Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
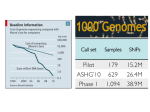
Imputation for GWAS 6 December 2012 Introduction • Imputation describes the process of predicting genotypes that have not been directly typed in a sample of individuals: • missing genotypes at typed variants; • genotypes at un-typed variants that are present in an external high-density “reference panel” of phased haplotypes. • In silico genotypes can be tested for association within standard generalised linear regression framework. How does imputation work? What is the purpose of imputation? • Increased power. The reference panel is more likely to contain the causal variant (or a better tag) than a GWAS array. • Fine-mapping. Imputation provides a highresolution overview of an association signal across a locus. • Meta-analysis. Imputation allows GWAS typed with different arrays to be combined up to variants in the reference panel. Increased power and improved finemapping resolution IMPUTEv2 and minimac • Pre-phasing. Estimate haplotypes at variants typed in the study sample (scaffold). • Haploid imputation. Study sample haplotypes are considered an unknown path through haplotypes from the reference panel. • Hidden Markov model (HMM). • Switch probability between reference haplotypes depends on recombination rate. • Allelic mismatch between reference and observed haplotypes can be incorporated by allowing for low rate of mutation. • Less computationally demanding than diploid imputation that attempts to jointly phase and impute simultaneously (IMPUTEv1 and MaCH). Reference panels • Large-scale genotyping and re-sequencing reference panels made available through HapMap Consortium and 1000 Genomes Project. • HapMap2. 60 CEU, 60 YRI and 90 CHB/JPT individuals typed for ~3M variants. • HapMap3. 1011 individuals from multiple ethnic groups typed for ~1.6M variants. • 1000 Genomes. Most recent release includes 1094 individuals from multiple ethnic groups typed for ~30M variants (including indels). Choice of reference panel • Imputation software designed for use with 1000 Genomes reference panels, but remain computationally demanding. • Making use of the “all ancestries” reference panel (rather than ethnic-specific reference panel) improves imputation accuracy for rare variants. • Formatted reference panels for IMPUTEv2 and minimac can be downloaded from the software websites. Factors affecting imputation accuracy • Scaffold. Number of individuals and GWAS array used for genotyping (coverage of variation). • Reference panel. Number of individuals and density of typing. Similarity of ancestry with study sample. • Minor allele frequency. • Pre-phasing or diploid imputation (minimal). Imputation accuracy Imputation quality control • Pre-imputation. Essential that GWAS scaffold excludes poor quality variants. Common to exclude MAF<1% variants. • Post imputation. Imputation quality assessed by “information measures” in range 0-1. • Information measure α in a scaffold of N individuals has equivalent power to αN perfectly genotyped individuals. • Typical to filter SNPs by α (exclude <0.8, <0.4). • IMPUTEv2 “info score” and minimac ȓ2. • In loci identified through imputation, important to check quality of typed SNPs in the scaffold in the region by visual inspection of cluster plots. Analysis of imputed genotypes • For each individual, imputation provides probability distribution of possible genotypes at each un-typed variant from the reference panel. • Using best guess genotype, or filtering on probability of best guess genotype can increase false positives and reduce power. • Convert probabilities to “expected allele count”, i.e. p1+2p2. • Fully take account of the uncertainty in the imputation in a “missing data likelihood”. • Software: SNPTEST2 (for IMPUTEv2) and Mach2Dat (for minimac). Rare variants and complex disease • Rare variants are likely to have arisen from founder effects in the last few generations. • Rare variants are expected to have larger effects on complex traits that common variants. • Statistical methods focus on the accumulation of minor alleles at rare variants (mutational load) within the same functional unit. GRANVIL • Test of association of phenotype with proportion of rare variants at which individuals carry minor alleles. 1 0 0 0 0 1 0 0 0 1 pi = 3/10 • Model disease phenotype via regression on pi and any other covariates in GLM framework. Reedik Magi http://www.well.ox.ac.uk/GRANVIL/ Assaying rare genetic variation • Gold-standard approach to assaying rare genetic variation is through re-sequencing, which is expensive on the scale of the whole genome. • GWAS genotyping arrays are inexpensive, but are not designed to capture rare genetic variation. • Increasing availability of large-scale reference panels of whole-genome re-sequencing data: 1000 Genomes Project and the UK10K Project. • Impute into GWAS scaffolds up to these reference panels to recover genotypes at rare variants at no additional cost, other than computing. GRANVIL: imputed variants • Test of association of phenotype with proportion of rare variants at which individuals carry minor alleles. 0.9 0.1 0.2 0.1 0.1 0.8 0.1 0.1 0.1 0.6 pi = 3.0/10 • Replace direct genotypes with posterior probability of heterozygous or rare homozygous call from imputation. • Model disease phenotype via regression on pi and any other covariates in GLM framework. Application to WTCCC • GWAS of seven complex human diseases from the UK (2000 cases each and 3000 shared controls from 1958 British Birth Cohort and National Blood Service): • bipolar disease (BD), coronary artery disease (CAD), Crohn’s disease (CD), hypertension (HT), rheumatoid arthritis (RA), type 1 diabetes (T1D) and type 2 diabetes (T2D). • Individuals genotyped using the Affymetrix GeneChip 500K Mapping Array Set. • After quality control, 16,179 samples and 391,060 autosomal SNPs (MAF>1%) carried forward for analysis. Fine-scale UK population structure • Fine-scale population structure may have greater impact on rare variants than on common SNPs because of recent founder effects. • Utilised EIGENSTRAT to construct principal components to represent axes of genetic variation across the UK: 27,770 high-quality LD pruned (r2<0.2) common autosomal SNPs (MAF>5%). Fine-scale UK population structure Imputation • SNPs mapped to NCBI build 37 of human genome. • Samples imputed up to 1000 Genomes Phase 1 cosmopolitan reference panel (June 2011 interim release). • 8.23M imputed autosomal rare variants (MAF<1%) polymorphic in WTCCC. • 5.38M (65.3%) were “well-imputed” (i.e. Info score > 0.4) and carried forward for analysis. • Mean info score was 0.618, and 17.3% had info score > 0.8. Rare variant analysis • Test for association of each disease with accumulation of rare variants (MAF<1%) within genes using GRANVIL. • Gene boundaries defined from UCSC human genome database (build 37). • Analyses adjusted for three principal components to adjust for fine-scale UK population structure. • Genome-wide significance threshold p<1.7x10-6: Bonferroni adjustment for 30,000 genes. No evidence of residual population structure Rare variant association with T1D • Genome-wide significant evidence of association of T1D with rare variants in multiple genes from the MHC. • Strongest signal of association observed for HLA-DRA (p=2.0x10-13). • Gene contains 23 well imputed rare variants with mean MAF of 0.32%. • Accumulations of minor alleles across these variants were associated with decreased risk of disease: odds ratio 0.556 (0.476-0.650) per minor allele. T1D association across the MHC • Ten genes achieve genome-wide significant evidence of rare variant association with T1D. HLA-DRA PBMUCL2 NCR3 SLC44A4 HLA-DRB5 PBX2 TNXA EHMT2 AGPAT1 C6orf10 T1D association across the MHC • After additional adjustment for additive effect of lead GWAS common variant from the MHC (rs9268645). PBX2 SLC44A4 PBMUCL2 EHMT2 HLA-DRA SKIVL2 TNXB AGPAT1 HLA-DRB5 HLA-DMA T1D association across the MHC Comments • GRANVIL assumes the same direction of effect on the trait of all rare variants within the functional unit. • Methodology allowing for different directions of effect of rare variants are well established for resequencing data, and are being generalised to allow for imputation. • The most powerful rare variant test will depend on the underlying genetic architecture of the trait.