Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Presentation in
TUDelft
范正洁
Fan Zhengjie
Personal
Introduction
MSc-thesis
PhD
Plan
Work
Personal
Introduction
MSc-thesis
PhD
Plan
Work
Personal Introduction
I come from Bengbu, Anhui, China
Education
B.E.(major) of Computer Science, Anhui
University, China, 2005
B.A.(minor) of English, Anhui University,
China, 2005
M.E. of Applied Computer Technology,
University of Science and Technology of
China, China, 2008
Research Interests
Artificial Intelligence and its application on
the web
Semantic Web
Semantic Web Service
Multi-Agent System
Ontology
Data Mining and Machine Learning
Hobby
Classical music
Singing
Yoga
Playing the accordion
Personal
Introduction
MSc-thesis
PhD
Plan
Work
MSc-thesis Work
Two ranking methods in Discovery process
of Semantic Web Service.
RASC
Algorithm
RAUP Algorithm
Background
Two main directions of web improvement:
Semantic Web: adding semantic on the
web
Web Service: providing automatic services
online
Semantic Web Service: combining
technologies of both Semantic Web and
Web Service to fulfill automatic computation
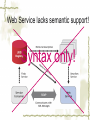
Web Service lacks semantic support!
Syntax only!
Discovery
Discovery is a very important process of SWS,
which consists of two steps:
Matching: comparing the function web user
wants with the one web services provide;
Ranking: putting all matched web services
into an ordered list on certain criteria.
Ranking should be worked on.
Ranking criteria
Serving Capability
User Preference
Service Quality
RASC Algorithm
Core idea:
“rewriting”: meeting as much as web user’s
output, asking as fewer as web user’s input
Comparison on output—1st dimension ranking
criteria
Comparison on input—2nd dimension ranking
criteria
RASC
Algorithm:
Output comparison:
Input comparison:
Ranking:
Example
Output
relationship:
Input relationship:
Ordered list:
Discussion
Time complexity is O(n2),
Space complexity is O(n).
Comparing input and output seperately
Adding input comparison as part of
ranking criteria, which reflects the
interation requirement of web user.
Experiment
Tools:
Logic reasoner
RACER
Coding language
Java
Server with
processor AMD
4000+,memory 2G
Discussion:
Ranking step
costs quite a few
executing time
RAUP Algorithm
Core ideas:
Drawing preference information by
interacting with web users
Putting on relative weights on properties and
values
Ranking on sum of weights
Algorithm
1. Selecting pairs of web services randomly and sending
them to web user to compare;
2. Classifying web services into two web service sets
according to users' answers;
3. Extracting user preference from two web service sets by
Apriori Algorithm;
4. Sending the drawn preference to the user to check;
5. Quantifying the checked preference by setting weights;
6. Computing each web service's sum of weights and
ranking them into an ordered list.
Example
web services:
Selected pairs:
User preference:
P1=Q11, P3=Q31
Classification: preferred web services set is {S2, S3, S1, S5, S5},
non-preferred web services set is {S1, S4, S3, S2, S4,}.
Preferred set:
Frequent
properties:
Non-preferred set:
∴no preference on properties
Frequent
values:
Preferred set:
Non-preferred set:
Case 1:
Case 2:
After user checking, Case 1 is the best choice.
Weights of properties:
Weights of values:
∵
set
∴
Sum of weights:
Result of ranking:
Discussion
Time complexity is O(r2),
Space complexity is O(r).
Drawing preference information by
interaction
Weighing properties and values on their
contribution on discovery
Fulfilling individual oriented.
Experiment:
Tools:
Coding language Java
Server with processor
AMD 4000+, memory
2G
Discussion:
Low executing time
Drawing majority
preference
Personal
Introduction
MSc-thesis
PhD
Plan
Work
Semantic Interoperability
Three kinds of data interoperability:
System interoperability
Syntax and structure interoperability
Semantic interoperability:
heterogeneity
Solution
Ontology
Process
Mapping
Mapping
Building a basic domain ontology
Merging other ontologies into the basic
domain ontology
Computing the relationship between two
processes based on the same ontology
Thank you!