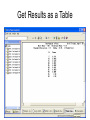
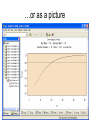
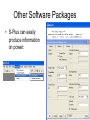
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Making Inferences, AKA Hypothesis Testing Assignment 2 and 3 • You should have received feedback on assignment 2. – Great job everyone. • Please send everything to both me and Lamiya. • Mofiz Haque please stop by I have a question about your email address. • Assignment 3 is assigned today. So Far • You know how to describe variables: – Conceptually with a taxonomy – Graphically – Numerically • You know how to describe some distributions: – Empirically – Theoretically • You have been exposed to two statistical packages to help you do these tasks: – R with Rcmdr – SAS Enterprise Guide So Far • Probability is scored between 0 and 1. 0 0.5 1 Impossible As likely as not Certain Unlikely to occur Likely to occur • Area under a curve or heights of bars represent probability. From Last Time • I talked about when a variable (really its distribution) is (theoretically) normally distributed, it is described by only two parameters (the first two moments of the mean), the mean and standard deviation. • When you are taking sample means (with more than one observation in the mean) and you plot the means, the density looks normally distributed. This fact that the sampling distribution of means looks normal (irrespective of the original distribution) is called the Central Limit Theorem. Moving On • The next steps are to describe other types of distributions and figure out how to quantify just how unusual a weird statistic from your sample actually actually is. • You are not always going to be making generalizations about comparing means. – Comparing variability (variance) is hugely important. Variability of Sample Means • Recall that the number of people (observations) in each sample mattered a lot in determining whether the sampling distribution looked normal. – If you have a decent size sample (the number of people in each sample), it is hard to get very extreme values out of a normal sampling distribution because the extremely big values tend to cancel out the extremely small values. 1500 0 500 Frequency Actual Scores 300 400 500 600 700 600 700 600 700 scores 600 200 0 400 500 bunchOfMeans 200 600 Bunch of Means sample N = 20 0 The distribution of the means from sample size of 20 is narrower still (and bell-shaped). 300 Frequency The distribution of the means from sample size of 5 is narrower than the original values (and bell shaped). Frequency Bunch of Means sample N = 5 300 400 500 bunchOfMeans20 Variability Between Samples • The width of the sampling distribution of the means got narrower and narrower as the size of each of the samples increased. • The variability within a sample (of size 1) is called the standard deviation. • The variability across the means when you have samples bigger than size 1 is called the standard error. Standard Error • The formula for the standard error of the means is just the sample standard deviation formula with a tweak to indicate the impact of the sample size. • The SE plays a huge role in all inferences. You need it to determine what is an odd sample. SD SEMean Sample Size Standard Error Formula • As you move through the year, you will meet many formulas for standard errors. – If you are testing to see if there is a difference between two groups, you use a slightly different formula. – If you are working with the distribution of counts of events happening or not happening in many trials (yes/no getting pregnant on many attempts), the SE formula is different but it plays the same role. It helps you determine what is an unusual value. Probability Functions • Some people are entertained while others are horrified at the prospect of having to do calculus to figure out the area under the curve corresponding to what made an unusual sample. Happily, you don’t have to. You can use the probability functions in a language like SAS or R. Quantiles • Say you want to know what quantile corresponds to a standard normal value. • The standard normal is where you have rescaled your values so they are measured with a mean of 0 and standard deviation of 1. thingy ~ N (0,1) • For example, you may want to know what value cuts off the most extremely large 5% of a standard normal curve. Z-scores for Percentages Z-scores for Percentages What percentiles? • You are far more likely to want to know what percentile your actual scores correspond to. To get those values, you will use the CDF function (Cumulative Density Function). -2 0.0 0.2 -1 0.6 -3 1 0.8 2 1.0 -3 -2 -2 -1 -1 0 0 z 1 1 2 2 3 0 Quantile (Z) 0.4 Probability -4 z 3 -3 0.0 -2 0.2 -1 0 z 0.4 p 1 0.6 2 0.8 3 1.0 0.0 0 100 150 0.1 0.2 0.3 Probability density 50 frequency 0.4 Null Hypothesis • When you design an experiment, you typically propose a hypothesis indicating that nothing interesting is going on. – For example, if you expect a drug and a placebo to act the same way, your null hypothesis is that the average difference is 0. – You reject the null hypothesis if your sample is too far out in the tails of the null distribution. – You typically set up this target (dummy hypothesis) and hope your data does not look like this. Hoe Hoe Hoe • The null hypothesis is typically written H0. That is pronounced H-zero or H-not. Don’t call it “hoe”. • The alternative hypothesis is typically written H1 or HA. What could possibly go wrong? • When you do an experiment you come up with a hypothetical population mean and SD and have a computer calculate sampling distribution of the means (for your sample size). You can then test to see if your data is compatible or weird giving the population mean and standard error. • Call this distribution “the null distribution” because it is what you expect and nothing interesting is going on if you find it is true. • What could possibility go wrong? What could possibly go wrong? • Your guess at the population mean was right but you could get a sample by chance (poor luck) that was from way out in the tails of the distribution. – The first thing that could go wrong is called the Type I (one) Error. • Things could be really bad and your guess about the population mean was wrong but you get a sample that is compatible with your original hypothesis that is not in agreement with reality (this 2nd thing that could go wrong is called the Type II (two) Error. – You won’t notice that the distribution is actually centered around an alternative mean and has an alternative distribution. Think of… Pascal’s Wager The TRUTH Your Decision God Exists God Doesn’t Exist BIG MISTAKE Correct Correct— Big Pay Off MINOR MISTAKE Reject God Accept God Type I and Type II Error in a Box Your Statistical Decision Reject H0 True State of Null Hypothesis H0 True H0 False Type I error (α) Correct Correct Type II Error (β) Do not reject H0 Analogy to Quality Control • In my humble opinion, people typically worry too much about the Type I error. The probability that this error happens is called the p-value and this is called the α (alpha) level. • Failing to realize that the data should be described by an alternative distribution is called the β (beta) error. Hypothesis Testing Analogies Power 1- b Reject Null Is a real difference Is no real difference No Error (true positive) Type 1 error Type 2 error No Error (true negative) Fail to reject b Low metastasis potential Sensitivity High PSA Normal PSA 1- a Is a really caner No cancer No error (true positive) False positive False negative No error (true negative) Specificity Highly aggressive breast cancer Positive image Negative a Is a really caner No cancer No error (true positive) False positive False negative No error (true negative) A Tale About Two Tails • If you want to test to see if your data is incompatible with a null hypotheses, you specify just how weird it needs to be to be called weird. That is, you specify the alpha level. Typically you say a sample statistic that could happen 1 in 20 times is too uncommon to say it happened by chance alone. • For example, you have a hypothetical mean and if your sample mean is very high or very low relative to it, you say it is too odd and you reject the null hypothesis. • Using the code from earlier in the lecture, you could figure out the probability of a value. One-Tailed • Typically you want to know if your value differs from the population value. In other cases (very rarely), you may be interested if and only if the value is greater than the population value. In yet other cases (very rarely), you may be interested if and only if the value is less than the population value. • The test of a difference is a two-tailed test because the value could be unusually high or low. The test of “more than” (as opposed to “different”) is a one-tailed test. The test of “less than” is also a one tailed test. Splitting Tails • If you do a two-sided test and you say a sample is odd if it occurs only 1/20 times, you need to split that .05 percent of the weirdness into both tails. So you cut the distribution such that a sample which is in the upper .025 or lower .025 of the distribution is grounds for rejecting the null hypothesis. But if you say that you are only interested in whether this sample is greater than the hypothetical mean, you can shove all .05 into one tail and it is relatively easy to find a weird sample. Some Moron Tails… • The inexact use of Fisher's Exact Test in six major medical journals by McKinney et al., JAMA Vol. 261 No. 23, June 16, 1989 – We reviewed the use of Fisher's Exact Test in 71 articles published between 1983 and 1987 in six medical journals. Thirty-three of 56 selected articles did not specify use of a one- or two-tailed test, and 12 (36%) of these actually used the one-tailed test. Five (42%) of these 12 articles contained at least one table in which the standard significance level of P less than .05 was no longer met when a two-tailed analysis was run instead. Extreme Caution • If an outcome could biologically be either above or below a population mean, do the two sided tests. There are terrifying scenarios that begin with a standard of care that is so thought to be so good that a new (less invasive) treatment could only be worse. So a researcher does a one-sided test to see if the new treatment is worse. In reality, the gold standard is harmful (pure oxygen to neonates). Therefore, you do not see a statistically significant difference. In other words, they would fail to see the harmful effect of the treatment as statistically significant. What could possibly go wrong? • Recall that in addition to the Type I error caused by having an unusual sample that really came from the null distribution, you could get a value from the alternate distribution that was compatible with the null hypothesis. Alpha and Beta • Alpha and Beta errors are intimately connected in testing hypotheses and van Belle does not make this clear enough. An alternate presentation can be found in Normal and Streiner’s Biostatistics: The Bare Essentials. If you are math phobic, I highly recommend the book. Blood Sodium Example • The story begins with a measure of blood sodium with a known population mean of 140 mmol/L and a standard deviation of 2. In the study, blood measures are taken on 25 people and the mean is 137.5. The question is “does it look unlikely that the sample mean came from a population with a mean of 140 or do you want to conclude that the true population mean is different?” • What do you do? Steps to the Comparison • What is the standard error? • How many standard errors away from the mean is this sample? • If testing for a difference between the groups at the alpha .05 level, what is the cut point in zunits? • What is the cut point in the original units? • What is the power? • What is the beta error? • What happens if you use a smaller sample? The SE • The Standard Error of the mean: • The Z score: ( x ) z / n SEMean SD Sample Size Calculating a Z Score It is a darn unusual sample if the population mean is 140. The Actual Cut Point 136 138 140 142 0.0 0.2 0.4 Density 0.6 0.8 Sample size = 25 • What happens when your sample size was smaller? Sample size = 4 Running the Analyst Pick Your Study Design Fill in the Blanks Get Results as a Table …or as a picture Other Software Packages • S-Plus can easily produce information on power: Best Guesses • So far I talked about making judgments regarding when a sample is compatible with a distribution. Another very important task is making a guess about a population value and specifying the precision of your guess. • This is the process of building confidence intervals. 100% Confidence Intervals • Say I do a sample of ages of Stanford undergraduates. My mean from the sample is 20 years old. That is my point estimate of the population mean. I know that the true mean is not exactly 20. So I give myself some wiggle room by saying 20 plus or minus something. That range is called the confidence interval. • I want to be 100% certain that my guestimated range includes the true population mean, so I say age 20 +/- 90 years. Can I do better than that? • The true population mean is going to be within the range of 0 and 110 years old. So, I have built a 100% confidence interval. • Say I get a sample of 25 undergrads, calculate their mean age, add +/- 10 years and call that the confidence interval. The population mean will or will not be inside of the range. So reality is either yes or no. How do I specify a probability here? • You want specify a range that when you do the sampling experiment many times, you will usually capture the true value within the guestimated range. That is the typical definition of a confidence interval. • You use the sampling distribution we have been talking about to calculate those values.