Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
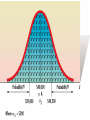
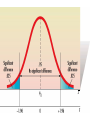
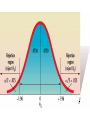
Chapter 8 Introduction to Statistical Inferences Parameters and Statistics • A parameter is a numeric characteristic of a population or distribution, usually symbolized by a Greek letter, such as μ, the population mean. • Inferential Statistics uses sample information to estimate parameters. • A Statistic is a number calculated from data. • There are usually statistics that do the same job for samples that the parameters do for populations, such as x , the sample mean. Using Samples for Estimation μ x Sample (known statistic) Population (unknown parameter) The Idea of Estimation • We want to find a way to estimate the population parameters. • We only have information from a sample, available in the form of statistics. • The sample mean, x , is an estimator of the population mean, μ. • This is called a “point estimate” because it is one point, or a single value. Interval Estimation • There is variation in x , since it is a random variable calculated from data. • A point estimate doesn’t reveal anything about how much the estimate varies. • An interval estimate gives a range of values that is likely to contain the parameter. • Intervals are often reported in polls, such as “56% ±4% favor candidate A.” This suggests we are not sure it is exactly 56%, but we are quite sure that it is between 52% and 60%. • 56% is the point estimate, whereas (52%, 60%) is the interval estimate. The Confidence Interval • A confidence interval is a special interval estimate involving a percent, called the confidence level. • The confidence level tells how often, if samples were repeatedly taken, the interval estimate would surround the true parameter. • We can use this notation: (L,U) or (LCL,UCL). • L and U stand for Lower and Upper endpoints. The longer versions, LCL and UCL, stand for “Lower Confidence Limit” and “Upper Confidence Limit.” • This interval is built around the point estimate. Theory of Confidence Intervals • Alpha (α) represents the probability that when the sample is taken, the calculated CI will miss the parameter. • The confidence level is given by (1-α)×100%, and used to name the interval, so for example, we may have “a 90% CI for μ.” • After sampling, we say that we are, for example, “90% confident that we have captured the true parameter.” (There is no probability at this point. Either we did or we didn’t, but we don’t know.) How to Calculate CI’s • There are many variations, but most CI’s have the following basic structure: • P ± TS – Where P is the parameter estimate, – T is a “table” value equal to the number of standard deviations needed for the confidence level, – and S is the standard deviation of the estimate. • The quantity TS is also called the “Error Bound” (E) or “Margin of Error.” • The CI should be written as (L,U) where L= P-TS, and U= P+TS. A Confidence Interval for μ • If σ is known, and • the population is normally distributed, or n>30 (so that we can say x is approximately normally distiributed), x z / 2 x gives the endpoints for a (1- α)100% CI for μ • Note how this corresponds to the P ± TS formula given earlier. Distribution Details • What is z / 2? – α is the significance level, P(CI will miss) – The subscript on z refers to the upper tail probability, that is, P(Z>z). – To find this value in the table, look up the z-value for a probability of .5-α/2. Hypothesis Tests • So far, we have discussed estimating parameters. • For example, use a sample mean to estimate μ, giving both a point estimate and a CI. • Now we take a different approach. Suppose we have an existing belief about the value of μ. This could come from previous research, or it could be a standard that needs to be met. • Examples: – Previous corn hybrids have achieved 100 bu/acre. We want to show that our new hybrid does better. – Advertising claims have been made that there are 20 chips in every chocolate chip cookie. Support or refute this claim. Framing the Test • We start with a null hypothesis. This represents the status quo, or the conclusion if our test cannot prove anything. • The null hypothesis is denoted by H0: μ=μ0 where μ0 corresponds to the current belief or status quo. (The equal sign could be replaced with an inequality if appropriate.) • Example: – In the corn problem, if our hybrid is not better, it doesn’t beat the previous yield achievement of 100 bu/acre. Then we have H0: μ=100 or possibly H0: μ≤100. – In the cookie problem, if the advertising claims are correct, we have H0: μ=20 or possibly H0: μ≥20. • Notice the choice of null hypothesis is not based on what we hope to prove, but on what is currently accepted. Framing the Test • The alternative hypothesis is the result that you will get if your research proves something is different from status quo or from what is expected. • It is denoted by Ha: μ≠μ0. Sometimes there is more than one alternative, so we can write H1: μ≠μ0, H2: μ>μ0, and H3: μ<μ0. • In the corn problem, if our yield is more than 100 we have proved that our hybrid is better, so the alternative Ha: μ>100 is appropriate. Framing the Test • For the cookie example, if there are less than 20 chips per cookie, the advertisers are wrong and possibly guilty of false advertising, so we want to prove Ha: μ<20. • A jar of peanut butter is supposed to have 16 oz in it. If there is too much, the cost goes up, while if it is too little, consumers will complain. Therefore we have H0: μ=16 and Ha: μ≠16. Difference v. Confidence Intervals • A hypothesis test makes use of an estimate, such as the sample mean, but is not directly concerned with estimation. • The point is to determine if a proposed value of the parameter is contradicted by the data. • A hypothesis test resembles the legal concept of “innocent until proven guilty.” The null hypothesis is innocence. If there is not enough evidence to reject that claim, it stands. Accept vs. Reject • In scientific studies, the null hypothesis is based on the current theory, which will continue to be believed unless there is strong evidence to reject it. • However, the failure to reject the null hypothesis does not mean it is true, just as the guilty sometimes do go free because of lack of evidence. • Thus, statisticians resist saying “accept H0.” When there is enough evidence, we reject H0, and replace it with Ha. H0 is never accepted as a result of the test, since it was assumed to begin with. • Therefore, we will use the terms “Reject H0” and “Do Not Reject H0” (DNR) to describe the results of the test. Hypothesis Tests of the Mean • The null hypothesis is initially assumed true. • It states that the mean has a particular value, μ0. • Therefore, it follows that the distribution of x has the same mean, μ0. • We reason as follows: If we take a sample, we get a particular sample mean, x . If the null hypothesis is true, x is not likely to be “far away” from μ0. It could happen, but it’s not likely. Therefore, if x is “too far away,” we will suspect something is wrong, and reject the null hypothesis. • The next slide shows this graphically. Comments on the Graph • What we see in the previous graph is the idea that lots of sample means will fall close to the true mean. About 68% fall within one standard deviation. There is still a 32% chance of getting a sample mean farther away than that. So, if a mean occurs more than one standard deviation away, we may still consider it quite possible that this is a random fluctuation, rather than a sign that something is wrong with the null hypothesis. More Comments • If we go to two standard deviations, about 95% of observed means would be included. There is only a 5% chance of getting a sample mean farther away than that. So, if a far-away mean occurs (more than two standard deviations out), we think it is more likely that it comes from a different distribution, rather than the one specified in the null hypothesis. Choosing a Significance Level • The next graph shows what it means to choose a 5% significance level. • If the null hypothesis is true, there is only a 5% chance that the standardized sample mean will be above 1.96 or below -1.96. • These values will serve as a cutoff for the test. x Decision Time • We have already shown that we can use a standardized value instead of x to decide when to reject. We will call this value Z*, the standard normal test statistic. • The criterion by which we decide when to reject the null hypothesis is called a “decision rule.” • We establish a cutoff value, beyond which is the rejection region. If Z* falls into that region, we will reject Ho. • The next slide shows this for α=.05. x Steps in Hypothesis Testing 1. State the null and alternative hypotheses 2. Determine the appropriate type of test 3. State the decision rule (Define the rejection region) 4. Calculate the test statistic 5. State the decision and the conclusion in terms of the original problem Example • A jar of peanut butter is supposed to have 16 oz in it. If there is too much, the cost goes up, while if it is too little, consumers will complain. Assume the amount filled is normally distributed with a standard deviation of ½ oz. In a random sample of 20 jars, the mean amount of peanut butter is 16.15 oz. Conduct a test to see if the jars are properly filled, using α=.05. • Step 1: Hypotheses: H0: μ=16 and Ha: μ≠16. • Step 2: Type of test: The population is normal and standard deviation is given, use Z-test. • Step 3: Decision Rule: Reject H0 if Z*>1.96 or Z*<-1.96. • Step 4: Test Statistic: 16.15 16 .15 Z* .5 / 20 .1118 1.34 • Step 5: Conclusion: Do not reject H0 and conclude the jars may be properly filled. One-tailed Tests • Our graphs so far have shown tests with two tails. • We have also seen that the alternative hypothesis could be of the form H2: μ>μ0, or H3: μ<μ0. • These are one-tailed tests. The rejection region only goes to one side, and all of α goes into one tail (it doesn’t split). /2 /2 Example • Advertising claims have been made that there are 20 chips in every chocolate chip cookie. A sample of 30 cookies gives an average of 18.5 chips per cookie. Assume the standard deviation is 1.5 and conduct an appropriate test using α=.05. • Step 1: Hypotheses: H0: μ=20 and Ha: μ<20. • Step 2: Type of Test: Sample is 30 and standard deviation known, use Z-test. • Step 3: Decision Rule: Reject H0 if Z*<-1.645. • Step 4: Test statistic: Z * 18.5 20 1.5 5.48 1.5 / 30 .2739 • Step 5: Reject H0 and conclude the cookies contain less than 20 chips per cookie on average. Making Mistakes • Hypothesis testing is a statistical process involving random events. As a result, we could make the wrong decision. • A Type I Error occurs if we reject H0 when it is true. The probability of this is known as α, the level of significance. • A Type II Error occurs when we fail to reject a false null hypothesis. The probability of this is known as β. • The Power of a test is 1-β. This is the probability of rejecting the null hypothesis when it is false. Classification of Errors Actual Decision Ho True Ho False Reject Type I Err Type B P(Error)= α Correct Do Not Reject Type A Correct Type II Err P(Error)=β Two numbers describe a test • The significance level of a test is α, the probability of rejecting Ho if it is true. • The power of a test is 1-β, the probability of rejecting Ho if it is false. • There is a kind of trade-off between significance and power. We want significance small and power large, but they tend to increase or decrease together. p-Value Testing • Say you are reporting some research in biology and in your paper you state that you have rejected the null hypothesis at the .10 level. Someone reviewing the paper may say, “What if you used a .05 level? Would you still have rejected?” • To avoid this kind of question, researchers began reporting the p-value, which is actually the smallest α that would result in a rejection. • It’s kind of like coming at the problem from behind. Instead looking at α to determine a critical region, we let the estimate show us the critical region that would “work.” How p-Values Work • To simplify the explanation, let’s look at a right-tailed means test. We assume a distribution with mean μ0 and we calculate a sample mean. • What if our sample mean fell right on the boundary of the Z* critical region? • This is just at the point where we would reject H0. • So if we calculate the probability of a value greater than x , this corresponds to the smallest α that results in a rejection. • If the test is two tailed, we have to double the probability, because x marks one part of the rejection region, but its negative marks the other part, on the other side (other tail). Using a p-Value • Using a p-Value couldn’t be easier. If p<α, we reject H0. That’s it. • p-Values tell us something about the “strength” of a rejection. If p is really small, we can be very confident in the decision. • In real world problems, many p-Values turn out to be like .001 or even less. We can feel very good about a rejection in this case. However, if p is around .05 or .1, we might be a little nervous. • When Fischer originally proposed these ideas early in the last century, he suggested three categories of decision: – p < .05 Reject H0 – .05 ≤ p ≤ .20 more research needed – p > .20 Accept H0