Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Microsoft SQL Server wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Ingres (database) wikipedia , lookup
Functional Database Model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Clusterpoint wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Database model wikipedia , lookup
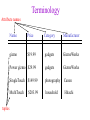
CSE 326: Data Structures Lecture #22 Databases and Sorting Alon Halevy Spring Quarter 2001 Agenda • Reminisce about Project 3. • A bit on graphs. • Get excited about Project 4 (short course on databases) • Start talking about sorting. Database Systems • Enable you to manage large (huge) amounts of data: – Store the data efficiently – Pose complex queries on the data in a high-level language (e.g., SQL) – Enable concurrent access to the data by many users. – Embed database queries into application programs. • The market: mostly relational databases. Terminology Attribute names tuples Name Price Category Manufacturer gizmo $19.99 gadgets GizmoWorks Power gizmo $29.99 gadgets GizmoWorks SingleTouch $149.99 photography Canon MultiTouch household Hitachi $203.99 More Terminology Every attribute has an atomic type. Relation Schema: relation name + attribute names + attribute types Relation instance: a set of tuples. Only one copy of any tuple! Database Schema: a set of relation schemas. Database instance: a relation instance for every relation in the schema. Querying a Database • The query language enables performing relational operators: – Selection (select a subset of the tuples from a table) – Projection (select a subset of the columns) – Join (match up two tables on certain attributes) – Union, negation, aggregation, etc., etc. • Operations take table(s) as input and produce a table. • SQL manual is a very effective doorstop. Selection • Produce a subset of the tuples in a relation which satisfy a given condition • Unary operation… returns set with same attributes, but ‘selects’ rows • Use and, or, not, >, <… to build condition • Find all employees with salary more than $40,000: Selection Example Employee SSN 999999999 777777777 888888888 Name John Tony Alice DepartmentID 1 1 2 Salary 30,000 32,000 45,000 Find all employees with salary more than $40,000. SSN Name 888888888 Alice DepartmentID 2 Salary 45,000 Projection • Unary operation, selects columns • Eliminates duplicate tuples • Example: project social-security number and names. Projection Example Employee SSN 999999999 777777777 888888888 Name John Tony Alice SSN 999999999 777777777 888888888 Name John Tony Alice DepartmentID 1 1 2 Salary 30,000 32,000 45,000 Join (Natural) • Most important, expensive and exciting. • Combines two relations, selecting only related tuples • Resulting schema has all attributes of the two relations, but one copy of join condition attributes Join Example Employee Name John Tony SSN 999999999 777777777 Dependents EmployeeSSN 999999999 777777777 Dname Emily Joe Employee_Dependents Dname SSN Name 999999999 Emily John 777777777 Joe Tony Step 1 • Read the schema (format given). • Create the data structure to store tables. • Read the data (each table is in a separate file, tuple per line). Step 2 • Read the query. The form is: • • • • Select attributes From Tables Where selection conditions, join conditions. Order By: attribute • Note: no Cartesian products, may join two tables on more than one attribute. • Dirty hack for self joins. Step 3 • Execute the query. • Perform all joins (each join creates and intermediate table). • Perform selections • Perform projections • Order the output (if necessary) Notes on Mechanics • Groups of 3-4 students. Send email to Maya, Nic and Alon by Monday, the 21st . • Hash join (explained in section yesterday). • Grading: demos (15 minutes per group) + 2-page writeup. • Dates? • You have a lot of freedom in this project. You’ll have to make a lot of choices on your own. • Data (about you) • Help: all of us + Peter Mork (pmork@cs) • Homework 5 turn-in. Sorting • Given a set of N numbers, put them in order. • We’ll see several algorithms for comparison sort: – – – – Insertion sort Merge sort Quicksort Heap sort. • How well can we expect to do?? What is the minimum # of comparisons that any algorithm could do. Decision tree to sort list A,B,C B<A A<B B<A A<B B,A,C. A A,C,B. C,A,B. facts Legend A,B,C C<A C B< B,C,A. B<A C<A C<B C< C A< A<B C<B A B A,B,C. C< C A< C< C B< C,B,A Internal node, with facts known so far Leaf node, with ordering of A,B,C Edge, with result of one comparison Max depth of the decision tree • How many permutations are there of N numbers? • How many leaves does the tree have? • What’s the shallowest tree with a given number of leaves? • What is therefore the worst running time (number of comparisons) by the best possible sorting algorithm? Stirling’s approximation n n! 2n e n n n log(n !) log 2 n e n n log( 2 n ) log (n log n) e