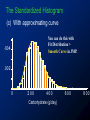
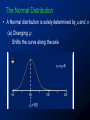
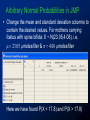
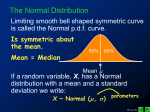
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Problem: Diagnosing Spina Bifida The procedure of amniocentesis involves drawing a sample of the amniotic fluid that surrounds an unborn child in its mother’s womb. High concentration of alpha fetoprotein can indicate the condition spina bifida. Concentration of alpha fetoprotein tends to increase with the size of the foetus. Amniocentesis results in miscarriage for 1%. Preliminary tests involve measuring the level of alpha fetoprotein in the mother’s urine. Problem: Diagnosing Spina Bifida For mothers with normal foetuses, the mean level of alpha fetoprotein is 15.73 moles/litre with a standard deviation of 0.72 moles/litre. For mothers carrying foetuses with spina bifida, the mean is 23.05 and the standard deviation is 4.08. In both groups the distribution of alpha fetoprotein appears to be approximately Normally distributed. 15.73 23.05 Problem: Diagnosing Spina Bifida To operate a diagnostic test for spina bifida, set a threshold concentration of alpha fetoprotein, T, say. If the alpha fetoprotein level is below T, then the foetus is diagnosed as not having spina bifida. If the level is above T, then further testing is required. Problem: Diagnosing Spina Bifida If T was set at 17.80 moles/litre: What is the probability that a foetus with spina bifida is correctly diagnosed? What is the probability that a foetus not suffering from spina bifida is correctly diagnosed? If they wanted to ensure that 99% of foetuses with spina bifida were correctly diagnosed, at what level should they set T ? What are the implications of setting T at this level? Continuous Random Variables If a random variable, X, can take any value in some interval of the real line it is called a continuous random variable. E.g. Hg levels, height, weight, alpha fetoprotein concentration, cell radius, etc. (i.e. usually quantities that are ‘measurements’ ) The Standardized Histogram Example: Dietary Carbohydrate in the Workforce The average daily intake of carbohydrate in the diet of 5929 people. The Standardized Histogram (a) The histogram of the data shows the carbohydrate intake: .004 .002 .000 0 200 400 600 Carbohydrate (g/day) 800 * Is unimodal (modal class 200 – 225 g/day) The Standardized Histogram (a) The histogram of the data shows the carbohydrate intake: .004 .002 .000 0 200 400 600 Carbohydrate (g/day) 800 * Skewed to larger values (skewed right) The Standardized Histogram (a) The histogram of the data shows the carbohydrate intake: .004 .002 .000 0 200 400 600 Carbohydrate (g/day) 800 * Has huge variability (highest consumers more than 10 times that of lowest consumers) The Standardized Histogram (b) Area between a = 225 and b = 375 shaded Shaded area = 0.483 (Corresponds to 48.3% of observations) .004 .002 .000 0 2 25 600 375 800 The Standardized Histogram Rel. Freq/Width (b) The standardized histogram adjusts the height of the rectangle or bar to relative freq. or proportion divided by interval width so that Area = Estimated Probability Shaded area = 0.483 (Corresponds to 48.3% of observations) .004 .002 .000 0 225 375 60 0 80 0 The Standardized Histogram Rel. Freq/Width (b) i.e. The area of the ith rectangle tells us what proportion of the data lie in the ith class interval. Shaded area = 0.483 (Corresponds to 48.3% of observations) .004 .002 .000 0 225 375 60 0 80 0 The Standardized Histogram For a standardized histogram: The vertical scale is : Relative frequency / interval width (density scale) Total area under the histogram = 1 The proportion of the data between a and b is the area “under” the histogram between a and b. The Standardized Histogram (c) With approximating curve You can do this with Fit Distribution > Smooth Curve in JMP. . 004 . 002 0 200 400 Carbohydrate (g/day) 600 800 The Standardized Histogram (d) Area between a = 225 and b = 375 shaded Shaded area = .486 .04 (cf. area = .483 for histogram) .002 0 225 375 600 800 This area is calculated to be 0.486 and is very close to the proportion of people who had carbohydrate intake of between 225 and 375 g/day. Radius of Maliginant Tumor Cells In JMP select Histogram Options > Density Axis to create a standardized histogram The histogram on the left is for cell radii of malignant tumor fine needle aspirations in the breast cancer study from your 2nd assignment. X = radius of a randomly selected malignant tumor cell We estimate that, P(14 < X < 15) = .10 or a 10% chance AFP Levels in Spina Bifida Cases In JMP select Histogram Options > Density Axis to create a standardized histogram The histogram on the left is AFP levels found in the urine of mothers carrying a fetus with spina bifida. X = AFP level of random select mother carrying fetus with spina bifida. We estimate that, P(22.5 < X < 25) = 2.5 X .10 = .25 or a 25% chance Smooth Density Curves Take a standardized histogram, decrease the width of the class intervals and increase the number of observations. Then the top of the histogram tends to a smooth curve. Histogram Smooth Density Curves as sample size increases! (AFP Levels) n = 500 n = 100 n = 10,000 n = 100,000 n = 1,000,000 0.08 0.05 0.03 10 20 30 40 Density 0.10 Properties of the Probability Density Function (p.d.f.) 1. f(x) 0 (i.e. the p.d.f. curve stays above the x-axis) 2. P(a X b) = area from a to b beneath the p.d.f curve 3. Area under the p.d.f. curve = 1 Endpoints of Intervals For a continuous random variable, X, endpoints of intervals are unimportant. P(a X b) = P(a < X b) = P(a X < b) = P(a < X < b) = area from a to b between the p.d.f. curve and the x-axis. (Inclusion or exclusion of the endpoints will not change the area.) The Normal Distribution Limiting smooth bell shaped symmetric curve is called the Normal p.d.f. curve. Is symmetric about the mean. Mean = Median 50% 50% Mean If a random variable, X, has a Normal distribution with a mean and a standard deviation we write: X ~ Normal ( , ) parameters The Normal Distribution • The Normal distribution is important because: – it fits a lot of data reasonably well; – it can be used to approximate other distributions; e.g. the binomial distribution – it is important assumption made about the distributional shape of continuous variables we are working with when using parametric tools for statistical inference (e.g. t-Tests & F-Tests). The Normal Distribution • A Normal distribution is solely determined by and . (a) Changing Shifts the curve along the axis The Normal Distribution A Normal distribution is solely determined by and . (b) Increasing Increases the spread and flattens the curve Spina Bifida Example Let X be the AFP level found in the urine of mother carrying a foetus with spina bifida. We will assume that the AFP level is normally distributed with a mean of = 23.05 moles/L and a standard deviation of = 4.08 moles/L . AFP Levels for Mothers Carrying Spina Bifida Foetus Spina Bifida Example (Empirical Rule) Approximately 68 % of mothers in this population will have a AFP levels within 1 standard deviation of the mean. i.e., approximately 68 % of mothers in this population will have AFP levels between 23.05 – 4.08 and 23.05 + 4.08 = between 18.97 and 27.13 Spina Bifida Example (Empirical Rule) Approximately 95 % of mothers in this population will have a AFP levels within 2 standard deviation of the mean. i.e., approximately 95 % of mothers in this population will have AFP levels between 23.05 - 2 4.08 and 23.05 + 2 4.08 = between 14.89 and 31.21 Spina Bifida Example (Empirical Rule) Approximately 99.73 % of mothers in this population will have a AFP levels within 3 standard deviation of the mean. i.e., approximately 99.73% of mothers in this population will have AFP levels between 23.05 - 3 4.08 and 23.05 - 3 4.08 = between 10.81 and 35.29 The Normal Distribution For the Normal Distribution: A random observation has approximately: – 68% chance of falling within 1 of ; – 95% chance of falling within 2 of ; – 99.7% chance of falling within 3 of . Or: In a Normal distribution, approximately: – 68% of observations are within 1 of ; – 95% of observations are within 2 of ; – 99.7% of observations are within 3 of . The Normal Distribution Probabilities and numbers of standard deviations Shaded area = 0.683 - + 68% chance of falling between - and + Shaded area = 0.954 - 2 + 2 95% chance of falling between - 2 and + 2 Shaded area = 0.997 - 3 + 3 99.7% chance of falling between - 3 and + 3 Problem: Diagnosing Spina Bifida For mothers with normal foetuses, the mean level of alpha fetoprotein is 15.73 moles/litre with a standard deviation of 0.72 moles/litre. For mothers carrying foetuses with spina bifida, the mean is 23.05 and the standard deviation is 4.08. In both groups the distribution of alpha fetoprotein appears to be approximately Normally distributed. 15.73 23.05 Given this For example weinformation might like to want>to17.8) be able or to find:we P(X find probabilities P(19 <with X < these 25) etc… associated distributions. for either group. Obtaining Probabilities Normal distribution probabilities can be obtained from all statistical packages by giving the mean and standard deviation of the distribution. – Most tables in books give the value of P(X x). – i.e., cumulative or lower tail probabilities. OR Area = P(X x) x Problem: There are infinitely many normal distributions we might be interested in • Because there are infinitely many values for and that we might be interested in we would need a book infinitely thick to contain all the possible tables we might need. • Even for our motivating example we would need to two separate tables to find probabilities for mothers with healthy fetuses and another for mothers carrying fetus with spina bifida. • We need to have “standard” normal table that allows us to easily find probabilities for all situations. Standardization and the Standard Normal Distribution If X ~ N(,) then if we define a new random variable Z as, X- Z = _______ ~ N(0,1), i.e. a normal distribution with mean 0 and standard deviation 1. We say Z has a standard normal distribution. This process is called standardization. Obtaining Probabilities Basic method for obtaining probabilities 1. Sketch a Normal curve, marking on the mean and values of interest. 2. Shade the area under the curve corresponding to the required probability. 3. Convert all values to their z-scores 4. Obtain the desired probability using a standard normal table or better yet use JMP. Standard Normal Distribution • a) P(Z > 2.25) 0 • b) P(Z < 1.28) 0 Standard Normal Distribution • c) P(Z > .50) 0 • d) P(Z <-2.33) 0 Standard Normal Distribution e) P(-1.96 < Z < 1.96) 0 0 0 Standard Normal Distribution • f) Find z so that P(Z < z) = .95, i.e. what is the 95th percentile of the standard normal distribution? 0 Original problem: Diagnosing Spina Bifida 15.73 23.05 Recall: • For normal foetuses =15.73, = 0.72 and for foetuses with spina bifida = 23.05 and = 4.08. • Assume the threshold for detecting spina bifida is set at 17.8. – (A foetus would be diagnosed as not having spina bifida if the fetoprotein level is below 17.8) Original problem: Diagnosing Spina Bifida 15.73 23.05 a) What is the probability that a foetus not suffering from spina bifida is correctly diagnosed? Therefore 99.80% of healthy foetuses Let X be level of fetoprotein in normal foetus will be diagnosed correctly. This is X ~ Normal (15.73, 0.72) What is P(X < 17.8)? called the specificity of the test, i.e. = (17.8for – 15.73)/.72 P(X < 17.8) = z-score P(Z < z-score 17.8) P(T |D ). = 2.07/.72 = 2.88 P(X < 17.8) = P(Z < 2.88) = .9980 0 15.73 2.88 17.8 Original problem: Diagnosing Spina Bifida 15.73 23.05 b) What is the probability that a foetus with spina bifida is correctly diagnosed? Let Y be the of fetoprotein spina Therefore thelevel probability that ina afoetus bifida foetus. Y ~ Normal (23.05, 4.08) with spina bifida is correctly diagnosed P(Y > 17.8) = P(Z > z-score for Y = 17.8) is .901 or 90.1% of foetuses with spina P(Z>-1.29) =z-score 1-P(Z <= -1.29) (17.8 – 23.05)/4.08 bifida will= be This is called 1 – detected. 0.099 = -5.25/4.08 = -1.29+ = 0.901 the sensitivity of the test, i.e. P(T |D+). 17.8 -1.29 023.05 Original problem: Diagnosing Spina Bifida 15.73 23.05 If they wanted to ensure that 99% of foetuses with spina bifida were correctly diagnosed, at what level should they set T ? Find a value T so that if First theensures z-score associated with T by T = find 13.54 From Normal Table we 99% find of foetuses finding z~ so that Xspina Normal (23.05, 4.08) with bifida will be identified. P(Z < -2.33) = .0100 thus P(Z < z) = .0100 TAgain =we + xhave z probability = 23.05 – 4.08 x 2.33 the = 13.54 will this is called sensitivity. P(X > T) = .9900 or P(X < T) = .0100 Standard Normal Probabilities in JMP • Normal Probability Calculator in JMP from Tutorials section of course website. • Here it is ready to calculate probabilities for the standard normal distribution. ( = 0, = 1) Arbitrary Normal Probabilities in JMP • Change the mean and standard deviation columns to contain the desired values. For mothers carrying foetus with spina bifida: X ~ N(23.05,4.08), i.e. = 23.05 moles/liter & = 4.08 moles/liter Here we have found P(X < 17.8) and P(X > 17.8)