Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
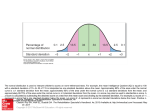
Unit 2 (F): Statistics in Psychological Research: Measures of Central Tendency Mr. Debes A.P. Psychology Statistics in Psychology Statistics: The collection, classification, analysis, and interpretation of numerical psychological data Descriptive Statistics: Describes collected data Frequency Distribution: Bar Graph Histogram Statistics in Psychology Types of Psychological Data: Nominal: Categorical Non-numerical Bar graph E.g. Favorite ice cream flavor Ordinal: Ordered Non-numerical Bar graph E.g. 1st place, 2nd place, 3rd place Statistics in Psychology Types of Psychological Data: Interval: Equal interval between points; no true zero point Numerical; can compute mean Histogram E.g. Degrees in Fahrenheit Ratio: Equal interval between points; true zero point Numerical; can compute mean Histogram E.g. Height/weight Statistics in Psychology Statistics in Psychology Inferential Statistics Allow us to determine if results can be generalized to a larger population. Well reasoned inferences about the population in question Representative sample is very important Random sample-everyone in the target population has an equal chance of being selected for the sample Sample size-the larger the sample size, the better, but there are trade-offs in time & money when it comes to sample size Statistics in Psychology Statistical Significance How likely it is than an obtained result occurred by chance A level of significance is selected prior to conducting statistical analysis. Traditionally, either the 0.05 level (sometimes called the 5% level) or the 0.01 level (1% level) is used. If the probability is less than or equal to the significance level, then the outcome is said to be statistically significant. The 0.01 level is more conservative than the 0.05 level. Measures of Central Tendency Mean: The arithmetic average of a distribution Obtained by adding all scores together, and dividing by the number of scores Median: The middle score of a distribution Half of the scores are above it and half are below it Mode: The most frequently occurring score(s) in a distribution Distributions Distribution: the way scores are distributed (spread out) around the mean score Normal Distribution (normal curve/bell curve): Symmetrical, Bell-shaped distribution Mean, Median, Mode all are the same Distributions Skewed Distribution: Positively skewed; “Skewed to the Right”-scores pull the mean toward the higher end of the scores Negatively skewed; “Skewed to the Left”-scores pull the mean toward the lower end of the scores Distributions Positively Skewed Distribution Measures of Variation Range: The difference between the highest and lowest scores in a distribution Standard Deviation: A computed measure of how much scores vary around the mean Measures of Variation Calculating standard deviation: For your set of data, calculate the mean. Subtract the mean from each item of data (half of your outcomes will be negative). This is the DEVIATION of each value from the mean. Square each deviation. Add all of the squares from step 3, and divide by the number of items in the data set. This is the VARIANCE. Take the square root of the variance. This is the STANDARD DEVIATION. Measures of Variation Data Set 1: 44, 45, 47, 48, 49, 51, 52, 53, 55, 56 1) Calculate mean: 500/10=50 2) Subtract mean from each data point: -6, -5, -3, -2, -1, 1, 2, 3, 5, 6 (these are the individual deviations) 3) Square each individual deviation: 36, 25, 9, 4, 1, 1, 4, 9, 25, 36 4) Add all squares, then divide by items in the data set: 150/10=15 (VARIANCE) 5) Find the square root of the variance: 3.87 (STANDARD DEVIATION) Data Set 2: 2, 3 , 5, 7, 9, 17, 48, 49, 137, 223 1) Calculate mean: 500/10=50 2) Subtract mean from each data point: -48, -47, -45, -43, -41, -33, -2, -1, 87, 173 (these are the individual deviations) 3) Square each individual deviation: 2304, 2209, 2025, 1849, 1681, 1089, 4, 1, 7569, 29929 4) Add all squares, then divide by items in the data set: 48660/10=4866(VARIANCE) 5) Find the square root of the variance: 69.76 (STANDARD DEVIATION) Measures of Variation Usefulness of Standard deviation: Standard deviation gives a better gauge of whether a set of scores are packed closely together, or more widely dispersed. The higher the standard deviation, the less similar the scores are. In nature, large numbers of data often form a bell-shaped distribution, called a “normal curve.” In a normal curve, most cases fall near the mean, and fewer cases fall near the extremes Normal Distribution Z-scores A z-score is the number of standard deviations a score is from the mean If a Z-Score: Has a value of 0, it is equal to the group mean. Is equal to +1, it is 1 Standard Deviation above the mean. Is equal to -2, it is 2 Standard Deviations below the mean. Z-Scores can help us understand: How typical a particular score is within bunch of scores. If data are normally distributed, approximately 95% of the data should have Z-score between -2 and +2. Z-scores that do not fall within this range may be less typical of the data in a bunch of scores. Measures of Variation Homework Explain the difference between the following types of data: Nominal, Ordinal, Interval, Ratio What is a normal distribution? What is the difference between a positively and negatively-skewed distribution? Explain the difference between the measures of variation: Range & Standard Deviation What is a Z-score? How is it computed?