10,10-16) and (5-11,11-16)
Cannot calculate definite minimax value, only expected value
Expected minimax value
EXPECTED-MINIMAX-VALUE(n) =
UTILITY(n)
If n is a terminal
maxs successors(n) MINIMAX-VALUE(s)
If n is a max node
mins successors(n) MINIMAX-VALUE(s)
If n is a max node
s successors(n) P(s) * EXPECTEDMINIMAX(s)
If n is a chance node
These equations can be backed-up recursively all the way
to the root of the game tree.
Position evaluation with chance nodes
•
•
•
•
Left, A1 is best
Right, A2 is best
Outcome of evaluation function (hence the agent behavior) may change
when values are scaled differently.
Behavior is preserved only by a positive linear transformation of EVAL.