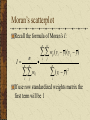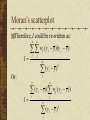Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
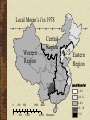
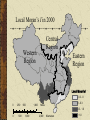
Spatial Association and spatial statistic techniques Danlin Yu Ph.D. Candidate Dept. of Geography, UWM Detecting Spatial Association What is spatial association Spatial objects tend to relate with one another Types of spatial association Spatial autocorrelation: similar (dissimilar) values in space tend to cluster together Spatial heterogeneity: spatial regimes, space is not homogeneous Autocorrelation and heterogeneity are closely related Detecting spatial association Why study spatial association It is inherent in geographic researches When working on spatial data, analyses based on regular statistics are VERY likely to be misleading or incorrect How to detect spatial association Power of GIS Exploratory Spatial Data Analysis (ESDA): let the data speak Background The first law of Geography: Everything is related, but things nearby are more related than things far away Characteristics of spatial statistics Existence of spatial association violates an important statistical assumption: independence Spatial patterns are results of spatial processes – the one we see, is one of numerous possibilities from the same spatial process Types of spatial association Point spatial association Distance is critical in deciding point spatial association Line spatial association Distance and path Areal spatial association Distance and contiguity Today’s topic: univariate SA Univariate: for pattern detection Examples: per capita GDP for economic performance pattern; surface temperature for local climate pattern, etc. Central question: is the pattern we see a result of some specific processes (usually random or normal processes – our null hypothesis)? Multivariate: spatial regression or geographically weighted regression (GWR) Researching means Hypothesis testing in answering this question is conducted via spatial statistic means For univariate geographic data, there are a few indexes in literature: Moran’s Index (Moran’s I) Geary’s Index (Geary’s c) Getis’s G or O Spatial statistic indexes Purposes of the three indexes are very similar – based on the geographic data, calculate an index, test the index against the null The most often encountered index is the Moran’s I Discussion on Moran’s I are applicable to other indexes subject to minor adjustments Moran’s Index (I) Structured like the Pearson’s productmoment statistic: measure of covariance n I n n n i j wij n w ij i ( y i y )( y j y ) j n 2 ( y y ) i i Moran’s I wij is the weight, wij=1 if locations i and j are adjacent and zero otherwise (wii=0, a region is not adjacent to itself). yi and y are the variable in the ith location and the mean of the variable, respectively n is the total number of observations I is used to test hypotheses concerning similarity Determining the weights Two rules Distance: locations within a certain distance are considered as neighbors Border-sharing (for areal units only): areas sharing borders are considered as neighbors Weights matrix: could be symmetric or asymmetric – binary weights matrix, general weights matrix (distance decaying) Determining the weights Spatial weights matrix should be constructed judiciously Ideally, related to general concepts from spatial interaction theory, such as the notions of accessibility and potential etc. Determining the weights When used in hypothesis testing, this requirement is less stringent Since our purpose is to test the null – spatial independence Still, trying a few structures is a good idea – border sharing, different distances Determining the weights A typical symmetric weights matrix is a binary weights matrix where neighbors are coded as 1, others 0 Without losing generality, it is usually row standardized – all elements of one row add up to 1 Hypothesis testing The expected values and the variance for Moran’s I are used for testing However, it is observed that in the null hypothesis, Moran’s I usually does not follow normal distribution Alternatives Random permutation Saddlepoint approximation Hypothesis testing Monte Carlo (random) permutation for Moran’s I Randomly arrange the values among the space and calculate I each time (e.g., 999 times) Comparing the actual I with the 999 randomly gained Is If the actual I falls into area of either more than 95% or less than 5%, it is said the I is psuedo significant at 5% level (positive/negative) Hypothesis testing Saddlepoint approximation (Tiefolsdorf, 2001) Exact distribution of Moran’s I can be obtained, but computationally prohibitive for even medium size data set A saddlepoint distribution approximates the exact distribution with reasonable accuracy Based on the ratio of quadratic normal variables Usually, random permutation would do the job Global and local (1) The Moran’s I just introduced are based on simultaneous measurements from many locations – hence, it is a GLOBAL statistics Global statistics provides only a limited set of spatial association measurements You see the pattern, details are ignored – tree and forest dilemma Global and local (2) Recently, a number of statistics have been developed to measure dependence in portion of the study area – the local statistics In spatial data analysis, the name is Local Index of Spatial Association (LISA) by Anselin (1995) Global and local (3) Definition of LISA (Anselin, 1995) The local statistics for each observation gives an indication of the extent of significant spatial clustering of similar values around that observation The sum of local statistics for all observation is proportional (or equal) to a corresponding global statistics Global and local (4) Local statistics are well suited to Identify existence of pockets or “hot spots” Assess assumptions of stationarity Identify distances beyond which no discernible association obtains Global and local statistics are often used together for thorough understanding of spatial association and processes Global and local (5) This discussion is based on the decomposition of the Moran’s I to its local version Others can be done similarly, however, there is an important aspects of Moran’s I that will assist further understanding in spatial analysis It can be decomposed into its local version, AND a graphic version – Moran’s scatterplot Local Moran’s I Following Anselin’s (1995) definition, a local Moran’s Ii may be defined as: n I i zi wij z j j zis are the deviations from the mean of yis The weights are row standardized Local Moran’s I Hypothesis test for local Moran’s I is more complex The distribution of local Moran’s I is definitely not normal, furthermore, local Moran’s I’s distribution is influenced by the global pattern Random permutation won’t work – for one specific location, during the permutation, the local Moran’s I’s mean and variance keep changing – which is not the case for global one Local Moran’s I Exact distribution of local Moran’s I can be obtained, but extremely computationally prohibitive Saddlepoint approximation currently is thus far one potential resolution Details can be found at Tiefelsdorf (2000; 2002) Local Moran’s I In addition, local Moran’s Is correlate with one another due to overlapping neighbors Bonferroni correction or other correction methods are needed for acquiring robust testing results These are all done in the SPDEP package in R Moran’s scatterplot A graphic tool for detecting local spatial association Derived directly from the global Moran’s I It can be used together with the local Moran’s I for better understanding Moran’s scatterplot Recall the formula of Moran’s I: n I n w ij i j w ij n n n i ( y i y )( y j y ) j n (y i y) 2 i If use row standardized weights matrix the first term will be 1 Moran’s scatterplot Therefore, I could be re-written as: n n w ij I i ( yi y )( y j y ) j n (y y) i 2 i Or: n I (y n i y )( wij ( y j y )) i j n 2 ( y y ) i i Moran’s scatterplot Recall the coefficient of the linear regression, b: n b (ind i ind )( depi dep) i n 2 ( ind ind ) i i indi and depi are the independent and dependent variables; the “bar” versions are their means, respectively; and b is the regression coefficient Moran’s scatterplot Yes, similarity between the Moran’s I and the regression coefficient b n Actually, ( wij ( y j y )) is the so-called j “spatial lag” of location i. So, I is formally equivalent to a regression coefficient in a regression of a location’s spatial lag on itself Moran’s Scatterplot This interpretation enables us to visualize Moran’s I in a scatterplot of a location’s spatial lag and itself – the Moran’s scatterplot Moran’s I is the slope of the regression line A lack of fit (in the scatterplot) would indicate important local spatial process and associations (local pockets/non-stationarity) Moran’s scatterplot The scatterplot is centered on the coordinate Origin The first and third quadrants of the plot represent positive association (high-high and low-low), while the second and fourth negative (high-low, low-high) The density of the quadrants represent the dominating local spatial process Moran’s scatterplot A so-called LOWESS (LOcally Weighted rEgression Scatterplot Smoothing) curve can aid the visual effects Turning of the LOWESS curve usually indicates interesting local pockets, regimes or non-stationarity An example: demonstration in R More about Moran’s Scatterplot A very important ESDA tools for spatial data analysis Further information could be obtained from: The Moran Scatterplot as an ESDA tool to assess local instability in spatial association. pp. 111–125 in M. M. Fischer, H. J. Scholten and D. Unwin (eds.) Spatial analytical perspectives on GIS, London: Taylor and Francis An analytical example Spatial pattern detection in China’s provincial development The variable used: per capita GDP Dynamic patterns – global Moran’s I Specific local spatial process – local Moran’s I and the Moran’s scatterplot China: per capita GDP in 1978 Central Region Western Region Eastern Region Yuan 175 - 291 292 - 430 0 250 500 1,000 431 - 680 Miles 681 - 1290 0 500 1,000 2,000 Kilometers 1291 - 2498 China: per capita GDP in 2000 Central Region Western Region Eastern Region Yuan 869 - 1913 1914 - 3162 0 250 500 1,000 3163 - 4532 Miles 4533 - 8411 0 500 1,000 2,000 Kilometers 8412 - 15593 An analytical example Global Moran's I 0.25 0.2 0.15 0.1 0.05 Dynamic change of global Moran’s I from 1978 to 2000, all are significant at 5% level per random permutation 0 2000 1999 1998 1997 1996 1995 1994 1993 1992 1991 1990 1989 1988 1987 1986 1985 1984 1983 1982 1981 1980 1979 1978 Year An analytical example There is a clustering trend in China’s provincial level development (represented by per capita GDP But the global Moran’s I can’t tell on which side does the clustering trend take place: high values cluster or low values cluster? 3.0 JS TJ BJ ZJ 2.0 HeB 1.0 JL NMG XJ HaN 0.0 SH GS FJ SX HeN AH SSX S DQH SC JX NX XZ GD HuN HuB GX YN GZ -1.0 -1 0 HLJLN The Moran’s scatterplot in 1978 1 2 3 4 5 GDP per capita (standardized) 3 JS TJ ZJ 2 BJ HaN SH HeB 1 FJ AH JX JL SD SX LN GD NMG HeN HLJ GX HuN SSX NX QH GS XJHuB SC XZ GZ YN 0 -1 The Moran’s scatterplot in 2000 -2 -1 0 1 2 3 4 5 GDP per capita (standardized) Local Moran’s I in 1978 Central Region Western Region Eastern Region Local Moran's I < - 0.3 - 0.3 - 0 0 250 500 1,000 0 - 0.3 Miles 0.3 - 1.0 0 500 1,000 2,000 Kilometers > 1.0 Local Moran’s I in 2000 Central Region Western Region Eastern Region Local Moran's I - 0.3 - 0 0 250 500 1,000 0 - 0.3 Miles 0.3 - 1.0 0 500 1,000 2,000 Kilometers > 1.0 An analytical example First, China’s coast-interior divide persisted Interior provinces exhibit great geographical similarity in economic development and spatial contributions to the global Moran’s I Second, the municipalities (Beijing, Tianjin, Shanghai) always contribute the most Shanghai’s position is worth noting, it development changed the spatial pattern the most An analytical example Third, Guangdong’s contribution to the global index corresponds with its changing spatial behavior depicted in the Moran scatterplot Fourth, while most of the interior provinces have similar patterns, coastal provinces vary greatly An analytical example Fifth, Shandong fell into the low-low quadrant, and contributed very little to the global index Sixth, Guizhou and Yunnan, two provinces in southwest China, contributed relatively highly to the global index in 2000 The poorest ones tend to form a poor cluster Demo – with R and SPDEP A little demonstration The software package R: freeware, powerful, open source Packages: SPDEP and MAPTOOLS If you have spatial data and interested in utilizing ESDA, you can approach me for your research