Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
BIOTECNOLOGIE FARMACOLOGICHE
CORSO DI LAUREA SPECIALISTICA IN BIOTECNOLOGIE DEL FARMACO
LEZIONE 3
Anno Accademico 2010/11
Mappare i geni:
• Storicamente attraverso la costruzione
di mappe fisiche (identificare e
ordinare marcatori lungo il cromosoma)
• Attualmente con il sequenziamento
mappe fisiche costruite con:
• restriction mapping
•FISH (Fluorescent in situ hybridization) mapping
• studi genetici di ‘linkage’
• use of sequence tagget site (STS)
MITOSIS
profase
•The chromosomes condense
and become visible
•The centrioles form and
move toward opposite ends of
the cell ("the poles")
•The nuclear membrane
dissolves
•The mitotic spindle forms
(from the centrioles in animal
cells)
•Spindle fibers from each
centriole attach to each sister
chromatid at the kinetochore
metafase
•The Centrioles
complete their migration
to the poles
•The chromosomes line
up in the middle of the
cell ("the equator")
anafase
•Spindles attached to
kinetochores begin to
shorten.
•This exerts a force on the
sister chromatids that pulls
them apart.
•Spindle fibers continue to
shorten, pulling chromatids
to opposite poles.
•This ensures that each
daughter cell gets identical
sets of chromosomes
telofase
•The chromosomes
decondense
•The nuclear envelope
forms
•Cytokinesis reaches
completion, creating two
daughter cells
MEIOSIS
• Meiosis: a special type of cell division that occurs in sexually reproducing organisms
• Meiosis reduces the chromosome number by half
Meiosis of diploid cells produces haploid daughter cells, which may function as
gametes.
Gametes undergo fertilization, restoring the diploid number of chromosomes in
the zygote
• Meiosis and fertilization introduce genetic variation in three ways:
Crossing over between homologous chromosomes at prophase I.
Independent assortment of homologous pairs at metaphase I:
•Each homologous pair can orient in either of two ways at the plane of cell
division.
•The total number of possible outcomes = 2n (n = number of haploid
chromosomes).
Random chance fertilization between any one female gamete with any other
male gamete.
Mappe genetiche
Il centimorgan (cM) è l’unità di misura della distanza genetica tra 2
loci. La distanza tra due loci che presentano una frequenza di
ricombinazione dell'1% è 1 cM.
Le misurazioni della distanza tra i diversi loci permettono di generare
mappe genetiche o mappe cromosomiche che quindi sono il risultato di
un calcolo basato sulla osservazione di frequenze di ricombinazione.
.
Analisi di linkage
The LOD score (logarithm (base 10) of odds) is a statistical test often used for linkage analysis in
human populations, and also in animal and plant populations.
The LOD score compares the likelihood of obtaining the test data if the two loci are indeed linked,
to the likelihood of observing the same data purely by chance. Positive LOD score favor the
presence of linkage, whereas negative LOD scores indicate that linkage is less likely.
Computerized LOD score analysis is a simple way to analyze complex family pedigrees in order to
determine the linkage between Mendelian traits (or between a trait and a marker, or two markers).
The method is described in greater detail by Strachan and Read . Briefly, it works as follows:
1. Establish a pedigree
2. Make a number of estimates of recombination frequency
3. Calculate a LOD score for each estimate
4.The estimate with the highest LOD score will be considered the best estimate
The LOD score is calculated as follows:
EREDITA’ DI MARCATORI RFLP
Restriction Fragment Length Polymorphism
Single Nucleotide
Polymorphism
1 /8 ricombina: distanza tra A e gene malattia:
0.125 cM
1 genitore – 0.125
= 0.437
2 tipi di ricomb
Assoc con malattia
Se due eventi non sono legati la
probabilità di ereditarli e ¼ = 0.25
La probabilità di una sequenza alla
nascita è il prodotto del valore di ogni
evento indipendente
Poichè la probabilità di una sequenza alla nascita misurata è
0.125, la frequenza di ricombinazione per gli otto figli sarebbe
uguale a
(0.4375)7(0.0625)1 = 0.0001917
La probabilità di una sequenza senza linkage sarebbe:
(0.25)8 = 0.0000153
Quindi :
LOD SCORE: log 12.566 = 1.099
RESTRICTION MAPPING
1. Frammentazione del DNA genomico con enzimi di
restrizione
2. Separazione dei frammenti per elettroforesi su
agarosio
3. Immobilizzazione DNA per trasferimento su
membrana
4. Ibridazione con sonda opportunamente marcata
5. Identificazione di RLFP
restriction mapping
sequence tagget site
A sequence-tagged site (or STS) is a short (200 to 500 base pair) DNA
sequence that has a single occurrence in the genome and whose location
and base sequence are known.
STSs can be easily detected by the polymerase chain reaction (PCR) using
specific primers. For this reason they are useful for constructing genetic
and physical maps from sequence data reported from many different
laboratories. They serve as landmarks on the developing physical map of a
genome.
When STS loci contain genetic polymorphisms (e.g. simple sequence
length polymorphisms, SSLPs, single nucleotide polymorphisms), they
become valuable genetic markers, i.e. loci which can be used to distinguish
individuals.
They are used in shotgun sequencing, specifically to aid sequence
assembly.
SEQUENZIAMENTO DEL GENOMA UMANO
Progetto GENOMA
UMANO
http://www.ornl.gov/sci/techresources/Human_Genome/home.shtml
Scopi:
• Sequenziamento dei genomi di
interesse biologico o
farmacologico
• Studi di funzione genica
Progetto GENOMA UMANO
Strategie:
• Generazione sistematica di mappe fisiche
• Sequenziamento di Expressed Sequence Tag (EST)
• Miglioramento delle tecnologie di sequenziamento
http://www.ornl.gov/sci/techresources/Human_Genome/project/about.shtml
Strategie di sequenziamento del genoma
Durata del sequenziamento del
genoma umano con il metodo
‘Whole genome shot-gun’
8 settembre 1999
17 giugno 2000
Craig Venter
Termine del progetto Genoma Umano
2003
Investimento NIH nel progetto
3 miliardi di dollari /13 anni
Francis Collin
1990-1994
1990: Launch of the Human Genome Project
1990: ELSI Founded (Ethical, Legal and Social Implications )
1990: Research on BACs
1991: ESTs, Fragments of Genes (expressed-sequence tag )
1992: Second-generation Genetic Map of Human Genome
1992: Data Release Guidelines Established
1993: NEW HGP Five-year Plan
1994: FLAVR SAVR Tomato (Calgene, Inc. of Davis, California )
1994: Detailed Human Genetic Map
1994: Microbial Genome Project (The microbes DOE chose do not cause disease but are
important for their environmental, energy, and commercial roles
1995-1996
1997-1999
1995: Ban on Genetic Discrimination in Workplace
1995: Two Microbial Genomes Sequenced
1995: Physical Map of Human Genome Comp leted
1996: International Strategy Meeting on Human Genome Sequencing
1996: Mouse Genetic Map Completed
1996: Yeast Genome Sequenced
1996: Archaea Genome Sequenced
1996: Health Insurance Discrimination Banned
1996: 280,000 Expressed Sequence Tags (ESTs)
1996: Human Gene Map Created
1996: Human DNA Sequence Begins (large-scale sequencing)
1997: Bermuda Meeting Affirms Principle of Data Release
1997: E. coli Genome Sequenced
1997: Recommendations on Genetic Testing
1998: Private Company Announces Sequencing Plan
1998: M. Tuberculosis Bacterium Sequenced
1998: Committee on Genetic Testing (Service’s Advisory Committee on Genetic Testing
1998: HGP Map Includes 30,000 Human Genes
1998: New HGP Goals for 2003
1998: SNP Initiative Begins (single nucleotide polymorphism, multigene disorders)
1998: Genome of Roundworm C. elegans Sequenced
1999: Full-scale Human Genome Sequencing
1999: Chromosome 22
2000-2001
2002-2003
2000: Free Access to Genomic Information
2000: Chromosome 21
2000: Working Draft
2000: Drosophila and Arabidopsis genomes sequenced
2000: Executive Order Bans Genetic Descrimination in the Federal Workplace
2000: Yeast Interactome Published
2000: Fly Model of Parkinson's Disease Reported
2001: First Draft of the Human Genome Sequence Released
2001: RNAi Shuts Off Mammalian Genes
2001: FDA Approves Genetics-based Drug to Treat Leukemia Gleevec to treat
patients with chronic myeloid leukemia (CML).
2002: Mouse Genome Sequenced
2002: Researchers Find Genetic Variation Associated
with Prostate Cancer
2002: Rice Genome Sequenced
2002: The International HapMap Project is Announced
2002: The Genomes to Life Program is Launched
2002: Researchers Identify Gene Linked to Bipolar Disorder
2003: Human Genome Project Completed
2003: Fiftieth Anniversary of Watson and Crick's Description of the Double Helix
2003: The First National DNA Day Celebrated
2003: ENCODE Program Begins
2003: Premature Aging Gene Identified
2004-The Future
2004: Rat and Chicken Genomes Sequenced
2004: FDA Approves First Microarray
2004: Refined Analysis of Complete Human Genome Sequence
2004: Surgeon General Stresses Importance of Family History
2005: Chimpanzee Genomes Sequenced
2005: HapMap Project Completed
2005: Trypanosomatid Genomes Sequenced
2005: Dog Genomes Sequenced
2006: The Cancer Genome Atlas (TCGA) Project Started
2006: Second Non-human Primate Genome is Sequenced
2006: Initiatives to Establish the Genetic & Environmental Causes
of Common Diseases Launched
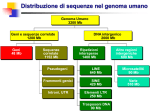
Alcuni risultati dell’analisi della sequenza
del genoma umano
• n. geni 26*103
• arrangiamento dei geni non casuale (in cluster)
• esoni 1.1% del genoma
• introni 24%
• sequenze intergeniche 75%
• > 1.4 milioni di siti polimorfici (SNPs)
NATURE Human Genome Collection
It is now more than 15 years since work began sequencing the 2.85 billion
nucleotides of the human genome. While the draft sequence was published
in Nature in 2001, researchers at the Human Genome Project continued to
fill the gaps and subject individual chromosomes to ever more detailed
analyses. Nature is proud to present here the complete and comprehensive
DNA sequence of the human genome as a freely available resource.
Risultati del Progetto GENOMA UMANO
The Cancer Genome Atlas (TCGA) is a
comprehensive and coordinated effort to
accelerate our understanding of the genetics of
cancer using innovative genome analysis
technologies.
The overarching goal of The Cancer Genome
Atlas (TCGA) is to improve our ability to
diagnose, treat and prevent cancer
The National Institutes of Health announced in 2009 the expansion
of TCGA project.
After a rigorous review process, the scope of the TCGA Research
Network has expanded to include more than 20 tumor types and
thousands of samples over the next five years. Each cancer will
undergo comprehensive genomic characterization that incorporates
powerful bioinformatic and data analysis components. The
expansion of TCGA is expected to lead to the most comprehensive
understanding of cancer genomes and will enable researchers to
further mine the data generated by TCGA to improve prevention,
diagnosis and treatment of cancer.
2003 NIH ENCODE Project
ENCyclopdia Of DNA Elements
(ENCODE).
To identify and locate all of the genome’s proteincoding genes, non-protein coding genes, and other
sequence-based functional elements.
When completed, the collection of elements
identified by the ENCODE program will help
scientists better understand how the genome
influences our health.
1) use gene targeting to make the resource of null alleles, marked
with a high utility reporter, preferably in C57BL/6;
2) support a repository to house the products of this resource;
3) develop improved C57BL/6 ES cells that show robust germline
transmission, so that they may be used in a high throughput
pipeline in generating this resource;
4) implement a data coordination center which will make the status
and relevant data of the production effort available to the
research community.
NIH 2006 Genes and Environment Initiative
(GEI).
GEI has two components:
the analysis of genetic variation among people with
specific diseases
an effort to develop technology that will find new ways
to monitor environmental exposures that interact with
genetic variations leading to disease.
The specific diseases that GEI will focus on will be
decided by peer review.
HapMap Project
The International HapMap Project is a multi-country effort to
identify and catalog genetic similarities and differences in human
beings. Using the information in the HapMap, researchers will be
able to find genes that affect health, disease, and individual
responses to medications and environmental factors.
The goal of the International HapMap Project is to compare the
genetic sequences of different individuals to identify
chromosomal regions where genetic variants are shared