Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Population Genetics Basics
1
Terminology review
•
•
•
•
Allele
Locus
Diploid
SNP
2
Single Nucleotide Polymorphisms
Infinite Sites Assumption:
Each site mutates at most
once
00000101011
10001101001
01000101010
01000000011
00011110000
00101100110
3
What causes variation in a population?
•
•
•
•
Mutations (may lead to SNPs)
Recombinations
Other genetic events (gene conversion)
Structural Polymorphisms
4
Recombination
00000000
11111111
00011111
5
Gene Conversion
•
Gene Conversion
versus crossover
–
Hard to distinguish in
a population
6
Structural polymorphisms
•
Large scale structural changes
(deletions/insertions/inversions) may occur
in a population.
7
Topic 1: Basic Principles
•
In a ‘stable’ population, the distribution of
alleles obeys certain laws
–
•
HW Equilibrium
–
•
Not really, and the deviations are interesting
(due to mixing in a population)
Linkage (dis)-equilibrium
–
Due to recombination
8
Hardy Weinberg equilibrium
•
•
•
•
Consider a locus with 2 alleles, A, a
p (respectively, q) is the frequency of A (resp.
a) in the population
3 Genotypes: AA, Aa, aa
Q: What is the frequency of each genotype
If various assumptions are satisfied, (such as random
mating, no natural selection), Then
• PAA=p2
• PAa=2pq
• Paa=q2
9
Hardy Weinberg: why?
•
Assumptions:
–
–
–
–
–
•
Diploid
Sexual reproduction
Random mating
Bi-allelic sites
Large population size, …
Why? Each individual randomly picks his two
chromosomes. Therefore, Prob. (Aa) = pq+qp
= 2pq, and so on.
10
Hardy Weinberg: Generalizations
•
Multiple alleles with frequencies
–
By HW,
1,2, , H
Pr[homozygous genotype i] = i2
Pr[heterozygous genotype i, j] = 2
i j
•
Multiple loci?
11
Hardy Weinberg: Implications
•
•
•
•
The allele frequency does not change from generation to
generation. Why?
It is observed that 1 in 10,000 caucasians have the disease
phenylketonuria. The disease mutation(s) are all recessive.
What fraction of the population carries the mutation?
Males are 100 times more likely to have the “red’ type of color
blindness than females. Why?
Conclusion: While the HW assumptions are rarely satisfied, the
principle is still important as a baseline assumption, and
significant deviations are interesting.
12
Recombination
00000000
11111111
00011111
13
What if there were no recombinations?
•
•
•
Life would be simpler
Each individual sequence would have a
single parent (even for higher ploidy)
The relationship is expressed as a tree.
14
The Infinite Sites Assumption
00000000
3
00100000
5
8
00100001
•
•
•
00101000
The different sites are linked. A 1 in position 8 implies 0 in
position 5, and vice versa.
Some phenotypes could be linked to the polymorphisms
Some of the linkage is “destroyed” by recombination
15
Infinite sites assumption and Perfect Phylogeny
•
•
Each site is mutated at
most once in the history.
All descendants must carry
the mutated value, and all
others must carry the
ancestral value
i
1 in position i
0 in position i
16
Perfect Phylogeny
•
•
Assume an evolutionary model in which no
recombination takes place, only mutation.
The evolutionary history is explained by a
tree in which every mutation is on an edge of
the tree. All the species in one sub-tree
contain a 0, and all species in the other
contain a 1. Such a tree is called a perfect
phylogeny.
17
The 4-gamete condition
•
•
•
A column i partitions the set
of species into two sets i0,
and i1
A column is homogeneous
w.r.t a set of species, if it has
the same value for all
species. Otherwise, it is
heterogenous.
EX: i is heterogenous w.r.t
{A,D,E}
A
i0 B
C
D
i1 E
F
i
0
0
0
1
1
1
18
4 Gamete Condition
•
4 Gamete Condition
–
–
–
There exists a perfect phylogeny if and only if for all pair of
columns (i,j), either j is not heterogenous w.r.t i0, or i1.
Equivalent to
There exists a perfect phylogeny if and only if for all pairs of
columns (i,j), the following 4 rows do not exist
(0,0), (0,1), (1,0), (1,1)
19
4-gamete condition: proof
•
•
•
Depending on which
edge the mutation j
occurs, either i0, or i1
should be homogenous.
(only if) Every perfect
phylogeny satisfies the 4gamete condition
(if) If the 4-gamete
condition is satisfied,
does a prefect phylogeny
exist?
i
i0
i1
20
An algorithm for constructing a perfect phylogeny
•
•
We will consider the case where 0 is the ancestral
state, and 1 is the mutated state. This will be fixed
later.
In any tree, each node (except the root) has a single
parent.
–
•
•
It is sufficient to construct a parent for every node.
In each step, we add a column and refine some of
the nodes containing multiple children.
Stop if all columns have been considered.
21
Inclusion Property
•
•
For any pair of columns i,j
– i < j if and only if i1 j1
Note that if i<j then the edge
containing i is an ancestor of
the edge containing i
i
j
22
Example
1 2 3 4 5
A 1 1 0 0 0
B 0 0 1 0 0
C 1 1 0 1 0
D 0 0 1 0 1
E 1 0 0 0 0
r
A
B
C D
E
Initially, there is a single clade r, and
each node has r as its parent
23
Sort columns
•
•
Sort columns according to the
inclusion property (note that the
columns are already sorted
here).
This can be achieved by
considering the columns as
binary representations of
numbers (most significant bit in
row 1) and sorting in decreasing
order
A
B
C
D
E
1
1
0
1
0
1
2
1
0
1
0
0
3
0
1
0
1
0
4
0
0
1
0
0
5
0
0
0
1
0
24
Add first column
•
In adding column i
–
–
Check each edge and
decide which side you
belong.
Finally add a node if
you can resolve a clade
A
B
C
D
E
1 2 3 4 5
1 1 0 0 0
0 0 1 0 0
1 1 0 1 0
0 0 1 0 1
1 0 0 0 0
r
u
A
C
E
B
D
25
Adding other columns
•
Add other
columns on
edges using the
ordering
property
A
B
C
D
E
1
1
0
1
0
1
2
1
0
1
0
0
3
0
1
0
1
0
4
0
0
1
0
0
5
0
0
0
1
0
r
1
E
3
2
B
5
4
D
C
A
26
Unrooted case
•
•
Switch the values in each column, so that 0 is
the majority element.
Apply the algorithm for the rooted case
27
Handling recombination
•
•
A tree is not sufficient as a sequence may have 2
parents
Recombination leads to loss of correlation between
columns
28
Linkage (Dis)-equilibrium (LD)
•
•
Consider sites A &B
Case 1: No recombination
– Pr[A,B=0,1] = 0.25
•
•
Linkage disequilibrium
Case 2:Extensive
recombination
– Pr[A,B=(0,1)=0.125
•
Linkage equilibrium
A
0
0
0
0
1
1
1
1
B
1
1
0
0
0
0
0
0
29
Handling recombination
•
•
A tree is not sufficient as a sequence may
have 2 parents
Recombination leads to loss of correlation
between columns
30
Recombination, and populations
•
•
•
•
•
Think of a population of N individual chromosomes.
The population remains stable from generation to
generation.
Without recombination, each individual has exactly
one parent chromosome from the previous
generation.
With recombinations, each individual is derived from
one or two parents.
We will formalize this notion later in the context of
coalescent theory.
31
Linkage (Dis)-equilibrium (LD)
•
•
•
Consider sites A &B
Case 1: No recombination
Each new individual
chromosome chooses a
parent from the existing
‘haplotype’
A
0
0
0
0
1
1
1
1
B
1
1
0
0
0
0
0
0
1
0
32
Linkage (Dis)-equilibrium (LD)
•
•
•
Consider sites A &B
Case 2: diploidy and
recombination
Each new individual
chooses a parent from the
existing alleles
A
0
0
0
0
1
1
1
1
B
1
1
0
0
0
0
0
0
1
1
33
Linkage (Dis)-equilibrium (LD)
•
Consider sites A &B
•
Case 1: No recombination
Each new individual chooses a parent
from the existing ‘haplotype’
– Pr[A,B=0,1] = 0.25
• Linkage disequilibrium
Case 2: Extensive recombination
Each new individual simply chooses
and allele from either site
– Pr[A,B=(0,1)=0.125
• Linkage equilibrium
•
•
•
A
0
0
0
0
1
1
1
1
B
1
1
0
0
0
0
0
0
34
LD
•
In the absence of recombination,
–
–
•
Correlation between columns
The joint probability Pr[A=a,B=b] is different from
P(a)P(b)
With extensive recombination
–
Pr(a,b)=P(a)P(b)
35
Measures of LD
•
•
Consider two bi-allelic sites with alleles
marked with 0 and 1
Define
–
–
•
•
P00 = Pr[Allele 0 in locus 1, and 0 in locus 2]
P0* = Pr[Allele 0 in locus 1]
Linkage equilibrium if P00 = P0* P*0
D = abs(P00 - P0* P*0) = abs(P01 - P0* P*1) = …
36
LD over time
•
With random mating, and fixed recombination
rate r between the sites, Linkage
Disequilibrium will disappear
–
–
–
–
Let D(t) = LD at time t
P(t)00 = (1-r) P(t-1)00 + r P(t-1)0* P(t-1)*0
D(t) = P(t)00 - P(t)0* P(t)*0 = P(t)00 - P(t-1)0* P(t-1)*0
D(t) =(1-r) D(t-1) =(1-r)t D(0)
37
LD over distance
•
Assumption
–
–
•
•
Recombination rate increases linearly with
distance
LD decays exponentially with distance.
The assumption is reasonable, but
recombination rates vary from region to
region, adding to complexity
This simple fact is the basis of disease
association mapping.
38
LD and disease mapping
•
•
•
Consider a mutation that is causal for a disease.
The goal of disease gene mapping is to discover
which gene (locus) carries the mutation.
Consider every polymorphism, and check:
–
–
•
There might be too many polymorphisms
Multiple mutations (even at a single locus) that lead to the
same disease
Instead, consider a dense sample of polymorphisms
that span the genome
39
LD can be used to map disease genes
LD
D
N
N
D
D
N
•
•
0
1
1
0
0
1
LD decays with distance from the disease allele.
By plotting LD, one can short list the region
containing the disease gene.
40
LD and disease gene mapping problems
•
•
•
Marker density?
Complex diseases
Population sub-structure
41
Human Samples
•
•
We look at data from human samples
Gabriel et al. Science 2002.
–
3 populations were sampled at multiple regions spanning the
genome
•
•
•
•
•
•
54 regions (Average size 250Kb)
SNP density 1 over 2Kb
90 Individuals from Nigeria (Yoruban)
93 Europeans
42 Asian
50 African American
42
Population specific recombination
•
•
D’ was used as the
measure between SNP
pairs.
SNP pairs were classified
in one of the following
–
–
–
•
Strong LD
Strong evidence for
recombination
Others (13% of cases)
This roughly favors out-ofafrica. A Coalescent
simulation can help give
confidence values on this.
Gabriel et al., Science 2002
43
Haplotype
Blocks
•
A haplotype block is a region of low recombination.
–
•
•
Define a region as a block if less than 5% of the pairs show strong recombination
Much of the genome is in blocks.
Distribution of block sizes vary across populations.
44
Testing Out-of-Africa
•
•
Generate simulations with and without migration.
Check size of haplotype blocks.
–
–
•
Does it vary when migrations are allowed?
When the ‘new’ population has a bottleneck?
If there was a bottleneck that created European and Asian
populations, can we say anything about frequency of alleles that
are ‘African specific’?
–
Should they be high frequency, or low frequency in African
populations?
45
Haplotype Block: implications
•
•
The genome is mostly partitioned into
haplotype blocks.
Within a block, there is extensive LD.
–
Is this good, or bad, for association mapping?
46
Coalescent reconstruction
•
Reconstructing likely coalescents
47
Re-constructing history in the
absence of recombination
48
An algorithm for constructing a perfect phylogeny
•
•
We will consider the case where 0 is the
ancestral state, and 1 is the mutated state. This
will be fixed later.
In any tree, each node (except the root) has a
single parent.
–
•
•
It is sufficient to construct a parent for every node.
In each step, we add a column and refine some
of the nodes containing multiple children.
Stop if all columns have been considered.
49
Inclusion Property
•
•
For any pair of columns i,j
– i < j if and only if i1 j1
Note that if i<j then the edge
containing i is an ancestor of
the edge containing i
i
j
50
Example
1 2 3 4 5
A 1 1 0 0 0
B 0 0 1 0 0
C 1 1 0 1 0
D 0 0 1 0 1
E 1 0 0 0 0
r
A
B
C D
E
Initially, there is a single clade r, and
each node has r as its parent
51
Sort columns
•
•
Sort columns according to
the inclusion property (note
that the columns are
already sorted here).
This can be achieved by
considering the columns as
binary representations of
numbers (most significant
bit in row 1) and sorting in
decreasing order
A
B
C
D
E
1
1
0
1
0
1
2
1
0
1
0
0
3
0
1
0
1
0
4
0
0
1
0
0
5
0
0
0
1
0
52
Add first column
•
In adding column i
–
–
Check each edge and
decide which side you
belong.
Finally add a node if
you can resolve a clade
A
B
C
D
E
1 2 3 4 5
1 1 0 0 0
0 0 1 0 0
1 1 0 1 0
0 0 1 0 1
1 0 0 0 0
r
u
A
C
E
B
D
53
Adding other columns
•
Add other
columns on
edges using the
ordering
property
A
B
C
D
E
1
1
0
1
0
1
2
1
0
1
0
0
3
0
1
0
1
0
4
0
0
1
0
0
5
0
0
0
1
0
r
1
E
3
2
B
5
4
D
C
A
54
Unrooted case
•
•
•
•
Important point is that the perfect phylogeny condition
does not change when you interchange 1s and 0s at
a column.
Switch the values in each column, so that 0 is the
majority element.
Apply the algorithm for the rooted case.
Homework: show that this is a correct algorithm
55
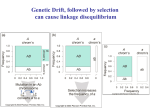
Population Sub-structure
56
Population sub-structure can increase LD
•
•
•
Consider two populations
that were isolated and
evolving independently.
They might have different
allele frequencies in some
regions.
Pick two regions that are
far apart (LD is very low,
close to 0)
0
0
0
1
0
0
0
0
0
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
1
0
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
Pop. A
p1=0.1
q1=0.9
P11=0.1
D=0.01
Pop. B
p1=0.9
q1=0.1
P11=0.1
D=0.01
57
Recent ad-mixing of population
•
•
•
•
If the populations came
together recently (Ex:
African and European
population), artificial LD
might be created.
D = 0.15 (instead of 0.01),
increases 10-fold
This spurious LD might lead
to false associations
Other genetic events can
cause LD to arise, and one
needs to be careful
0
0
0
1
0
0
0
0
0
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
1
0
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
Pop. A+B
p1=0.5
q1=0.5
P11=0.1
D=0.1-0.25=0.15
58
Determining population sub-structure
•
•
Given a mix of people, can you sub-divide them into
ethnic populations.
Turn the ‘problem’ of spurious LD into a clue.
–
–
–
Find markers that are too far apart to show LD
If they do show LD (correlation), that shows the existence of
multiple populations.
Sub-divide them into populations so that LD disappears.
59
Determining Population sub-structure
•
•
•
Same example as before:
The two markers are too
similar to show any LD, yet
they do show LD.
However, if you split them so
that all 0..1 are in one
population and all 1..0 are in
another, LD disappears
0
0
0
1
0
0
0
0
0
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
1
0
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
60
Iterative algorithm for population substructure
•
•
•
•
Define
N = number of individuals (each has a single
chromosome)
k = number of sub-populations.
Z {1..k}N is a vector giving the sub-population.
–
•
•
Zi=k’ => individual i is assigned to population k’
Xi,j = allelic value for individual i in position j
Pk,j,l = frequency of allele l at position j in population k
61
Example
•
•
•
Ex: consider the following
assignment
P1,1,0 = 0.9
P2,1,0 = 0.1
1
1
1
1
1
1
1
1
1
1
0
0
0
1
0
0
0
0
0
0
..
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
2
2
2
2
2
2
2
2
2
2
1
1
0
1
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
0
62
Goal
•
•
•
•
X is known.
P, Z are unknown.
The goal is to estimate Pr(P,Z|X)
Various learning techniques can be employed.
–
–
–
•
maxP,Z Pr(X|P,Z) (Max likelihood estimate)
maxP,Z Pr(X|P,Z) Pr(P,Z) (MAP)
Sample P,Z from Pr(P,Z|X)
Here a Bayesian (MCMC) scheme is employed to
sample from Pr(P,Z|X). We will only consider a
simplified version
63
Algorithm:Structure
•
Iteratively estimate
–
•
•
(Z(0),P(0)), (Z(1),P(1)),.., (Z(m),P(m))
After ‘convergence’, Z(m) is the answer.
Iteration
–
–
Guess Z(0)
For m = 1,2,..
•
•
•
Sample P(m) from Pr(P | X, Z(m-1))
Sample Z(m) from Pr(Z | X, P(m))
How is this sampling done?
64
Example
•
•
•
•
•
Choose Z at random, so each
individual is assigned to be in one of 2
populations. See example.
Now, we need to sample P(1) from
Pr(P | X, Z(0))
Simply count
Nk,j,l = number of people in pouplation k
which have allele l in position j
pk,j,l = Nk,j,l / N
1
2
2
1
1
2
1
2
1
2
0
0
0
1
0
0
0
0
0
0
..
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
1
2
2
1
1
2
1
2
2
1
1
1
0
1
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
0
65
Example
•
•
•
•
•
•
•
Nk,j,l = number of people in population k
which have allele l in position j
pk,j,l = Nk,j,l / Nk,j,*
N1,1,0 = 4
N1,1,1 = 6
p1,1,0 = 4/10
p1,2,0 = 4/10
Thus, we can sample P(m)
1
2
2
1
1
2
1
2
1
2
0
0
0
1
0
0
0
0
0
0
..
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
1
2
2
1
1
2
1
2
2
1
1
1
0
1
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
0
66
Sampling Z
•
•
•
•
•
Pr[Z1 = 1] = Pr[”01” belongs to population 1]?
We know that each position should be in linkage
equilibrium and independent.
Pr[”01” |Population 1] = p1,1,0 * p1,2,1
=(4/10)*(6/10)=(0.24)
Pr[”01” |Population 2] = p2,1,0 * p2,2,1 =
(6/10)*(4/10)=0.24
Pr [Z1 = 1] = 0.24/(0.24+0.24) = 0.5
Assuming, HWE, and LE
67
Sampling
•
•
•
•
•
•
•
Suppose, during the iteration, there is a bias.
Then, in the next step of sampling Z, we will
do the right thing
Pr[“01”| pop. 1] = p1,1,0 * p1,2,1 = 0.7*0.7 = 0.49
Pr[“01”| pop. 2] = p2,1,0 * p2,2,1 =0.3*0.3 = 0.09
Pr[Z1 = 1] = 0.49/(0.49+0.09) = 0.85
Pr[Z6 = 1] = 0.49/(0.49+0.09) = 0.85
Eventually all “01” will become 1 population,
and all “10” will become a second population
1
1
1
2
1
2
1
2
1
1
0
0
0
1
0
0
0
0
0
0
..
..
..
..
..
..
..
..
..
..
1
1
0
1
1
1
1
1
1
1
2
2
2
1
2
2
1
2
2
1
1
1
0
1
1
1
1
1
1
1
..
..
..
..
..
..
..
..
..
..
0
0
0
1
0
0
0
0
0
0
68
Allowing for admixture
•
Define qi,k as the fraction of individual i that
originated from population k.
•
Iteration
–
–
Guess Z(0)
For m = 1,2,..
•
•
Sample P(m),Q(m) from Pr(P,Q | X, Z(m-1))
Sample Z(m) from Pr(Z | X, P(m),Q(m))
69
Estimating Z (admixture case)
•
Instead of estimating Pr(Z(i)=k|X,P,Q), (origin of
individual i is k), we estimate Pr(Z(i,j,l)=k|X,P,Q)
i,1
i,2
j
Pr(Z i, j,l k | X,P,Q)
qi,k Pr(X i, j,l | Z i, j,l k,P)
k'
qi,k' Pr(X i, j,l | Z i, j,l k',P)
70
Results on admixture prediction
71
Results: Thrush data
•
•
For each individual,
q(i) is plotted as the
distance to the
opposite side of the
triangle.
The assignment is
reliable, and there is
evidence of
admixture.
72
Population Structure
•
377 locations (loci) were sampled in 1000 people from 52
populations.
6 genetic clusters were obtained, which corresponded to 5
geographic regions (Rosenberg et al. Science 2003)
Africa
Eurasia
East Asia
Oceania
•
America
73
Population sub-structure:research problem
•
•
Systematically explore the effect of admixture. Can
admixture be predicted for a locus, or for an
individual
The sampling approach may or may not be
appropriate. Formulate as an optimization/learning
problem:
–
–
(w/out admixture). Assign individuals to sub-populations so
as to maximize linkage equilibrium, and hardy weinberg
equilibrium in each of the sub-populations
(w/ admixture) Assign (individuals, loci) to sub-populations
74