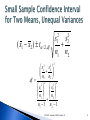Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Lecture 22 Dustin Lueker Similar to testing one proportion Hypotheses are set up like two sample mean test ◦ H0:p1-p2=0 Same as H0: p1=p2 Test Statistic z ( pˆ 1 pˆ 2 ) ( p1 p2 ) pˆ 1 (1 pˆ 1 ) pˆ 2 (1 pˆ 2 ) n1 n2 STA 291 Summer 2008 Lecture 21 2 Hypothesis involves 2 parameters from 2 populations ◦ Test statistic is different Involves 2 large samples (both samples at least 30) One from each population H0: μ1-μ2=0 ◦ Same as H0: μ1=μ2 ◦ Test statistic z ( x1 x2 ) ( 1 2 ) 2 1 2 2 s s n1 n2 STA 291 Summer 2008 Lecture 21 3 Used when comparing means of two samples where at least one of them is less than 30 ◦ Normal population distribution is assumed for both samples Equal Variances ◦ Both groups have the same variability Unequal Variances 2 1 2 2 ◦ Both groups may not have the same variability 2 1 2 2 STA 291 Summer 2008 Lecture 21 4 Test Statistic t ( x1 x2 ) ( 1 2 ) (n1 1) s (n2 1) s n1 n2 2 2 1 2 2 1 1 n1 n2 ◦ Degrees of freedom n1+n2-2 STA 291 Summer 2008 Lecture 21 5 ( x1 x2 ) t / 2,n1 n2 2 (n1 1) s (n2 1) s n1 n2 2 2 1 2 2 1 1 n1 n2 ◦ Degrees of freedom n1+n2-2 STA 291 Summer 2008 Lecture 21 6 Test statistic t ( x1 x2 ) ( 1 2 ) 2 1 2 2 s s n1 n2 Degrees of freedom 2 s s n1 n2 df 2 2 2 2 s1 s2 n1 n2 n1 1 n2 1 2 1 STA 291 Summer 2008 Lecture 21 2 2 7 2 1 2 2 s s n1 n2 ( x1 x2 ) t / 2,df 2 s s n1 n2 df 2 2 2 2 s1 s2 n1 n2 n1 1 n2 1 2 1 2 2 STA 291 Summer 2008 Lecture 21 8 How to choose between Method 1 and Method 2? ◦ Method 2 is always safer to use ◦ Definitely use Method 2 If one standard deviation is at least twice the other If the standard deviation is larger for the sample with the smaller sample size ◦ Usually, both methods yield similar conclusions STA 291 Summer 2008 Lecture 21 9 Comparing dependent means ◦ Example Special exam preparation for STA 291 students Choose n=10 pairs of students such that the students matched in any given pair are very similar given previous exam/quiz results For each pair, one of the students is randomly selected for the special preparation (group 1) The other student in the pair receives normal instruction (group 2) STA 291 Summer 2008 Lecture 21 10 “Matches Pairs” plan ◦ Each sample (group 1 and group 2) has the same number of observations ◦ Each observation in one sample ‘pairs’ with an observation in the other sample ◦ For the ith pair, let Di = Score of student receiving special preparation – score of student receiving normal instruction STA 291 Summer 2008 Lecture 21 11 The sample mean of the difference scores is an estimator for the difference between the population means xD n D i 1 i n D1 D2 Dn n We can now use exactly the same methods as for one sample ◦ Replace Xi by Di STA 291 Summer 2008 Lecture 21 12 Small sample confidence interval xD tn 1 Note: sD n i 1 sD n ( Di xD ) 2 n 1 ◦ When n is large (greater than 30), we can use the zscores instead of the t-scores STA 291 Summer 2008 Lecture 21 13 Small sample test statistic for testing difference in the population means xD D t sD n ◦ For small n, use the t-distribution with df=n-1 ◦ For large n, use the normal distribution instead (z value) STA 291 Summer 2008 Lecture 21 14 Ten college freshman take a math aptitude test both before and after undergoing an intensive training course Then the scores for each student are paired, as in the following table Student 1 2 3 4 5 6 7 Before 60 73 42 88 66 77 90 63 55 96 After 70 80 40 94 79 86 93 71 70 97 STA 291 Summer 2008 Lecture 21 8 9 10 15 STA 291 Summer 2008 Lecture 21 16 Student 1 2 3 4 5 6 7 8 9 10 Before 60 73 42 88 66 77 90 63 55 96 After 70 80 40 94 79 86 93 71 70 97 Compare the mean scores after and before the training course by ◦ Finding the difference of the sample means ◦ Find the mean of the difference scores ◦ Compare Calculate and interpret the p-value for testing whether the mean change equals 0 Compare the mean scores before and after the training course by constructing and interpreting a 90% confidence interval for the population mean difference STA 291 Summer 2008 Lecture 21 17 Output from Statistical Software Package SAS N Mean Std Deviation 10 7 5.24933858 Tests for Location: Mu0=0 Test -Statistic- -----p Value------ Student's t Sign Signed Rank t M S Pr > |t| Pr >= |M| Pr >= |S| 4.216901 4 25.5 STA 291 Summer 2008 Lecture 21 0.0022 0.0215 0.0059 18 Variability in the difference scores may be less than the variability in the original scores ◦ This happens when the scores in the two samples are strongly associated ◦ Subjects who score high before the intensive training also dent to score high after the intensive training Thus these high scores aren’t raising the variability for each individual sample STA 291 Summer 2008 Lecture 21 19