Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
International Computer Institute, Izmir, Turkey
Database Design and Normal Forms
Asst.Prof.Dr.İlker Kocabaş
UBİ502 at http://ube.ege.edu.tr/~ikocabas
Database Design and Normal Forms
First Normal Form
Functional Dependencies
Decomposition
Boyce-Codd Normal Form
Database Design Process
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.2 of 56
Modifications & additions by Cengiz Güngör
First Normal Form
A domain is atomic if its elements are considered to be
indivisible units
Examples of non-atomic domains:
• Set-valued attributes, composite attributes
• Identifiers like UBİ502 that can be broken up into parts
A relational schema R is in first normal form if the domains of all
attributes of R are atomic
Non-atomic values
complicate storage
encourage redundancy
interpretation of non-atomic values built into application
programs
• $cid = substring( $result [ “course-id” ], 1, 3 );
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.3 of 56
Modifications & additions by Cengiz Güngör
First Normal Form (cont)
Atomicity: not an intrinsic property of the elements of the domain
Atomicity is a property of how the elements of the domain are
used
E.g. strings containing a possible delimiter (here: space)
• cities = “Melbourne Sydney”
(non-atomic: space separated list)
• surname = “Fortescue Smythe” (atomic: compound surname)
E.g. strings encoding two separate fields
• student_id = CS1234
• If the first two characters are extracted to find the department,
the domain of student identifiers is not atomic
• leads to encoding of information in application program rather
than in the database
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.4 of 56
Modifications & additions by Cengiz Güngör
Pitfalls (Traps) in Relational Database Design
Relational database design requires that we find a
“good” collection of relation schemas
A bad design may lead to
redundant information
difficulty in representing certain information
difficulty in checking integrity constraints
Design Goals:
Avoid redundant data
Ensure that relationships among attributes are
represented
Facilitate the checking of updates for violation of
integrity constraints
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.5 of 56
Modifications & additions by Cengiz Güngör
Example of Bad Design
Consider the relation schema:
Lending-schema = (branch-name, branch-city, assets,
customer-name, loan-number, amount)
Redundant Information:
Data for branch-name, branch-city, assets are repeated for each loan that
a branch makes
Wastes space and complicates updates, introducing possibility of
inconsistency of assets value
Difficulty representing certain information:
Cannot store information about a branch if no loans exist
Can use null values, but they are difficult to handle
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.6 of 56
Modifications & additions by Cengiz Güngör
Solution: Decomposition
Break up such redundant tables into multiple tables
this operation is called decomposition
E.g. consider Lending-schema again:
Lending-schema = (branch-name, branch-city, assets,
customer-name, loan-number, amount)
now decompose as follows:
Branch-schema = (branch-name, branch-city,assets)
Loan-info-schema = (customer-name, loan-number,
branch-name, amount)
Want to ensure that the original data is recoverable
1. all attributes of the original schema (R) must appear
in the decomposition (R1, R2), i.e. R = R1 R2
2. decomposition must be a lossless-join decomposition
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.7 of 56
Modifications & additions by Cengiz Güngör
Lossless-Join Decomposition: Definition
Let R, R1, R2 be schemas and where R = R1 R2
R1, R2 is a lossless-join decomposition of R
if, for all possible relations r(R)
r = R1 ( r ) ⋈ R2 ( r )
Here “possible” means “meaningful in the context of the
particular database design”
we will formalize this notion using functional
dependencies
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.8 of 56
Modifications & additions by Cengiz Güngör
Lossless-Join Decomposition: Example
Example of Non Lossless-Join Decomposition
Decomposition of R = (A, B)
R2 = (A)
R2 = (B)
A B
A
B
A
B
1
2
A ( r )
B ( r )
1
2
1
2
1
2
1
r
A ( r ) ⋈ B ( r )
Thus, r is different to A (r) ⋈ B (r)
and so A,B is not a lossless-join
decomposition of R.
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.9 of 56
Modifications & additions by Cengiz Güngör
Goal — Formalize the notion of good design
Process:
Decide whether a particular relation R is in “good” form.
In the case that a relation R is not in “good” form, decompose
it into a set of relations {R1, R2, ..., Rn} such that
• each relation is in good form
• the decomposition is a lossless-join decomposition
Our theory is based on functional dependencies
Constraints on the set of legal relations
Require that the value for a certain set of attributes determines
uniquely the value for another set of attributes
generalizes the notion of a key
Functional dependencies allow us to formalize good database
design
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.10 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies: Definition
Let R be a relation schema
R and R
The functional dependency (FD) holds on R iff
for any legal relations r(R)
whenever any two tuples t1 and t2 of r agree on the attributes
they also agree on the attributes
i.e. ( t1 ) = ( t2 ) ( t1 ) = ( t2 )
Example: Consider r(A,B) with the following instance of r:
1
1
3
4
5
7
On this instance, A B does NOT hold, but B A does hold
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.11 of 56
Modifications & additions by Cengiz Güngör
Functional Dependency : Another Definition
A functional dependency occurs when the value of
one (set of) attribute(s) determines the value of a
second (set of) attribute(s):
StudentID StudentName
StudentID (DormName, DormRoom, Fee)
The attribute on the left side of the functional
dependency is called the determinant.
Functional dependencies may be based on equations:
ExtendedPrice = Quantity X UnitPrice
(Quantity, UnitPrice) ExtendedPrice
Function dependencies are not equations!
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.12 of 56
Modifications & additions by Cengiz Güngör
Composite Determinants
Composite determinant = a determinant of a functional
dependency that consists of more than one attribute
(StudentName, ClassName) (Grade)
Functional Dependency Rules
If A (B, C), then A B and A C.
If (A,B) C, then neither A nor B determines C by itself.
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.13 of 56
Modifications & additions by Cengiz Güngör
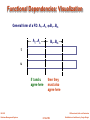
Functional Dependencies: Visualization
General form of a FD: A1...An B1...Bm
A1...An
B1...Bm
if t and u
agree here
then they
must also
agree here
t
u
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.14 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies vs Keys
FDs can express the same constraints we could express using
keys:
Superkeys:
K is a superkey for relation schema R if and only if K R
Candidate keys:
K is a candidate key for R if and only if
• K R, and
• there is no K’ K such that K’ R
However,FDs are more general
i.e. we can express constraints that cannot be expressed using
keys
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.15 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies vs Keys (cont)
Example of FDs that can’t be represented using keys:
Consider the following Loan-info-schema:
Loan-info-schema = (customer-name, loan-number,
branch-name, amount).
We expect these FDs to hold:
loan-number amount
loan-number branch-name
We could try to express this by making loan-number the key,
however the following FD does not hold:
loan-number customer-name
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.16 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies (cont)
Movies(title, year, length, studioName, starName)
title
year
length
studioName
starName
Star Wars
1977
124
Fox
Carrie Fisher
Star Wars
1977
124
Fox
Harrison Ford
Mighty Ducks
1991
104
Disney
Emilio Estevez
Wayne’s World
1992
95
Paramount
Dana Carvey
Wayne’s World
1992
95
Paramount
Mike Meyers
FD: title, year length, studioName
not an FD: title, year starName
candidate key, a minimal K such that K R
propose: K = {title, year, starName}
check: does K functionally determine R?
to answer this question we’ll need to look at closures
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.17 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies (cont)
An FD is an assertion about a schema, not an instance
If we only consider an instance, we can’t tell if an FD holds
e.g. inspecting the movies relation, we might suggest that
length title, since no two films in the table have the same
length
However, we cannot assert this FD for the movies relation,
since we know it is not true of the domain in general
Thus, identifying FDs is part of the data modelling process
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.18 of 56
Modifications & additions by Cengiz Güngör
Modification Anomalies
Deletion anomaly
Insertion anomaly
Update anomaly
Movies(title, year, length, studioName, starName)
title
year
length
studioName
starName
Star Wars
1977
124
Fox
Carrie Fisher
Star Wars
1977
124
Fox
Harrison Ford
Mighty Ducks
1991
104
Disney
Emilio Estevez
Wayne’s World
1992
95
Paramount
Dana Carvey
Wayne’s World
1992
95
Paramount
Mike Meyers
Update lenght on Row-1 is an anomaly, two different lenghts are
recorded.
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.19 of 56
Modifications & additions by Cengiz Güngör
Normal Forms
Relations are categorized as a normal form
based on which modification anomalies or other
problems they are subject to:
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.20 of 56
Modifications & additions by Cengiz Güngör
Normal Forms
1NF—a table that qualifies as a relation is in 1NF.
2NF—a relation is in 2NF if all of its non-key attributes
are dependent on all of the primary keys.
3NF—a relation is in 3NF if it is in 2NF and has no
determinants except the primary key.
Boyce-Codd Normal Form (BCNF)—a relation is in
BCNF if every determinant is a candidate key.
“I swear to construct my tables so that all non-key
columns are dependent on the key, the whole key
and nothing but the key, so help me Codd.”
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.21 of 56
Modifications & additions by Cengiz Güngör
Eliminating Modification Anomalies from
Functional Dependencies in Relations:
Put All Relations into BCNF
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.22 of 56
Modifications & additions by Cengiz Güngör
Functional Dependencies: Uses
We use FDs to:
test relations to see if they are legal under a given set of FDs
•
If a relation r is legal under a set F of FDs, we say that r satisfies F
specify constraints on the set of legal relations
• We say that F holds on R if all legal relations on R satisfy the set of
FDs F
Note: A specific instance of a relation schema may satisfy an FD
even if the FD does not hold on all legal instances.
For example, a specific instance of Loan-schema may, by
chance, satisfy
loan-number customer-name
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.23 of 56
Modifications & additions by Cengiz Güngör
Aside: Trivial Functional Dependencies
An FD is trivial if it is satisfied by all instances of a relation
E.g.
•
customer-name, loan-number customer-name
•
customer-name customer-name
In general, is trivial if
Permitting such FDs makes certain definitions and algorithms
easier to state
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.24 of 56
Modifications & additions by Cengiz Güngör
FD Closure: Definition
Given a set F of fds, there are other FDs logically implied by F
E.g. If A B and B C, then we can infer that A C
The set of all FDs implied by F is the closure of F, written F+
We can find all of F+ by applying Armstrong’s Axioms:
if , then
(reflexivity)
if , then
(augmentation)
if , and , then (transitivity)
Additional rules (derivable from Armstrong’s Axioms):
If holds and holds, then holds (union)
If holds, then holds and holds
(decomposition)
If holds and holds, then holds
(pseudotransitivity)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.25 of 56
Modifications & additions by Cengiz Güngör
FD Closure: Example
R = (A, B, C, G, H, I)
F={ AB
AC
CG H
CG I
B H}
some members of F+
AH
• by transitivity from A B and B H
AG I
• by augmenting A C with G, to get AG CG
and then transitivity with CG I
CG HI
• by union rule with CG H and CG I
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.26 of 56
Modifications & additions by Cengiz Güngör
Computing FD Closure
To compute the closure of a set of FDs F:
F+ = F
repeat
for each FD f in F+
apply reflexivity and augmentation rules on f
add the resulting FDs to F+
for each pair of FDs f1and f2 in F+
if f1 and f2 can be combined using transitivity
then add the resulting FD to F+
until F+ does not change any further
(NOTE: More efficient algorithms exist)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.27 of 56
Modifications & additions by Cengiz Güngör
Minimal Cover of an FD Set
The opposite of closure: what is the “minimal” set of FDs
equivalent to F, having no redundant FDs (or extraneous
attributes)
Sets of FDs may have redundant FDs that can be inferred from
the others
Eg: A C is redundant in: {A B, B C, A C}
Parts of an FD may be redundant
• E.g. on RHS:
{A B, B C, A CD} can be simplified to
{A B, B C, A D}
• E.g. on LHS:
{A B, B C, AC D} can be simplified to
{A B, B C, A D}
(We’ll cover these later under the heading of extraneous attributes)
(NB Textbook calls this “canonical” cover, though there is no
guarantee of uniqueness.)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.28 of 56
Modifications & additions by Cengiz Güngör
Closure of Attribute Sets
Given a set of attributes , define the closure of under F
(denoted by +) as the set of attributes that are functionally
determined by under F:
is in F+ +
Algorithm to compute +, the closure of under F
result := ;
while (changes to result) do
for each in F do
begin
if result then result := result
end
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.29 of 56
Modifications & additions by Cengiz Güngör
Closure of Attribute Sets: Example
R = (A, B, C, G, H, I)
F = {A B
AC
CG H
CG I
B H}
(AG)+
1. result = AG
2. result = ABCG
(A C and A B)
3. result = ABCGH
(CG H and CG AGBC)
4. result = ABCGHI
(CG I and CG AGBCH)
Is AG a candidate key?
1. Is AG a superkey?
1. Does AG R? == Is (AG)+ R
2. Is any subset of AG a superkey?
1. Does A R? == Is (A)+ R
2. Does G R? == Is (G)+ R
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.30 of 56
Modifications & additions by Cengiz Güngör
Closure of Attribute Sets: Uses
Testing for superkey:
To test if is a superkey, we compute +, and check if +
contains all attributes of R
Testing FDs
To check if a FD holds (or, in other words, is in F+), just
check if +
i.e. compute + by using attribute closure, and then check if it
contains
Is a simple and cheap test, and very useful
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.31 of 56
Modifications & additions by Cengiz Güngör
Extraneous Attributes
Recall that we could have redundant FDs. Parts of FDs can
also be redundant
Consider a set F of FDs and the FD in F.
Attribute A is extraneous in if A
and F logically implies (F – { }) {( – A) }.
Attribute A is extraneous in if A
and the set of functional dependencies
(F – { }) { ( – A)} logically implies F.
Example: Given F = {A C, AB C }
B is extraneous in AB C because {A C, AB C}
logically implies A C (I.e. the result of dropping B from AB
C).
Example: Given F = {A C, AB CD}
C is extraneous in AB CD since AB C can be inferred
even after deleting C
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.32 of 56
Modifications & additions by Cengiz Güngör
Decomposition
Decompose the relation schema Lending-schema into:
Branch-schema = (branch-name, branch-city, assets)
Loan-info-schema = (customer-name, loan-number,
branch-name, amount)
All attributes of an original schema (R) must appear in the
decomposition (R1, R2):
R = R1 R2
Lossless-join decomposition.
For all possible relations r on schema R
r = R1 (r) ⋈ R2 (r)
A decomposition of R into R1 and R2 is lossless-join if and only if
at least one of the following dependencies is in F+:
R1 R2 R1
R1 R2 R2
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.33 of 56
Modifications & additions by Cengiz Güngör
Decomposition Using Functional Dependencies
When we decompose a relation schema R with a set of
FDs F into R1, R2,.., Rn we want
1. Lossless-join decomposition: Otherwise decomposition would
result in information loss
2. No redundancy: The relations Ri should be in BCNF
3. Dependency preservation: Let Fi be the set of FDs F+ that include
only attributes in Ri
Preferably the decomposition should be dependency preserving,
that is, (F1 F2 … Fn)+ = F+
Otherwise, checking updates for violation of FDs may require
computing joins, which is expensive
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.34 of 56
Modifications & additions by Cengiz Güngör
Example
R = (A, B, C)
F = {A B, B C)
Can be decomposed in two different ways
R1 = (A, B), R2 = (B, C)
Lossless-join decomposition:
R1 R2 = {B} and B BC
Dependency preserving
R1 = (A, B), R2 = (A, C)
Lossless-join decomposition:
R1 R2 = {A} and A AB
Not dependency preserving
(cannot check B C without computing R1 ⋈ R2)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.35 of 56
Modifications & additions by Cengiz Güngör
Summary
First Normal Form
Functional Dependencies
Decomposition
to eliminate redundancy
lossless-join
dependency preserving
Next Up:
Boyce-Codd Normal Form
Database Design Process
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.36 of 56
Modifications & additions by Cengiz Güngör
Boyce-Codd Normal Form (BCNF)
A relation schema R is in BCNF with respect to a set F of FDs if
for all FDs in F+ of the form
where R and R
at least one of the following holds:
is trivial (i.e., ), or
is a superkey for R
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.37 of 56
Modifications & additions by Cengiz Güngör
Example
R = (A, B, C)
F = {A B
B C}
Key = {A}
R is not in BCNF
Decomposition R1 = (A, B), R2 = (B, C)
R1 and R2 in BCNF
Lossless-join decomposition
Dependency preserving
Question: How do we decompose a schema to get BCNF
schemas in the general case?
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.38 of 56
Modifications & additions by Cengiz Güngör
BCNF Decomposition
First, we need a method to check if a non-trivial dependency
on R violates BCNF
1. compute + (the attribute closure of ), and
2. verify that it includes all attributes of R
ie. + is a superkey of R
3. if not, then violates BCNF
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.39 of 56
Modifications & additions by Cengiz Güngör
BCNF Decomposition Algorithm
result := {R};
done := false;
compute F+;
while (not done) do
if (there is a schema Ri in result that is not in BCNF)
then begin
let be a nontrivial functional
dependency that holds on Ri
such that Ri is not in F+,
and = ;
result := (result – Ri ) (Ri – ) (, );
end
else done := true;
Note: each Ri is in BCNF, and decomposition is lossless-join
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.40 of 56
Modifications & additions by Cengiz Güngör
Example of BCNF Decomposition
R = (branch-name, branch-city, assets,
customer-name, loan-number, amount)
F = {branch-name assets branch-city
loan-number amount branch-name}
Key = {loan-number, customer-name}
Is R in BCNF?
Are there non-trivial FDs in which the LHS is not a superkey?
FD: branch-name assets branch-city
• Is branch-name a superkey? (no)
FD: loan-number amount branch-name
• Is loan-number a superkey? (no)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.41 of 56
Modifications & additions by Cengiz Güngör
Example of BCNF Decomposition (cont)
R = (branch-name, branch-city, assets,
customer-name, loan-number, amount)
F = {branch-name assets branch-city
loan-number amount branch-name}
BCNF Decomposition
consider FD branch-name assets branch-city
• = branch-name,
= assets branch-city
• result := (result – Ri ) (Ri – ) (,
);
Replace R with and R-
• R1: = (branch-name, assets, branch-city)
• R2: R- = (branch-name, customer-name, loan-number,
amount)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.42 of 56
Modifications & additions by Cengiz Güngör
Example of BCNF Decomposition (cont)
R1 = (branch-name, assets, branch-city)
R2 = (branch-name, customer-name, loan-number, amount)
F = {branch-name assets branch-city
loan-number amount branch-name}
R1 is in BCNF, R2 is not in BCNF
BCNF Decomposition
consider FD loan-number amount branch-name
= loan-number, = amount branch-name
Replace R2 with and R2-
• R3: = (branch-name, loan-number, amount)
• R4: R- = (customer-name, loan-number)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.43 of 56
Modifications & additions by Cengiz Güngör
Example of BCNF Decomposition (cont)
R1 = (branch-name, assets, branch-city)
R3 = (branch-name, loan-number, amount)
R4 = (customer-name, loan-number)
F = {branch-name assets branch-city
loan-number amount branch-name}
All relations are now BCNF!
Why does it work – i.e. why is this a lossless-join
decomposition?
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.44 of 56
Modifications & additions by Cengiz Güngör
Why are BCNF Decompositions
lossless-join?
A1...An B1...Bm
For every combination
R
B’s
B’s
R1
A’s
A’s
others
So put the B’s in a
others
R2
UBI 502
Database Management Systems
of A’s with others, we
repeat the B’s
separate table R1, for
which the A’s are keys,
and put the remainder
in R2
©Silberschatz, Korth and Sudarshan
8.45 of 56
Modifications & additions by Cengiz Güngör
Why are BCNF Decompositions
lossless-join? (cont)
r = R1 (r) ⋈ R2 (r) ?
Consider R = (A,B,C), FD B C not in BCNF
BCNF decomposition gives us: R1 = (B, C), R2 = (A, B)
Do we lose any tuples in R1 (r) ⋈ R2 (r) ?
Let t = (a,b,c) be a tuple in r
t projects as (b,c) for R1 and (a,b) for R2
joining these tuples gives us t back again
thus, we don’t lose any tuples, and so r is contained in R1 (r) ⋈ R2 (r)
Do we gain any tuples in R1 (r) ⋈ R2 (r) ?
Let t = (a,b,c) and u = (d,b,e) be tuples in r
By projecting and joining them, can we create (a,b,e) or (d,b,c)?
Since B C we know that c=e
So we can’t create any tuple we didn’t already have
Thus, the FD ensures r contains R1 (r) ⋈ R2 (r)
Therefore r = R1 (r) ⋈ R2 (r)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.46 of 56
Modifications & additions by Cengiz Güngör
BCNF and Dependency Preservation
It is not always possible to get a BCNF decomposition that is
dependency preserving
R = (J, K, L)
F = {JK L
L K}
Two candidate keys = JK and JL
R is not in BCNF
Any decomposition of R will fail to preserve
JK L
Two solutions:
test FDs across relations
use Third Normal Form
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.47 of 56
Modifications & additions by Cengiz Güngör
Testing for FDs Across Relations
Suppose that is a dependency not preserved in a
decomposition
Create a new materialized view for
The materialized view is defined as a projection on of the
join of the relations in the decomposition
Many database systems support materialized views
No extra coding effort for programmer
Declare as a candidate key on the materialized view
Checking for candidate key is cheaper than checking
The down-side:
Space overhead: for storing the materialized view
Time overhead: Need to keep materialized view up to date
Database system may not support key declarations on
materialized views
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.48 of 56
Modifications & additions by Cengiz Güngör
Aside 1: Third Normal Form
There are some situations where
BCNF is not dependency preserving, and
efficient checking for FD violations is important
Solution: define a weaker normal form, called Third Normal Form.
Allows some redundancy
FDs can be checked on individual relations without computing
any joins
There is always a lossless-join, dependency-preserving
decomposition into 3NF
Details are beyond the scope of this course
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.49 of 56
Modifications & additions by Cengiz Güngör
Aside 2: SQL Support for FDs
SQL does not provide a direct way of specifying functional
dependencies other than superkeys
Can specify FDs using assertions
assertions must express the following type of constraint
(t1) = (t2) (t1) = (t2)
these are expensive to test (especially if LHS of FD not a key)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.50 of 56
Modifications & additions by Cengiz Güngör
Design Goals
Goal for a relational database design is:
eliminate redundancies by decomposing relations
must be able to recover original data using lossless joins
BCNF:
no redundancies
no guarantee of dependency preservation
(3NF: dependency preservation, but redundancies)
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.51 of 56
Modifications & additions by Cengiz Güngör
Overall Database Design Process
We have assumed schema R is given
R could have been generated when converting E-R diagram to a
set of tables.
R could have been a single relation containing all attributes that
are of interest (called universal relation).
Normalization breaks R into smaller relations.
R could have been the result of some ad hoc design of relations,
which we then test/convert to normal form.
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.52 of 56
Modifications & additions by Cengiz Güngör
E-R Model and Normalization
When an E-R diagram is carefully designed, identifying all entities
correctly, the tables generated from the E-R diagram should not need
further normalization
However, in a real (imperfect) design there can be FDs from non-key
attributes of an entity to other attributes of the entity
The keys identified in our E-R diagram might not be minimal (only FDs
force us to identify minimal keys)
E.g. employee entity with attributes department-number and
department-address, and an FD department-number departmentaddress
Good design would have made department an entity
FDs from non-key attributes of a relationship set are possible, but rare
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.53 of 56
Modifications & additions by Cengiz Güngör
Denormalization for Performance
May want to use non-normalized schema for performance
E.g. displaying customer-name along with account-number and
balance requires join of account with depositor
Alternative 1: Use denormalized relation containing attributes of
account as well as depositor with all above attributes
faster lookup
extra space and extra execution time for updates
extra coding work for programmer and possibility of error in
extra code
Alternative 2: use a materialized view defined as
account ⋈ depositor
benefits and drawbacks same as above, except no extra coding
work for programmer and avoids possible errors
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.54 of 56
Modifications & additions by Cengiz Güngör
Other Design Issues
Some aspects of database design are not caught by
normalization
Examples of bad database design, to be avoided:
E.g suppose that, instead of earnings(company-id, year,
amount), we used:
earnings-2000, earnings-2001, earnings-2002, etc., all on the
schema (company-id, earnings)
• all are BCNF, but make querying across years difficult
• needs a new table each year
company-year(company-id, earnings-2000,
earnings-2001, earnings-2002)
• in BCNF, but makes querying across years difficult
• requires new attribute each year
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.55 of 56
Modifications & additions by Cengiz Güngör
Summary
Functional Dependencies and Decomposition help us achieve
our design goals:
Avoid redundant data
Ensure that relationships among attributes are represented
Facilitate the checking of updates for violation of integrity
constraints
UBI 502
Database Management Systems
©Silberschatz, Korth and Sudarshan
8.56 of 56
Modifications & additions by Cengiz Güngör