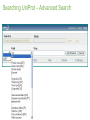
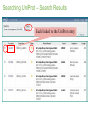
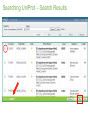
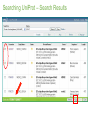
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
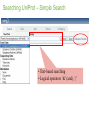
Databases & Data banks “It is a capital mistake to theorize before one has data”. Sir Arthur Conan Doyle (1859-1930), A scandal in Bohemia Banche Dati Biologiche informazioni e dati di letteratura, sperimentali e in silico. Banche Dati Biologiche Struttura delle Banche Dati Banche Dati Primarie Banche Dati Specializzate e Risorse Genomiche Interoperabilità fra le Banche Dati Sistemi di Retrieval Struttura delle Banche dati elemento biologico centrale "entry" della banca dati Struttura delle Banche dati Entry name e Accession Number Informazioni associate Ontologia: una formale descrizione delle entità e delle relazioni intercorrenti fra esse Struttura delle Banche dati Formato flat-file Colonna =attributi Riga=record o k--tupla Tabella relazioni Fig.2.3. Relational database. A table (relation) is a set and the three basic table operations shown here are extensions of the standard set operations. DB deduttivi Fig.2.4. Deductive database. The data in the family tree is represented and manipulated in a deductive database, which consists of a relational database and a logic programming Object oriented Fig. 2.5. Object-oriented database. The concept of similarity is implemented in an object-oriented database wich incorporates many different aspects of genes. Banche Dati DNA e RNA Le Banche Dati di sequenze di acidi nucleici sono spesso Banche Dati Primarie in quanto contengono solo informazioni generiche con un minimo di informazione da associare alla sequenza per identificarla dal punto di vista specie-funzione. Banche Dati Primarie (DNA) 1980 EMBL 1982 GenBank 1986 DDBJ EMBL Data Library Release 110 – Dec 2011 230,021,806 Entries 376,471,768,435 Nucleotides Banche Dati Primarie (Proteine) SWISS-PROT TrEMBL PIR Importance of reference protein sequence databases • Completeness and minimal redundancy A non redundant protein sequence database, with maximal coverage including splice isoforms, disease variant and PTMs. Low degree of redundancy for facilitating peptide assignments • Stability and consistency Stable identifiers and consistent nomenclature Databases are in constant change due to a substantial amount of work to improve their completeness and the quality of sequence annotation • High quality protein annotation Detailed information on protein function, biological processes, molecular interactions and pathways cross-referenced to external source Summary of protein sequence databases Database Description Species UniProtKB Expertly curated section (UniProtKB/Swiss-Prot) and computerannotated section (UniProtKB/TrEMBL); minimum level of redundancy; high level of integration with other databases; stable identifiers; diversity of sources including large scale genomics, small scale cloning and sequencing, protein sequencing, PDB, predicted sequences from Ensembl and RefSeq Many UniRef100 Assembled from UniProtKB, Ensembl and RefSeq; merges 100% identical sequences; stable identifiers Many Ensembl Predictions using automated genome annotation pipeline; explicitly linked to nucleotide and protein sequences; stable reference; merge their annotations with Vega annotations at transcript level; extensive quality checks to remove erroneous gene models ; high level of integration with other databases Over 50 Eukaryotic genomes Ensembl Genomes: Metazoa, Plants and Fungi, Protists, Bacteria and Archaea RefSeq NCBI creates from existing data; ongoing curation; non-redundant; explicitly linked nucleotide and protein sequences; stable reference; high level of integration with other databases Limited to fully sequenced organisms Entrez protein (NCBInr) Assembled from GenBank and RefSeq coding sequence translations and UniProt KB ; annotations extracted from source curated databases; high degree of sequence redundancy Many Updated from Nesvizhskii, A. I., and Aebersold, R. (2005) Interpretation of shotgun proteomic data: the protein inference problem. Mol. Cell. Proteomics. 4,1419– 1440l UniProtKB UniProt Knowledgebase: 1. 2. Master headline 2 sections UniProtKB/Swiss-Prot Non-redundant, highquality manual annotation - reviewed UniProtKB/TrEMBL Redundant, automatically annotated - unreviewed www.uniprot.org Manual annotation of UniProtKB/Swiss-Prot Splice variants Sequence Sequence features UniProtKB Ontologies Annotations Nomenclature References Splice variants Master headline Identification of amino acid variants ..and of PTMs … and also Master headline Protein nomenclature Master headline Master headline Annotation - >30 defined fields Controlled vocabularies used whenever possible… Master headline Sequence evidence Type of evidence that supports the existence of a protein 1 Evidence at protein level There is experimental evidence of the existence of a protein (e.g. Edman sequencing, MS, X-ray/NMR structure, good quality protein-protein interaction , detection by antibodies) 2 Evidence at transcript level The existence of a protein has not been proven but there is expression data (e.g. existence of cDNAs, RT-PCR or Northern blots) that indicates the existence of a transcript. 3 Inferred from homology The existence of a protein is likely because orthologs exist in closely related species 4 Predicted 5 Uncertain Manual annotation of the human proteome (UniProtKB/Swiss-Prot) • A draft of the complete human proteome has been available in UniProtKB/Swiss-Prot since 2008 • Manually annotated representation of 20,242 protein coding genes with ~ 36,000 protein sequences - an additional 38,484 UniProtKB/TrEMBL form the complete proteome set • Approximately 63,000 single amino acid polymorphisms (SAPs), mostly disease-linked • 80,000 post-translational modifications (PTMs) • Close collaboration with NCBI, Ensembl, Sanger Institute and UCSC to provide the authoritative set to the user community Searching UniProt – Simple Search • Text-based searching • Logical operators ‘&’ (and), ‘|’ Master headline Searching UniProt – Advanced Search Master headline Searching UniProt – Search Results Each linked to the UniProt entry Master headline Searching UniProt – Search Results Master headline Searching UniProt – Search Results Master headline Inter-operabilità fra le Banche dati Di fondamentale importanza e’ introdurre nel disegno delle banche dati i meccanismi di cross-referencing che consentono di navigare fra i database anche se dislocati su siti tra di loro remoti A link-based integration of molecular biology databases in the DBGET/LinkDB system at GenomeNet (http://www.genome.ad.jp/). The lines indicate thet the cross-references are given by the original databases.