Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
+
Chapter 2
Modeling Distributions of Data
2.1
Describing Location in a Distribution
2.2
Normal Distributions
+ Section 2.1
Describing Location in a Distribution
Learning Objectives
After this section, you should be able to…
MEASURE position using percentiles
INTERPRET cumulative relative frequency graphs
MEASURE position using z-scores
TRANSFORM data
DEFINE and DESCRIBE density curves
Position: Percentiles
One way to describe the location of a value in a distribution
is to tell what percent of observations are less than it.
Definition:
The pth percentile of a distribution is the value
with p percent of the observations less than it.
Jenny earned a score of 86 on her test. How did she perform
relative to the rest of the class?
6 7
7 2334
7 5777899
8 00123334
8 569
9 03
Her score was greater than 21 of the 25
observations. Since 21 of the 25, or 84%, of the
scores are below hers, Jenny is at the 84th
percentile in the class’s test score distribution.
+
Measuring
+ TIPs!!!!!!
Percentiles should be whole numbers.
If you get a decimal, round the answer to the nearest integer
If you get 0.9213, assume 92nd percentile.
If two observations have the same value, they will be at the
same percentile. To find the percentile, calculate the percent of
the values in the distribution that are below both values
Unfortunately , there is no universally agreed upon definition of
“percentiles”
On the AP exam, students will be allowed to use any
reasonable definition of “percentile” on the free response
section.
+ Your Turn:
Wins in Major League Baseball
The stemplot below shows the number of wins for each of the 30
Major League Baseball teams in 2009.
5
6
7
8
9
10
9
2455
00455589
0345667778
123557
3
Key: 5|9 represents a
team with 59 wins.
Find the percentiles for the following teams:
(a) The Colorado Rockies, who won 92 games.
(b) The New York Yankees, who won 103 games.
(c) The Kansas City Royals and Cleveland Indians, who both won 65
games.
+
Solution:
(a) The Colorado Rockies, who won 92
games, are at the 80th percentile, since 24/30
teams had fewer wins than they did.
(b) The New York Yankees, who won 103
games, are at about the 97th percentile since
29/30 teams had fewer wins than they did.
(c) The two teams with 65 wins, the Kansas
City Royals and the Cleveland Indians, are at
the 10th percentile since only 3/30 teams had
fewer wins than they did.
Relative Frequency Graphs
A cumulative relative frequency graph (or ogive)
displays the cumulative relative frequency of each
class of a frequency distribution.
Age of First 44 Presidents When They Were
Inaugurated
Age
Frequenc
y
Relative
frequency
Cumulative
frequency
Cumulativ
e relative
frequency
4044
2
2/44 =
4.5%
2
2/44 =
4.5%
4549
7
7/44 =
15.9%
9
9/44 =
20.5%
5054
13
13/44 =
29.5%
22
22/44 =
50.0%
5559
12
12/44 =
34%
34
34/44 =
77.3%
6064
7
7/44 =
15.9%
41
41/44 =
93.2%
6569
3
3/44 =
6.8%
44
44/44 =
100%
+
Cumulative
Interpreting Cumulative Relative Frequency Graphs
Use the graph from page 88 to answer the following questions.
Was Barack Obama, who was inaugurated at age 47,
unusually young?
Estimate and interpret the 65th percentile of the distribution
65
11
47
58
+
+ Your turn:
State Median Household Incomes
Here is a table showing the distribution of median household incomes
for the 50 states and the District of Columbia.
Median
Income
($1000s)
Frequency
35 to < 40
1
40 to < 45
10
45 to < 50
14
50 to < 55
12
55 to < 60
5
60 to < 65
6
65 to < 70
3
Relative
Frequency
Cumulative
Frequency
Cumulative
Relative
Frequency
+
Median
Income
($1000s)
Frequency
Relative
Frequency
Cumulative
Frequency
Cumulative
Relative
Frequency
35 to < 40
1
1/51 = 0.020
1
1/51 = 0.020
40 to < 45
10
10/51 = 0.196
11
11/51 = 0.216
45 to < 50
14
14/51 = 0.275
25
25/51 = 0.490
50 to < 55
12
12/51 = 0.236
37
37/51 = 0.725
55 to < 60
5
5/51 = 0.098
42
42/51 = 0.824
60 to < 65
6
6/51 = 0.118
48
48/51 = 0.941
65 to < 70
3
3/51 = 0.059
51
51/51 = 1.000
+ Make a Cumulative Frequency Graph: OGIVE
What does the point ( 50, 0.49) and
( 50,0.725) mean?
The point at (50,0.49) means 49% of
the states had median household
incomes less than $50,000.
The point at (55, 0.725) means that 72.5% of the states had
median household incomes less than $55,000.
Thus, 72.5% - 49% = 23.5% of the states had median household
incomes between $50,000 and $55,000 since the cumulative
relative frequency increased by 0.235.
Due to rounding error, this value is slightly different than the
relative frequency for the 50 to <55 category.
+ Measuring Position: z-Scores
A
z-score tells us how many
standard deviations from the mean
an observation falls, and in what
direction.
Definition:
If x is an observation from a distribution that has known mean and
standard deviation, the standardized value of x is:
x mean
z
standard deviation
A standardized value is often called a z-score.
Position: z-Scores
Jenny earned a score of 86 on her test. The
class mean is 80 and the standard deviation
is 6.07. What is her standardized score?
x mean
86 80
z
0.99
standard deviation
6.07
+
Measuring
+
We can see that Jenny’s score of 86 is “above
average” but how far above is it?
Jenny earned a score of 86 on her test. The class
mean is 80 and the standard deviation is 6.07.
What is her standardized score?
x mean
86 80
z
0.99
standard deviation
6.07
means that Jenny’s score was almost
1 full standard deviation above the mean.
This
+Calculating z-scores
79 81 80 77 73 83 74 93 78 80 75 67 73
77 83 86 90 79 85 83 89 84 82 77 72
6| 7
7 | 2334
7 | 5777899
8 | 00123334
8 | 569
9 | 03
Jenny: z = (86-80)/6.07
z = 0.99
{above average = +z}
Kevin: z = (72-80)/6.07
z = -1.32
{below average = -z}
Kim: z = (80-80)/6.07
z=0
{average z = 0}
+
Using
z-scores for Comparison
Standardized values can be used to compare scores from
two different distributions.
Jenny’s Scores:
Statistics Test: mean = 80, std dev = 6.07
Chemistry Test: mean = 76, std dev = 4
Jenny got an 86 in Statistics and 82 in Chemistry.
On which test did she perform better?
82 76
4
86 80
z stats
6.07
zchem
z stats 0.99
zchem 1.5
Although she had a lower score, she performed relatively
better in Chemistry.
+Percentiles
Another measure of relative standing is a percentile
rank.
pth percentile: Value with p% of observations below it.
median = 50th percentile {mean=50th %ile if
symmetric}
Q1 = 25th percentile
Q3 = 75th percentile
Jenny got an 86.
22 of the 25 scores are ≤ 86.
Jenny is in the 22/25 = 88th %ile.
6| 7
7 | 2334
7 | 5777899
8 | 00123334
8 | 569
9 | 03
+
Transforming
Data
Transforming converts the original observations from the original
units of measurements to another scale. Transformations can affect
the shape, center, and spread of a distribution.
Effect of Adding (or Subracting) a Constant
Adding the same number x (either positive, zero, or negative) to each
observation:
•adds x to measures of center and location (mean, median,
quartiles, percentiles), but
•Does not change the shape of the distribution or measures of
spread (range, IQR, standard deviation).
n
Example, p. 93
Mean
sx
Min
Q1
M
Q3
Max
IQR
Range
Guess(m)
44
16.02
7.14
8
11
15
17
40
6
32
Error (m)
44
3.02
7.14
-5
-2
2
4
27
6
32
+
Transforming
Data
Effect of Multiplying (or Dividing) by a Constant
Multiplying (or dividing) each observation by the same number b
(positive, negative, or zero):
•multiplies (divides) measures of center and location by b
•multiplies (divides) measures of spread by |b|, but
•does not change the shape of the distribution
n
Example, p. 95
Mean
sx
Min
Q1
M
Q3
Max
IQR
Range
Error(ft)
44
9.91
23.43
-16.4
-6.56
6.56
13.12
88.56
19.68
104.96
Error (m)
44
3.02
7.14
-5
-2
2
4
27
6
32
Curves
In Chapter 1, we developed a kit of graphical and numerical
tools for describing distributions. Now, we’ll add one more step
to the strategy.
Exploring Quantitative Data
1. Always plot your data: make a graph.
2. Look for the overall pattern (shape, center, and spread) and
for striking departures such as outliers.
3. Calculate a numerical summary to briefly describe center
and spread.
4.
Sometimes the overall pattern of a large number of
observations is so regular that we can describe it by a
smooth curve.
+
Density
Curve
Definition:
A density curve is a curve that
•is always on or above the horizontal axis, and
•has area underneath is exactly 1 it. ( 100% of
observations)
A density curve describes the overall pattern of a distribution.
The area under the curve and above any interval of values on
the horizontal axis is the proportion of all observations that fall in
that interval.
The overall pattern of this histogram of
the scores of all 947 seventh-grade
students in Gary, Indiana, on the
vocabulary part of the Iowa Test of
Basic Skills (ITBS) can be described
by a smooth curve drawn through the
tops of the bars.
+
Density
Density Curves
Density Curves come in many different shapes; symmetric,
skewed, uniform, etc.
The area of a region of a density curve represents the %
of observations that fall in that region.
The median of a density curve cuts the area in half.
The mean of a density curve is its “balance point.”
Area under the curve
Density Curves
Our measures of center and spread apply to density curves as
well as to actual sets of observations.
Distinguishing the Median and Mean of a Density Curve
The median of a density curve is the equal-areas point, the
point that divides the area under the curve in half.
The mean of a density curve is the balance point, at which the
curve would balance if made of solid material.
The median and the mean are the same for a symmetric density
curve. They both lie at the center of the curve. The mean of
a skewed curve is pulled away from the median in the
direction of the long tail.
+
Describing
+
Section 2.1
Describing Location in a Distribution
Summary
In this section, we learned that…
There are two ways of describing an individual’s location within a
distribution – the percentile and z-score.
A cumulative relative frequency graph allows us to examine
location within a distribution.
It is common to transform data, especially when changing units of
measurement. Transforming data can affect the shape, center, and
spread of a distribution.
We can sometimes describe the overall pattern of a distribution by a
density curve (an idealized description of a distribution that smooths
out the irregularities in the actual data).
+ Lets Practice:
# 1, 4, 6,
9,10, 14,
15,16, 27
+
+
+ 2.4:
Larry’s wife should gently break the
news that being in the 90th percentile
is not good news in this situation.
About 90% of men similar to Larry
have lower blood pressures. The
doctor was suggesting that Larry take
action to lower his blood pressure.
+ 2.6. Peter’s time was slower than 80% of his previous
race times that season, but it was slower than only
50% of the racers at the league championship meet.
+
+ DO NOW:
In 2010, Taxi Cabs in New York City charged an
initial fee of $2.50 plus $2 per mile. In equation form,
fare = 2.50 + 2(miles). At the end of a month a
businessman collects all of his taxi cab receipts and
calculates some numerical summaries. The mean fare
he paid was $15.45 with a standard deviation of
$10.20. What are the mean and standard deviation of
the lengths of his cab rides in miles?
Answer:
fare 2.50
Solving the equation fare = 2.50 + 2(miles) for miles, we get miles
. Thus,
2
to find the mean number of miles, subtract 2.50 from the mean fare to get 12.95 and
divide by 2 to get 6.475 miles. To find the standard deviation, we divide the standard
deviation of the fares by 2 to get 5.10 miles. We don’t subtract 2.50 since subtracting a
constant from each observation does not change the spread of a distribution.
+
Looking Ahead…
In the next Section…
We’ll learn about one particularly important class of
density curves – the Normal Distributions
We’ll learn
The 68-95-99.7 Rule
The Standard Normal Distribution
Normal Distribution Calculations, and
Assessing Normality
+
Chapter 2
Modeling Distributions of Data
2.1
Describing Location in a Distribution
2.2
Normal Distributions
+ Section 2.2
Normal Distributions
Learning Objectives
After this section, you should be able to…
DESCRIBE and APPLY the 68-95-99.7 Rule
DESCRIBE the standard Normal Distribution
PERFORM Normal distribution calculations
ASSESS Normality
+
Because
density curves are idealized descriptions,
we need to distinguish between the mean and
standard deviation of the density curve ( sample)
vs. the mean and standard deviation from the
actual observations. ( Population)
Actual
Ideal
mean
st. dev
x
Parameters
(Population)
s
Statistics
( Sample)
One particularly important class of density curves are the
Normal curves, which describe Normal distributions.
All Normal curves are symmetric, single-peaked, and bellshaped
A Specific Normal curve is described by giving its mean µ
and standard deviation σ.
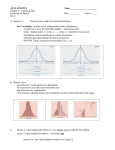
Two Normal curves, showing the mean µ and standard deviation σ.
Normal Distributions
Distributions
+
Normal
Definition:
A Normal distribution is described by a Normal
density curve. Any particular Normal distribution is
completely specified by two numbers: its mean µ and
standard deviation σ.
•The mean of a Normal distribution is the center
of the symmetric Normal curve.
•The standard deviation is the distance from the
center to the change-of-curvature points on
either side.
•We abbreviate the Normal distribution with mean µ
and standard deviation σ as N(µ,σ).
+
Distributions
Normal Distributions
Normal
Why Normal Distributions?
1) Normal distributions describe many sets
of real data. For example...
Scores on tests taken by many people (SAT's,
psychological tests).
Repeated careful measurements of the same quantity.
Characteristics of biological populations (such as
yields of corn and lengths of animal pregnancies).
Why Normal Distributions?
2) Normal distributions are good
approximations to the results of many
kinds of chance outcomes, such as tossing
a coin many times.
3) Third, and most important, we will see
that many statistical inference procedures
based on Normal distributions work well for
other roughly symmetric distributions.
Be aware...
Even though many sets of data follow a
Normal distribution, many do not.
Income distributions are skewed right.
Some symmetric distributions are NOT Normal.
Don't assume a distribution is Normal just because it
looks like it.
68-95-99.7 Rule
Definition:
The 68-95-99.7 Rule (“The Empirical Rule”)
In the Normal distribution with mean µ and standard deviation σ:
•Approximately 68% of the observations fall within σ of µ.
•Approximately 95% of the observations fall within 2σ of µ.
•Approximately 99.7% of the observations fall within 3σ of µ.
+
The
The 68-95-99.7 Rule
Example: The batting averages for Major
League Baseball players in 2009, the mean
of the 432 batting averages was 0.261 with
a standard deviation of 0.034.
Suppose that the distribution with
= 0.261 , = 0.034
(a) Sketch a Normal density curve for this distribution
of batting averages. Label the points that are 1, 2, and 3
standard deviations from the mean.
(b) What percent of the batting averages are above
0.329? Show your work.
(c) What percent of the batting averages are between
0.193 and .295? Show your work.
+ (b) Here is a curve showing the proportion of batting averages
above 0.329.
Since 0.329 is exactly two standard deviations above the mean, we
know that about 95% of batting averages will be between 0.193 and
0.329.
Since the curve is symmetric, half of the remaining 5%, or 2.5%
should be above 0.329.
+ (c) Here is a curve showing the proportion of batting
averages between 0.193 and 0.295.
We know that about 68% of batting averages are
between 0.227 and 0.295.
Also, we know that half of the difference between
95% and 68% should be between 0.193 and 0.227.
Therefore, about 13.5% + 68% = 81.5% of batting
averages will be between 0.193 and 0.295.
All Normal distributions are the same if we measure in units
of size σ from the mean µ as center.
Definition:
The standard Normal distribution is the Normal distribution
with mean 0 and standard deviation 1.
If a variable x has any Normal distribution N(µ,σ) with mean µ
and standard deviation σ, then the standardized variable
z
x -
has the standard Normal distribution, N(0,1).
Normal Distributions
Standard Normal Distribution
+
The
Recall an area under a density curve is a
proportion of the observations in a distribution.
Because all Normal distributions are the same
once we standardize, you can now find
percentages under Normal curves without
Calculus, using the standard Normal table.
+
+
Standard Normal Table
Because all Normal distributions are the same when we
standardize, we can find areas under any Normal curve from
a single table.
Definition:
The Standard Normal Table
Table A is a table of areas under the standard Normal curve. The table
entry for each value z is the area under the curve to the left of z.
Suppose we want to find the
proportion of observations from the
standard Normal distribution that are
less than 0.81.
We can use Table A:
Z
.00
.01
.02
0.7
.7580
.7611
.7642
0.8
.7881
.7910
.7939
0.9
.8159
.8186
.8212
P(z < 0.81) = .7910
Normal Distributions
The
Be aware...
A common mistake is to look up a z-value in Table A and
report the entry corresponding to that z-value,
regardless of whether the problem asks for the area to
the left or to the right of that z-value.
Always sketch the standard Normal curve, mark the zvalue, shade the area of interest, and make sure your
answer is reasonable in the context of the problem.
+
Example, p. 117
Finding Areas Under the Standard Normal Curve
Normal Distributions
Find the proportion of observations from the standard Normal distribution that
are between -1.25 and 0.81.
Can you find the same proportion using a different approach?
1 - (0.1056+0.2090) = 1 – 0.3146
= 0.6854
+
Using the Standard Normal Table
Find
the proportion between -1.23 and 2.11
(Area left of 2.11) – (Area right of -1.23)
0.9826
– 0.1093
=
0.8733
Cholesterol in Young Boys
For 14-year-old boys, the mean is µ=170 milligrams of
cholesterol per deciliter of blood (mg/dl) and the standard
deviation is σ = 30 mg/dl.
Levels above 240 mg/dl may require medical attention.
What percent of 14-year-old boys have more than 240 mg/dl
of cholesterol?
Draw a picture
Use the table
240 170
z
2.33
30
P ( z 2.33) 1 0.9901
0.0099
0.99%
Cholesterol in Young Boys
What percent of 14-year-old boys have blood
cholesterol between 170 and 240 mg/dl
Area between 0 and 2.33 =
area below 2.33-area below 0.00
= .9901 - .5000 = .4901
Calculator :
normalcdf ( 170, 240 , 170, 30) = .4901846
lb
ub
mean
sd
How to Solve Problems Involving Normal Distributions
State: Express the problem in terms of the observed variable x.
Plan: Draw a picture of the distribution and shade the area of
interest under the curve.
Do: Perform calculations.
•Standardize x to restate the problem in terms of a standard
Normal variable z.
•Use Table A and the fact that the total area under the curve
is 1 to find the required area under the standard Normal curve.
Conclude: Write your conclusion in the context of the problem.
+
Distribution Calculations
Normal Distributions
Normal
+
Distribution Calculations
When Tiger Woods hits his driver, the distance the ball travels can be
described by N(304, 8). What percent of Tiger’s drives travel between 305
and 325 yards?
When x = 305, z =
305 - 304
0.13
8
When x = 325, z =
325 - 304
2.63
8
Normal Distributions
Normal
Using Table A, we can find the area to the left of z=2.63 and the area to the left of z=0.13.
0.9957 – 0.5517 = 0.4440. About 44% of Tiger’s drives travel between 305 and 325 yards.
+ FINDING A VALUE WHEN
GIVEN A PROPORTION
To
find the observed value that corresponds to a
given percentile
Rule
:
Use Table A backwards.
Find
the given proportion in the
body of the table and read the
corresponding z value from the
left column and top row.
+ Cholesterol
in boys problem
Mean = 170 mg/dl , Sd = 30 mg/dl
Find the First Quartile of the distribution of blood
cholesterol.
Answer: First quartile means area from the left is 0.25.
Look in the body of Table A for number closest to 0.25.
It is 0.2514. The z value for this is z = -0.67 ( which is
standardized).
To unstandardize: It helps to find the x value.
Solve for x x = 149.9.
x 170
0.67
30
The 1st Quartile of blood cholesterol is about 150 mg/dl.
+
Calculator:
To get area from z value:
2nd Distribution ( Vars)
normalcdf ( lower bound, upper bound, mean, Sd)
To get z value from area (unstandardize)
2nd Distribution ( Vars)
invNorm ( proportion, mean, sd)
+
IQ Scores
Based
on N(100,16) what % of people’s IQ
scores would you expect to be:
a)
b)
c)
d)
e)
f)
over 80?
under 90?
between 112 and 132?
What IQ represents the 15th percentile
What IQ represents the 98th percentile
What is the IQR of the IQ’s
+ AP EXAM COMMON ERROR
You will not get full credit if
you use calculator speak.
Look at AP Exam tip P- 124.
Label each number and also
draw the sketch.
The Normal distributions provide good models for some
distributions of real data. Many statistical inference procedures
are based on the assumption that the population is
approximately Normally distributed. Consequently, we need a
strategy for assessing Normality.
Plot the data.
•Make a dotplot, stemplot, or histogram and see if the graph is
approximately symmetric and bell-shaped.
Check whether the data follow the 68-95-99.7 rule.
•Count how many observations fall within one, two, and three
standard deviations of the mean and check to see if these
percents are close to the 68%, 95%, and 99.7% targets for a
Normal distribution.
+
Normality
Normal Distributions
Assessing
Most software packages can construct Normal probability plots.
These plots are constructed by plotting each observation in a data set
against its corresponding percentile’s z-score.
Interpreting Normal Probability Plots
If the points on a Normal probability plot lie close to a straight line,
the plot indicates that the data are Normal. Systematic deviations from
a straight line indicate a non-Normal distribution. Outliers appear as
points that are far away from the overall pattern of the plot.
Normal Distributions
Probability Plots
+
Normal
+ Do Check your understanding: P- 119.
+ P- 119
+ P- 119
+ P- 119
+ P- 119
+ How to use calculator for normality plot.
Make list L1 ready
Then do 2nd Stat plot: Choose : type 6th one.
+ Do:
Page : 133 # 63, 66, 69-74( all)
+
Section 2.2
Normal Distributions
Summary
In this section, we learned that…
The Normal Distributions are described by a special family of bellshaped, symmetric density curves called Normal curves. The mean
µ and standard deviation σ completely specify a Normal distribution
N(µ,σ). The mean is the center of the curve, and σ is the distance
from µ to the change-of-curvature points on either side.
All Normal distributions obey the 68-95-99.7 Rule, which describes
what percent of observations lie within one, two, and three standard
deviations of the mean.
+
Section 2.2
Normal Distributions
Summary
In this section, we learned that…
All Normal distributions are the same when measurements are
standardized. The standard Normal distribution has mean µ=0
and standard deviation σ=1.
Table A gives percentiles for the standard Normal curve. By
standardizing, we can use Table A to determine the percentile for a
given z-score or the z-score corresponding to a given percentile in
any Normal distribution.
To assess Normality for a given set of data, we first observe its
shape. We then check how well the data fits the 68-95-99.7 rule. We
can also construct and interpret a Normal probability plot.