Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
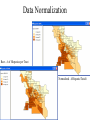
Exploratory Spatial Data Analysis (ESDA) Analysis through Visualization Data Normalization • Values (attributes) by themselves are sometimes misleading. • Normalization refers to the division of multiple sets of data by a common variable in order to negate that variable's effect on the data. • Normalization can help to compare samples. • Example: The number of people in a county does not tell us about the relative density of the people. What we may want is the # of people per area. Density = (# of people in county / county area) Data Normalizatoin Approaches • Density – divide count by area • Divide an area –based count variable by another area based count variable X = Area on wheat / Total area in crops X = higher ratio indicates that wheat is more important • Compute ratio of two count variables X = $ of Wheat Sold / $ of all Crops Sold X = higher ratio indicates that wheat contributed more income to area • Compute summary numerical measures for each unit (sum, mean, SD, etc.) Data Normalization Raw - # of Hispanics per Tract Normalized - #Hispanic/Total# Mapping Common ESDA Methods • Quantile - Each class contains an equal number of features. • Percentile - Sort values in numerical order, compute % of total observations. Note that the Median = 50% quartile • Standard Deviation – good for normal distribution • Box Map – Shows outliers as the function of quartiles. IQR = Q75 – Q25 Lower Outlier = Q25 – Hinge * IQR Upper Outlier = Q75 + Hinge * IQR Mapping (%Hispanic) Exploration of Data • • • • Histogram - examine distribution Scatter Plot - examine correlation between variables Box Plot - compare distribution between variables Parallel Coordinate Plot - examine relation between variables Box Plots and Quantile Spatial Autocorrelation • First law of geography: “everything is related to everything else, but near things are more related than distant things” – Waldo Tobler • Spatial Autocorrelation – correlation of a variable with itself through space. – If there is any systematic pattern in the spatial distribution of a variable, it is said to be spatially autocorrelated. – If nearby or neighboring areas are more alike, this is positive spatial autocorrelation. – Negative autocorrelation describes patterns in which neighboring areas are unlike. – Random patterns exhibit no spatial autocorrelation. Why spatial autocorrelation is important • Most statistics are based on the assumption that the values of observations in each sample are independent of one another • Positive spatial autocorrelation may violate this, if the samples were taken from nearby areas • Goals of spatial autocorrelation – Measure the strength of spatial autocorrelation in a map – test the assumption of independence or randomness Moran’s I • One of the oldest indicators of spatial autocorrelation (Moran, 1950). Still a defacto standard for determining spatial autocorrelation. • Applied to zones or points with continuous variables associated with them. • Compares the value of the variable at any one location with the value at all other locations. Moran’s I I N i j Wi , j ( X i X )( X j X ) (i j Wi , j )i ( X i X ) 2 Where N is the number of cases Xi is the variable value at a particular location Xj is the variable value at another location X-bar is the mean of the variable Wij is a weight applied to the comparison between location i and location j. Weights are based either on distance or adjacency.