Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
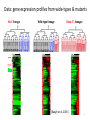
Bayesian Machine learning and its application Alan Qi Feb. 23, 2009 Motivation • massive data from various sources: web pages, facebook, high-throughput biological data, highthroughput chemical data, etc. • Challenging goal: how to model complex systems and extract knowledge from data. Bayesian machine learning Bayesian learning method Principled way to fuse prior knowledge and new evidence in data Key issues Model Design Computation Wide-range applications Bayesian learning in practice Applications: Recommendation systems (Amazon, NetFlix) Text Parsing (Finding latent topics in documents) Systems biology (where computations meets biology) Computer vision (parsing handwritten diagram automatically) Wireless communications Computational finance .... Learning for biology: understanding gene regulation during organism development Learning functionalities of genes for development Protein, product of Gene B DNA Inferring high-resolution proteinDNA binding locations from lowresolution measurement Gene A Learning regulatory cascades during embryonic stem cell development Data: gene expression profiles from wide-types & mutants No C lineage t ime ttime ime Wild-type lineage t ime t ime time t ime Extra ‘C’ lineages time t ime genes genes genes High High High (Baugh et al, 2005) t ime t ime 6 Bayesian semisupervised classification for finding tissue-specific genes Labeled expression BGEN: (Bayesian GENeralization from examples, Qi et al., Bioinformatics 2006) Gene expression Graph-based kernels (F. Chung, 1997, Zhu et al., 2003, Zhou et al. 2004) Labeled expression Classifier Gaussian process classifier that is trained by EP and classifies the whole genome efficiently Estimating noise and probe quality by approximate leave-one-out error Biological experiments support our predictions Non C C Epidermis Muscle K01A2.5 Non C C Epidermis Muscle R11A5.4 Ge’s lab Data: genomic sequences RNA: messager Consensus Sequences Useful for publication IUPAC symbols for degenerate sites Not very amenable to computation Nature Biotechnology 24, 423 - 425 (2006) Probabilistic Model 1 K Count frequencies Add pseudocounts M1 A C G T MK .1 .2 .1 .4 .1 .1 .2 .2 .2 .2 .5 .1 .4 .5 .4 .2 .2 .1 .3 .1 .2 .2 .2 .7 Pk(S|M) Position Frequency Matrix (PFM) P(Sequences|params1,params2) Bayesian learning: Estimating motif models by Gibbs sampling In theory, Gibbs Sampling less likely to get stuck a local maxima P(Sequences|params1,params2) Bayesian learning: Estimating motif models by expectation maximization To minimize the effects of local maxima, you should search multiple times from different starting points Scoring A Sequence To score a sequence, we compare to a null model Log likelihood ratio N Pi (Si | PFM ) N Pi (Si | PFM ) P(S | PFM ) Score log log log P ( S | B) P(Si | B) P ( Si | B ) i 1 i 1 Background DNA (B) PFM A C G T Position Weight Matrix (PWM) .1 .2 .1 .4 .1 .1 A: 0.25 .2 .2 .2 .2 .5 .1 T: 0.25 .4 .5 .4 .2 .2 .1 G: 0.25 .3 .1 .2 .2 .2 .7 C: 0.25 A C G T -1.3 -0.3 -1.3 0.6 -1.3 -1.3 -0.3 -0.3 0.3 -0.3 1 -1.3 0.6 1 0.6 -0.3 -0.3 -1.3 0.3 -1.3 -0.3 -0.3 -0.3 1.4 Scoring a Sequence Common threshold = 60% of maximum score MacIsaac & Fraenkel (2006) PLoS Comp Bio Visualizing Motifs – Motif Logos Represent both base frequency and conservation at each position Height of letter proportional to frequency of base at that position Height of stack proportional to conservation at that position Software implemenation: AlignACE • Implements Gibbs sampling for motif discovery – Several enhancements • ScanAce – look for motifs in a sequence given a model • CompareAce – calculate “similarity” between two motifs (i.e. for clustering motifs) http://atlas.med.harvard.edu/cgi-bin/alignace.pl Data: biological networks Network Decomposition • Infinite Non-negative Matrix Factorization 1. Formulate the discovery of network legos as a nonnegative factorization problem 2. Develop a novel Bayesian model which automatically learns the number of the bases. Network Decomposition •Synthetic Network Decomposition Network Decomposition Data: Movie rating • User-item Matrix of Ratings X = • Recommend: 5 • Not Recommend: 1 Task: how to predict user preference • “Based on the premise that people looking for information should be able to make use of what others have already found and evaluated.” (Maltz & Ehrlich, 1995) • E.g., if you like movies A, B, C, D, and E. And I like A, B, C, D but have not seen E yet. What would be my possible rating on E? Collaborative filtering for recommendation systems • Matrix factorization as an collaborative filtering approach: X≈ZA where X is N by D, Z is N by K and A is K by D. xi,j: user i’s rating on movie j zi,k: user i’s interests in movie category k (e.g., action, thriller, comedy, romance, etc.) Ak,j: how likely movie j belong to movie category k Such that xi,j ≈ zi,1 A1,j + zi,2 A22,j + … + zi,K AK,j Bayesian learning of matrix factorization • Training: Use probability theory, in particular, Bayeisan inference, to learn the model parameters Z, A given data X, which contains missing elements, i.e., unknown ratings • Prediction: use estimated Z and A to predict unkown ratings in X Test resutls • ‘Jester’ dataset: • Map from [-10,10] to [0,20] • 10 random chosen datasets, each with 1000 users. For each user we randomly hold out 10 ratings for testing • IMF, INMF and NMF(K=2…9) Collaborative Filtering Task • How to find latent topics and group documents, such as emails, papers, or news into different clusters? Data: text documents Computer science papers X= Biology papers Assumptions 1. The keywords are shared in different documents of one topic. 2. The more important the keyword is, the more frequent it appears. Matrix factorization models (again) X=ZA xi,j: the frequency word j appears in document zi,k: how much content in document i is related to topic k (e.g., biology, computer science, etc.) Ak,j: how important word j to topic k Bayesian Matrix Factorization • We will use Bayesian methods again to estimate Z and A. • Once we can identify hidden topics by examining A and cluster documents. Text Clustering • ‘20 newsgroup’ dataset • A subset of 815 articles and 477 words. Discovered hidden topics Summary • Bayesian machine learning: A powerful tool enables computers to learn hidden relations from massive data and make sensible predictions. • Applications in computational biology, e.g., gene expression analysis and motif discovery, and information extraction, e.g., text modeling.