Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Lecture 9
Topics
Hashing
Reference: Introduction to Algorithm by Cormen
Chapter 12: Hash Tables
Data Structure and Algorithm
1.1
Introduction
A hash table is a generalization of the
simpler notion of an ordinary array
Searching for an element in a hash table
can take as long as searching for an
element in an array/linked list i.e. O(N)
time in the worst case.
But under reasonable assumptions,
hashing takes O(1) time to search an
element in a hash table.
Data Structure and Algorithm
1.2
Dictionary/Table
Keys
Given a student ID find the record (entry)
Data Structure and Algorithm
1.3
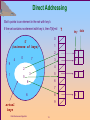
Direct Addressing
Direct Addressing is a simple technique that works well
when the universe U of keys is reasonably small.
Let Universe U= (0,1,…….m-1} where m is not too large
We may assume that no two elements have the same
key.
To represent the dynamic set, we use an array or direct
address table T[0..m-1] in which each position or slot
correspond to a key in the universe U
Data Structure and Algorithm
1.4
Direct Addressing
Slot k points to an element in the set with key k
If the set contains no element with key k, then T[k]=nil
0
1
7
9
2
2
3
3
4
2
1
key data
0
U
(universe of keys)
4
T
k4 5
3
5
8k5
6
5
7
8
6
9
actual
keys
Data Structure and Algorithm
1.5
8
Direct-address Table
Direct addressing is a simple technique that works well when the
universe of keys is small.
Assuming each key corresponds to a unique slot.
Direct-Address-Search(T,k)
return T[k]
Direct-Address-Insert(T,x)
return T[key[x]] x
Direct-Address-Delete(T,x)
return T[key[x]] Nil
5
2
3
entry
1
/
/
/
5
6
7
O(1) time for all operations
Data Structure and Algorithm
/
1
4
7
1
0
1.6
5
/
7
The Problem With Direct Addressing
If the universe U is large, storing a table T of size |U|
may be impractical or even impossible.
Furthermore, the set K of keys actually stored may be
so small relative to U that most of the space allocated
for T would be wasted.
Solution: map keys to smaller range 0..m-1
This mapping is called a hash function
Data Structure and Algorithm
1.7
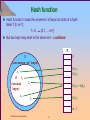
Hash function
Hash function h maps the universe U of keys into slots of a hash
table T [0..m-1]:
h:U
{0,1,….m-1}
But two keys may hash to the same slot – a collision
T
U
(universe of keys)
0
h(k1)
h(k4)
k1
k4
K
(actual
keys)
k2
k5
h(k2) = h(k5)
h(k3)
k3
m-1
Data Structure and Algorithm
1.8
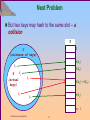
Next Problem
But two keys may hash to the same slot – a
collision
T
0
U
(universe of keys)
h(k1)
h(k4)
k1
k4
K
(actual
keys)
k2
k5
h(k2) = h(k5)
h(k3)
k3
m-1
Data Structure and Algorithm
1.9
Resolving Collisions
How can we solve the problem of
collisions?
Solution 1: chaining
Solution 2: open addressing
Data Structure and Algorithm
1.10
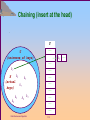
Chaining
Chaining puts elements that hash to the same slot in a linked
list:
U
(universe of keys)
k6
k2
k4
k1 ——
k7
k5
——
——
——
k1
k4
K
(actual
k7
keys)
T
——
k5
——
k8
k3
k3 ——
k8
——
Data Structure and Algorithm
1.11
k6 ——
k2 ——
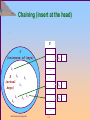
Chaining (insert at the head)
U
(universe of keys)
k1
k4
K
(actual
k7
keys)
k6
k2
k5
k8
k3
Data Structure and Algorithm
T
——
k1 ——
——
——
——
——
——
——
——
——
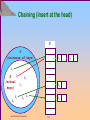
1.12
Chaining (insert at the head)
U
(universe of keys)
k6
k2
k1 ——
——
——
——
k1
k4
K
(actual
k7
keys)
T
——
k5
k2 ——
——
k8
k3
Data Structure and Algorithm
k3 ——
——
——
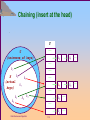
1.13
Chaining (insert at the head)
U
(universe of keys)
k6
k2
k41 ——
——
——
——
k1
k4
K
(actual
k7
keys)
T
——
k5
k2 ——
——
k8
k3
Data Structure and Algorithm
k3 ——
——
——
1.14
k1 ——
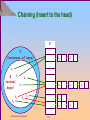
Chaining (insert at the head)
U
(universe of keys)
k6
k2
k41 ——
k1 ——
k52 ——
k2 ——
——
——
——
k1
k4
K
(actual
k7
keys)
T
——
k5
——
k8
k3
k3 ——
——
k6 ——
Data Structure and Algorithm
1.15
Chaining (Insert to the head)
U
(universe of keys)
k6
k2
k4
k1 ——
k7
k5
——
——
——
k1
k4
K
(actual
k7
keys)
T
——
k5
——
k8
k3
k3 ——
k8
——
Data Structure and Algorithm
1.16
k6 ——
k2 ——
Operations
Direct-Hash-Search(T,k)
Search for an element with key k in list T[h(k)]
(running time is proportional to length of the list)
Direct-Hash-Insert(T,x)
(worst case O(1))
Insert x at the head of the list T[h(key[x])]
Direct-Hash-Delete(T,x)
Delete x from the list T[h(key[x])]
(same as searching)
Data Structure and Algorithm
1.17
Open Addressing
Basic idea (details in Section 12.4):
To insert: if slot is full, try another slot, …,
until an open slot is found (probing)
To search, follow same sequence of probes
as would be used when inserting the
element
If reach element with correct key, return it
If reach a NULL pointer, element is not in
table
Good for fixed sets (adding but no deletion)
Table needn’t be much bigger than n
Data Structure and Algorithm
1.18
Choosing A Hash Function
Choosing the hash function well is crucial
Bad hash function puts all elements in same
slot
A good hash function:
Should distribute keys uniformly into slots
Should not depend on patterns in the data
Three popular methods:
Division method
Multiplication method
Universal hashing
Data Structure and Algorithm
1.19
The Division Method
h(k) = k mod m
hash k into a table with m slots using the slot
given by the remainder of k divided by m
Elements with adjacent keys hashed to different
slots: good
If keys bear relation to m: bad
In Practice: pick table size m = prime number
not too close to a power of 2 (or 10)
Data Structure and Algorithm
1.20