Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
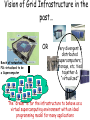
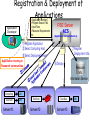
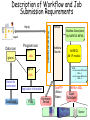
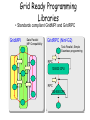
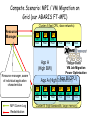
"Towards Petascale Grids as a Foundation of E-Science" Satoshi Matsuoka Tokyo Institute of Technology / The NAREGI Project, National Institute of Informatics Oct. 1, 2007 EGEE07 Presentation @ Budapest, Hungary Vision of Grid Infrastructure in the past… OR Bunch of networked PCs virtualized to be a Supercomputer Very divergent & distributed supercomputers, storage, etc. tied together & “virtualized” The “dream” is for the infrastructure to behave as a virtual supercomputing environment with an ideal programming model for many applications But this is not meant to be Don Quixote or wrong tree dog bark picture here TSUBAME: the first 100 Teraflops Supercomputer for Grids 2006-2010 Voltaire ISR9288 Infiniband 10Gbps x2 ~1310+50 Ports ~13.5Terabits/s (3Tbits bisection) 10Gbps+External NW Sun Galaxy 4 (Opteron Dual core 8-socket) Supercomputer in 10480core/655Nodes th Asia” 29 32-128GB [email protected] 21.4TeraBytes 50.4TeraFlops Now 103 OS Linux (SuSE 9, 10) Unified IB TeraFlops Peak NAREGI Grid MW NEC SX-8i (for porting) Sun Blade Integer Workload Accelerator (90 nodes, 720 CPU network “Fastest as of Oct. 31st! 500GB 48disks 500GB 500GB 48disks 48disks Storage 1.5PB 1.0 Petabyte (Sun “Thumper”) 0.1Petabyte (NEC iStore) Lustre FS, NFS, CIF, WebDAV (over IP) 60GB/s 50GB/s aggregate I/O BW ClearSpeed CSX600 SIMD accelerator 360 648 boards, 35 52.2TeraFlops TSUBAME Job Statistics Dec. 2006-Aug.2007 (#Jobs) TSUBAME Jobs 700000 600000 500000 # Jobs • 797,886 Jobs (~3270 daily) • 597,438 serial jobs (74.8%) • 121,108 <=8p jobs (15.2%) 90% • 129,398 ISV Application Jobs (16.2%) • However, >32p jobs account for 2/3 of cumulative CPU usage 400000 系列1 300000 200000 100000 0 =1p <=8p <=16p <=32p <=64p <=128p >128p # Processors / Job Coexistence of ease-of-use in both - short duration parameter survey - large scale MPI Fits the TSUBAME design well In the Supercomputing Landscape, Petaflops class is already here… in early 2008 Other Petaflops 2008/2009 - LANL/IBM “Roadrunner” - JICS/Cray(?) (NSF Track 2) - ORNL/Cray - ANL/IBM BG/P - EU Machines (Julich…) … 2008 LLNL/IBM “BlueGene/P” ~300,000 PPC Cores, ~1PFlops ~72 racks, ~400m2 floorspace ~3MW Power, copper cabling 2008Q1 TACC/Sun “Ranger” ~52,600 “Barcelona” Opteron CPU Cores, ~500TFlops ~100 racks, ~300m2 floorspace 2.4MW Power, 1.4km IB cx4 copper cabling 2 Petabytes HDD > 10 Petaflops > million cores > 10s Petabytes planned for 2011-2012 in the US, Japan, (EU), (other APAC) In fact we can build one now (!) • @Tokyo---One of the Largest IDC in the World (in Tokyo...) • Can fit a 10PF here easy (> 20 Rangers) • On top of a 55KV/6GW Substation • 150m diameter (small baseball stadium) • 140,000 m2 IDC floorspace • 70+70 MW power • Size of entire Google(?) (~million LP nodes) • Source of “Cloud” infrastructure Gilder’s Law – Will make thin-client accessibility to servers essentially “free” Performance per Dollar Spent Optical Fiber (bits per second) (Doubling time 9 Months) Silicon Computer Chips (Number of Transistors) (Doubling time 18 Months) 0 1 Data Storage (bits per square inch) (Doubling time 12 Months) 2 3 Number of Years (Original Scientific American, January 2001 4 5 slide courtesy Phil Papadopoulos @ SDSC) DOE SC Applications Overview (following slides courtesy John Shalf @ LBL NERSC) NAME Discipline Problem/Method Structure MADCAP Cosmology CMB Analysis Dense Matrix FVCAM Climate Modeling AGCM 3D Grid CACTUS Astrophysics General Relativity 3D Grid LBMHD Plasma Physics MHD 2D/3D Lattice GTC Magnetic Fusion Vlasov-Poisson Particle in Cell PARATEC Material Science DFT Fourier/Grid SuperLU Multi-Discipline LU Factorization Sparse Matrix PMEMD Life Sciences Molecular Dynamics Particle Latency Bound vs. Bandwidth Bound? • How large does a message have to be in order to saturate a dedicated circuit on the interconnect? – N1/2 from the early days of vector computing – Bandwidth Delay Product in TCP System Technology MPI Latency Peak Bandwidth Bandwidth Delay Product SGI Altix Numalink-4 1.1us 1.9GB/s 2KB Cray X1 Cray Custom 7.3us 6.3GB/s 46KB NEC ES NEC Custom 5.6us 1.5GB/s 8.4KB Myrinet Cluster Myrinet 2000 5.7us 500MB/s 2.8KB Cray XD1 RapidArray/IB4x 1.7us 2GB/s 3.4KB • Bandwidth Bound if msg size > Bandwidth*Delay • Latency Bound if msg size < Bandwidth*Delay – Except if pipelined (unlikely with MPI due to overhead) – Cannot pipeline MPI collectives (but can in Titanium) (Original slide courtesy John Shalf @ LBL) Diagram of Message Size Distribution Function (MADBench-P2P) 60% of messages > 1MB BW Dominant, Could be executed on WAN (Original slide courtesy John Shalf @ LBL) Message Size Distributions (SuperLU-PTP) > 95% of messages < 1KByte Low latency, tightly coupled LAN (Original slide courtesy John Shalf @ LBL) Collective Buffer Sizes - demise of metacomputing - 95% Latency Bound!!! => For metacomputing, Desktop and small cluster grids pretty much hopeless except parameter sweep apps (Original slide courtesy John Shalf @ LBL) So what does this tell us? • A “grid” programming model for parallelizing a single app is not worthwhile – Either simple parameter sweep / workflow, or will not work – We will have enough problems programming a single system with millions of threads (e.g., Jack’s keynote) • Grid programming at “diplomacy” level – Must look at multiple applications, and how they compete / coordinate • The apps execution environment should be virtualized --- grid being transparent to applications • Zillions of apps in the overall infrastructure, competing for resources • Hundreds to thousands of application components that coordinate (workflow, coupled multi-physics interactions, etc.) – NAREGI focuses on these scenarios Use case in NAREGI: RISM-FMO Coupled Simulation Electronic structure of Nano-scale molecules in solvent is calculated self-consistent by exchanging solvent charge distribution and partial charge of solute molecules. RISM Solvent distribution Mediator GridMPI FMO Electronic structure Mediator Solvent charge distribution is transformed from regular to irregular meshes Suitable for SMP Suitable for Cluster Mulliken charge is transferred for partial charge of solute molecules *Original RISM and FMO codes are developed by Institute of Molecular Science and National Institute of Advanced Industrial Science and Technology, respectively. Registration & Deployment of Applications Application Summary Program Source Files Input Files Resource Requirements etc. Application Developer PSE Server ACS (Application Contents Service) ①Register Application ②Select Compiling Host ⑦Register Deployment Info. ⑤Select Deployment Host Application sharing in Research communities Compiling OK! Test Run OK! Server#1 ⑥Deploy Test Run Server#2 NG! Test Run Server#3 Resource Info. Information Service OK! Description of Workflow and Job Submission Requirements http(s) tomcat Web server(apache) applet Data icon /gfarm/.. Program icon Appli-A JSDL Workflow Servlet JSDL Global file information Application Information PSE NAREGI JM I/F module BPEL <invoke name=EPS-jobA> ↓ JSDL -A <invoke name=BES-jobA> ↓ JSDL -A ………………….. Appli-B DataGrid Wokflow Description By NAREGI-WFML Information Service GridFTP (Stdout Stderr) BPEL+JSDL Super Scheduler Server Reservation Based CoAllocation • Co-allocation for heterogeneous architectures and applications • Used for advanced science applications, huge MPI jobs, realtime visualization on grid, etc... Workflow Abstract JSDL Client Reservation based Co-Allocation Super Scheduler Resource Query DAI Reservation, Submission, Query, Control… Concrete JSDL GridVM Distributed Information Service Concrete JSDL CIM Resource Info. Accounting GridVM UR/RUS Computing Resource Computing Resource Communication Libraries and Tools 1. Modules 2. Features GridMPI: MPI-1 and 2 compliant grid ready MPI library GridRPC:OGF/GridRPC compliant GridRPC library Mediator: Communication tool for heterogeneous applications SBC: Storage based communication tool GridMPI MPI for a collection of geographically distributed resources High performance optimized for high bandwidth network GridMPI Task parallel simple seamless programming Mediator Communication library for heterogeneous applications Data format conversion SBC Storage based communication for heterogeneous applications 3. Supporting Standards MPI-1 and 2 OGF/GridRPC Grid Ready Programming Libraries • Standards compliant GridMPI and GridRPC GridMPI Data Parallel MPI Compatibility GridRPC (Ninf-G2) Task Parallel, Simple Seamless programming RPC 100000 CPU RPC 100-500 CPU Communication Tools for CoAllocation Jobs • Mediator Application-1 Mediator Mediator Data Format Conversion Data Format Conversion GridMPI ( Application-2 ) • SBC (Storage Based Communication) Application-3 SBC library SBC library SBC protocol ( ) Application-2 Compete Scenario: MPI / VM Migration on Grid (our ABARIS FT-MPI) Cluster A (fast CPU, slow networks) Resource Manager MPI MPI MPI VM Host VM Host VM Host Host App A (High BW) Resource manager, aware of individual application characteristics MPI Comm Log Redistribution Host Host VM Job Migration Power Optimization App B(CPU) App A (High Bandwidth) MPI MPI MPI MPI MPI MPI VM Host VM Host VM Host VM Host VM Host VM Host Cluster B (high bandwidth, large memory)