Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Scalable Information Extraction
Eugene Agichtein
1
Example: Angina treatments
guideline for unstable angina
unstable angina management
herbal treatment for angina pain
medications for treating angina
alternative treatment for angina pain
treatment for angina
angina treatments
Structured databases
(e.g., drug info, WHO drug
adverse effects DB, etc)
MedLine
PDR
Medical reference
and literature
Web search results
2
Research Goal
Accurate, intuitive, and efficient access
to knowledge in unstructured sources
Approaches:
Information Retrieval
Human Reading
Retrieve the relevant documents or passages
Question answering
Construct domain-specific “verticals” (MedLine)
Machine Reading
Extract entities and relationships
Network of relationships: Semantic Web
3
Semantic Relationships “Buried” in Unstructured Text
…
A number of well-designed and executed large-scale clinical trials have
now shown that treatment with statins
reduces recurrent myocardial infarction,
reduces strokes, and lessens the need
for revascularization or hospitalization
for unstable angina pectoris
…
RecommendedTreatment
Drug
Condition
statins
recurrent myocardial
infarction
statins
strokes
statins
unstable angina
pectoris
Web, newsgroups, web logs
Text databases (PubMed, CiteSeer, etc.)
Newspaper Archives
Corporate mergers, succession, location
Terrorist attacks
]
M essage
U nderstanding
C onferences
4
What Structured Representation
Can Do for You:
Large Text Collection
Structured Relation
… allow precise and efficient querying
… allow returning answers instead of documents
… support powerful query constructs
… allow data integration with (structured)
RDBMS
… provide useful content for Semantic Web
5
Challenges in Information Extraction
Portability
Scalability, Efficiency, Access
Reduce effort to tune for new domains and tasks
MUC systems: experts would take 8-12 weeks to tune
Enable information extraction over large collections
1 sec / document * 5 billion docs = 158 CPU years
Approach: learn from data ( “Bootstrapping” )
Snowball: Partially Supervised Information Extraction
Querying Large Text Databases for Efficient Information Extraction
6
Outline
Snowball: partially supervised information
extraction (overview and key results)
Effective retrieval algorithms for information
extraction (in detail)
Current: mining user behavior for web search
Future work
7
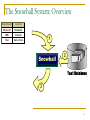
The Snowball System: Overview
Organization
Location
Conf
Microsoft
Redmond
1
IBM
Armonk
1
Intel
Santa Clara
1
AG Edwards
St Louis
0.9
Air Canada
Montreal
0.8
7th Level
Richardson
0.8
3Com Corp
Santa Clara
0.8
3DO
Redwood City
0.7
3M
Minneapolis
0.7
MacWorld
San Francisco
0.7
...
...
..
157th Street
Manhattan
0.52
15th Party
Congress
China
0.3
15th Century
Europe
Dark Ages
0.1
1
Snowball
2
Text Database
3
8
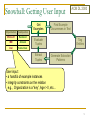
Snowball: Getting User Input
Get
Examples
Organization
Headquarters
Microsoft
Redmond
IBM
Armonk
Intel
Santa Clara
Find Example
Occurrences in Text
Evaluate
Tuples
Extract
Tuples
ACM DL 2000
Tag
Entities
Generate Extraction
Patterns
User input:
• a handful of example instances
• integrity constraints on the relation
e.g., Organization is a “key”, Age > 0, etc…
9
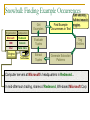
Snowball: Finding Example Occurrences
Can use any
Get
Examples
Find Example
Occurrences in Text
full-text search
engine
Organization Headquarters
Microsoft
Redmond
IBM
Armonk
Intel
Santa Clara
Search
Engine
Text Database
Evaluate
Tuples
Extract
Tuples
Tag
Entities
Generate Extraction
Patterns
Computer servers at Microsoft’s headquarters in Redmond…
In mid-afternoon trading, shares of Redmond, WA-based Microsoft Corp
The Armonk-based IBM introduced a new line…
Change of guard at IBM Corporation’s headquarters near Armonk, NY ...
10
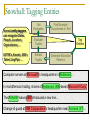
Snowball: Tagging Entities
Named entity taggers
can recognize Dates,
People, Locations,
Organizations, …
MITRE’s Alembic, IBM’s
Talent, LingPipe, …
Get
Examples
Find Example
Occurrences in Text
Evaluate
Tuples
Extract
Tuples
Tag
Entities
Generate Extraction
Patterns
Computer servers at Microsoft ’s headquarters in Redmond…
In mid-afternoon trading, shares of Redmond, WA -based Microsoft Corp
The Armonk -based IBM introduced a new line…
Change of guard at IBM Corporation‘s headquarters near Armonk, NY ...
11
Snowball: Extraction Patterns
Computer servers at Microsoft’s headquarters in Redmond…
General extraction pattern model:
acceptor0,
Entity,
acceptor1, Entity, acceptor2
Acceptor instantiations:
String Match (accepts string “’s headquarters in”)
Vector-Space (~ vector [(-’s,0.5), (headquarters, 0.5),
(in, 0.5)] )
Classifier (estimate P(T=valid | ‘s, headquarters, in) )
12
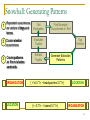
Snowball: Generating Patterns
1 Represent occurrences
Get
Examples
2 Cluster similar
Evaluate
Tuples
as vectors of tags and
terms
occurrences.
Extract
Tuples
Find Example
Occurrences in Text
Tag
Entities
Generate Extraction
Patterns
ORGANIZATION {<'s 0.57>, <headquarters 0.57>, < in 0.57>}
ORGANIZATION
{<‘s 0.57>, <headquarters 0.57>, < near
0.57>}
LOCATION
LOCATION
LOCATION
{<- 0.71>, < based 0.71>}
ORGANIZATION
LOCATION
{<- 0.71>, < based 0.71>}
ORGANIZATION
13
Snowball: Generating Patterns
Represent occurrences
1 as vectors of tags and
terms
2 Cluster similar
occurrences.
3
Create patterns
as filtered cluster
centroids
ORGANIZATION
LOCATION
Get
Examples
Find Example
Occurrences in Text
Evaluate
Tuples
Extract
Tuples
Tag
Entities
Generate Extraction
Patterns
{ <'s 0.71>, <headquarters 0.71>}
{<- 0.71>, < based 0.71>}
LOCATION
ORGANIZATION
14
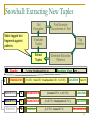
Snowball: Extracting New Tuples
Get
Examples
Match tagged text
fragments against
patterns
Find Example
Occurrences in Text
Evaluate
Tuples
Tag
Entities
Extract
Tuples
Google
V
Generate Extraction
Patterns
's new headquarters in
ORGANIZATION
Mountain View are …
{<'s 0.5>, <new 0.5> <headquarters 0.5>, < in 0.5>}
LOCATION {<are 1>}
Match=0.4
P2
ORGANIZATION
{<located 0.71>, < in 0.71>}
LOCATION
Match=0.8
P1
ORGANIZATION
{<'s 0.71>, <headquarters 0.71> }
LOCATION
Match=0
P3
LOCATION
{<- 0.71>, <based 0.71>
ORGANIZATION
15
Snowball: Evaluating Patterns
Get
Examples
Evaluate
Tuples
Automatically estimate
pattern confidence:
Conf(P4)= Positive / Total
Extract
Tuples
= 2/3 = 0.66
P4
ORGANIZATION
{<
Find Example
Occurrences in Text
, 1> }
Tag
Entities
Generate Extraction
Patterns
Current seed tuples
LOCATION
IBM, Armonk, reported…
Intel, Santa Clara, introduced...
“Bet on Microsoft”, New York
-based analyst Jane Smith said...
Positive
Positive
Organization
Headquarters
IBM
Armonk
Intel
Santa Clara
Microsoft
Redmond
Negative
16
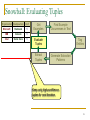
Snowball: Evaluating Tuples
Get
Examples
Automatically evaluate
tuple confidence:
Conf(T) =
1 - 1 - Conf(P i) * Match( Pi)
Find Example
Occurrences in Text
Evaluate
Tuples
Tag
Entities
p
A tuple has high
confidence if generated
by high-confidence
patterns.
Extract
Tuples
Generate Extraction
Patterns
Conf(T): 0.83
3COM Santa Clara
, 1> }
0.4
P4: 0.66
ORGANIZATION
0.8
P3: 0.95
LOCATION {<- 0.75>, <based 0.75>} ORGANIZATION
{<
LOCATION
17
Snowball: Evaluating Tuples
Organization Headquarters
Conf
Microsoft
Redmond
1
IBM
Armonk
1
Intel
Santa Clara
1
AG Edwards
St Louis
0.9
Air Canada
Montreal
0.8
7th Level
Richardson
0.8
3Com Corp
Santa Clara
0.8
3DO
Redwood City
0.7
3M
Minneapolis
0.7
MacWorld
San Francisco
0.7
157th Street
Manhattan
0.52
15th Party
Congress
China
0.3
15th Century
Europe
Dark Ages
0.1
...
...
....
....
..
..
Get
Examples
Find Example
Occurrences in Text
Evaluate
Tuples
Extract
Tuples
Tag
Entities
Generate Extraction
Patterns
Keep only high-confidence
tuples for next iteration
18
Snowball: Evaluating Tuples
Organization Headquarters
Conf
Microsoft
Redmond
1
IBM
Armonk
1
Intel
Santa Clara
1
AG Edwards
St Louis
0.9
Air Canada
Montreal
0.8
7th Level
Richardson
0.8
3Com Corp
Santa Clara
0.8
3DO
Redwood City
0.7
3M
Minneapolis
0.7
MacWorld
San Francisco
0.7
Get
Examples
Find Example
Occurrences in Text
Evaluate
Tuples
Extract
Tuples
Tag
Entities
Generate Extraction
Patterns
Iteratenew
untiliteration
no newwith
tuples
are extracted
Start
expanded
example set
19
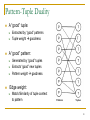
Pattern-Tuple Duality
A “good” tuple:
A “good” pattern:
Extracted by “good” patterns
Tuple weight goodness
Generated by “good” tuples
Extracts “good” new tuples
Pattern weight goodness
Edge weight:
Match/Similarity of tuple context
to pattern
20
How to Set Node Weights
Constraint violation (from before)
Conf(P) = Log(Pos) Pos/(Pos+Neg)
Conf(T) = 1 - 1 - Conf(P i) * Match( Pi)
p
HITS [Hassan et al., EMNLP 2006]
Conf(P) = ∑Conf(T)
Conf(T) = ∑Conf(P)
URNS [Downey et al., IJCAI 2005]
EM-Spy [Agichtein, SDM 2006]
Unknown tuples = Neg
Compute Conf(P), Conf(T)
Iterate
21
Snowball: EM-based Pattern Evaluation
22
Evaluating Patterns and Tuples: Expectation Maximization
EM-Spy Algorithm
“Hide” labels for some seed
tuples
Iterate EM algorithm to
convergence on tuple/pattern
confidence values
Set threshold t such that
(t > 90% of spy tuples)
Re-initialize Snowball using
new seed tuples
Organization
Headquarters
Initial
Final
Microsoft
Redmond
1
1
IBM
Armonk
1
0.8
Intel
Santa Clara
1
0.9
AG Edwards
St Louis
0
0.9
Air Canada
Montreal
0
0.8
7th Level
Richardson
0
0.8
3Com Corp
Santa Clara
0
0.8
3DO
Redwood City
0
0.7
3M
Minneapolis
0
0.7
MacWorld
San Francisco
0
0.7
…..
0
157th Street
Manhattan
0
0.52
15th Party
Congress
China
0
0.3
15th Century
Europe
Dark Ages
0
0.1
0
23
Adapting Snowball for New Relations
Large parameter space
Initial seed tuples (randomly chosen, multiple runs)
Acceptor features: words, stems, n-grams, phrases, punctuation, POS
Feature selection techniques: OR, NB, Freq, ``support’’, combinations
Feature weights: TF*IDF, TF, TF*NB, NB
Pattern evaluation strategies: NN, Constraint violation, EM, EM-Spy
Automatically estimate parameter values:
Estimate operating parameters based on occurrences of seed tuples
Run cross-validation on hold-out sets of seed tuples for optimal perf.
Seed occurrences that do not have close “neighbors” are discarded
24
Example Task 1: DiseaseOutbreaks
Proteus:
Snowball:
SDM 2006
0.409
0.415
25
Example Task 2: Bioinformatics
ISMB 2003
a.k.a. mining the “bibliome”
100,000+ gene and protein synonyms
extracted from
50,000+ journal articles
Approximately 40% of confirmed
synonyms not previously listed
in curated authoritative reference
(SWISSPROT)
“APO-1, also known as DR6…”
“MEK4, also called SEK1…”
26
Snowball Used in Various Domains
News: NYT, WSJ, AP [DL’00, SDM’06]
Medical literature: PDRHealth, Micromedex…
[Thesis]
CompanyHeadquarters, MergersAcquisitions,
DiseaseOutbreaks
AdverseEffects, DrugInteractions,
RecommendedTreatments
Biological literature: GeneWays corpus
[ISMB’03]
Gene and Protein Synonyms
27
CIKM 2005
Limits of Bootstrapping for
Task “easy” when context term distributions diverge from background
Extraction
President George W Bush’s three-day visit to India
0.07
0.06
frequency
0.05
0.04
0.03
0.02
0.01
0
the
to
and
said
's
company
won
president
Quantify as relative entropy (Kullback-Liebler divergence)
KL( LM C || LM BG ) LM C ( wi ) log
wV
mrs
LM C ( w)
LM BG ( w)
After calibration, metric predicts if bootstrapping likely to work
28
SIGIR 2005
Few Relations Cover Common Questions
25 relations cover > 50% of question types, 5 relations cover > 55% question instances
Relation
Type
Instance
<person> discovers <concept>
7.7
2.9
<person> has position <concept>
5.6
4.6
<location> has location <location>
5.2
1.5
<person> known for <concept>
4.7
1.7
<event> has date <date>
4.1
0.9
29
Outline
Snowball, a domain-independent, partially
supervised information extraction system
Retrieval algorithms for scalable information
extraction
Current: mining user behavior for web search
Future work
30
Extracting A Relation From a Large Text Database
Information
Extraction
System
Text Database
Structured
Relation
Brute force approach: feed all
Expensive for
docs to information extraction system large collections
Only a tiny fraction of documents are often useful
Many databases are not crawlable
Often a search interface is available, with existing
keyword index
How to identify “useful” documents?
]
31
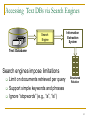
Accessing Text DBs via Search Engines
Search
Engine
Information
Extraction
System
Text Database
Search engines impose limitations
Limit on documents retrieved per query
Support simple keywords and phrases
Ignore “stopwords” (e.g., “a”, “is”)
Structured
Relation
32
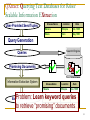
QXtract: Querying Text Databases for Robust
Scalable Information EXtraction
User-Provided Seed Tuples
DiseaseName
Location
Date
Malaria
Ethiopia
Jan. 1995
Ebola
Zaire
May 1995
Query Generation
Search Engine
Queries
Promising Documents
Text Database
Information Extraction System
DiseaseName
Location
Date
Malaria
Ethiopia
Jan. 1995
Ebola
Zaire
May 1995
Problem:
keyword
queries
Cow Disease
The
U.K.
July 1995
Extracted
RelationLearnMad
Pneumonia
The U.S.
Feb. 1995
to retrieve “promising”
documents
33
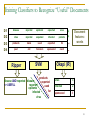
Learning Queries to Retrieve Promising Documents
1. Get document sample
with “likely negative” and
“likely positive” examples.
User-Provided Seed Tuples
Seed Sampling
Text Database
?
3. Train classifiers to
“recognize” useful
documents.
4. Generate queries from
classifier model/rules.
?
?
?
? ?
?
?
2. Label sample documents
using information
extraction system as
“oracle.”
Search Engine
Information Extraction System
tuple1
tuple2
tuple3
tuple4
tuple5
+
+
-
-
+
+
- -
Classifier Training
+
+
-
-
+
+
-
-
Query Generation
Queries
34
Training Classifiers to Recognize “Useful” Documents
D1
disease
reported
epidemic
expected
area
D2
virus
reported
expected
infected
patients
D3
products
made
used
exported
far
D4
past
old
homerun
sponsored
event
Ripper
SVM
products
disease
disease AND reported
exported
reported
=> USEFUL
used
epidemic
far
infected
virus
+
+
Document
features:
words
-
Okapi (IR)
virus
3
infected
2
sponsored
-1
35
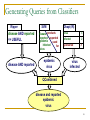
Generating Queries from Classifiers
Ripper
disease AND reported
=> USEFUL
disease AND reported
SVM
disease products
reported exported
epidemic
used
infected
far
virus
epidemic
virus
Okapi (IR)
virus
3
infected
2
sponsored
-1
virus
infected
QCombined
disease and reported
epidemic
virus
36
SIGMOD 2003
Demonstration
37
Tuples: A Simple Querying Strategy
DiseaseName
Location
Date
Ebola
Zaire
May
1995
Malaria
Ethiopia
Jan.
1995
hemorrhagic fever
Africa
May
1995
1.
2.
3.
“Ebola” and “Zaire”
Search
Engine
Information
Extraction
System
Convert given tuples into queries
Retrieve matching documents
Extract new tuples from documents and
iterate
38
Comparison of Document Access Methods
80
70
recall (%)
60
50
40
30
20
10
0
5%
10%
25%
MaxFractionRetrieved
QXtract
Manual
Tuples
Baseline
QXtract: 60% of relation extracted from 10% of
documents of 135,000 newspaper article database
Tuples strategy: Recall at most 46%
39
How to choose the best strategy?
Tuples: Simple, no training, but limited recall
QXtract: Robust, but has training and query overhead
Scan: No overhead, but must process all documents
40
WebDB 2003
Predicting Recall of Tuples Strategy
Seed
Seed
Tuple
Tuple
SUCCESS!
FAILURE
Can we predict if Tuples will succeed?
41
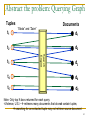
Abstract the problem: Querying Graph
Tuples
t1
Documents
“Ebola” and “Zaire”
d1
t2
Search
Engine
t3
d2
d3
t4
d4
t5
d5
Note: Only top K docs returned for each query.
<Violence, U.S.> retrieves many documents that do not contain tuples;
searching for an extracted tuple may not retrieve source document
42
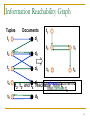
Information Reachability Graph
Tuples
t1
Documents
d1
t2
d2
t3
d3
t4
t1
t2
t3
t5
t4
d
t1 retrieves document d1
4
t2, t3, and t4 “reachable”
from
t
1 t
that contains
2
t5
d5
43
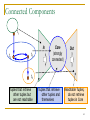
Connected Components
t1
In
t2
t3
Core
(strongly
connected)
Out
t4
Tuples that retrieve
other tuples but
are not reachable
Tuples that retrieve
other tuples and
themselves
Reachable Tuples,
do not retrieve
tuples in Core
44
Sizes of Connected Components
How many tuples are in largest Core + Out?
In
Core
Out
In
t0
Core
(strongly
connected)
Out
In
Core
Out
Conjecture:
Degree distribution in reachability graphs follows “power-law.”
Then, reachability graph has at most one giant component.
Define Reachability as Fraction of tuples in largest Core + Out
45
NYT Reachability Graph:
Outdegree Distribution
Matches the power-law distribution
MaxResults=10
MaxResults=50
46
NYT: Component Size Distribution
Not “reachable”
MaxResults=10
CG / |T| = 0.297
“reachable”
MaxResults=50
CG / |T| = 0.620
47
Connected Components Visualization
DiseaseOutbreaks,
48
New York Times 1995
Estimating Reachability
In a power-law random graph G a giant
component
CG emerges* if d (the average outdegree) > 1,
and:
Estimate: Reachability ~ CG / |T|
Depends only on d (average outdegree)
* For b < 3.457 Chung and Lu, Annals of Combinatorics, 2002
49
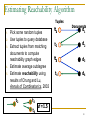
Estimating Reachability Algorithm
Tuples
1.
2.
3.
4.
5.
Pick some random tuples
Use tuples to query database
Extract tuples from matching
documents to compute
reachability graph edges
Estimate average outdegree
Estimate reachability using
results of Chung and Lu,
Annals of Combinatorics, 2002
t2
t2
t4
t1
Documents
d1
t2
d2
t3
d3
t4
d4
d =1.5
50
Estimating Reachability of NYT
S=10
S=50
S=100
S=200
Real Graph
1
0.9
Reachability
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
MR=1
MR=10
MR=50
MR=100
MR=200
MR=1000
MaxResults
.46
Approximate reachability is estimated after ~ 50
queries.
Can be used to predict success (or failure) of a
Tuples querying strategy.
51
To Search or to Crawl? Towards a Query Optimizer for TextCentric Tasks, [Ipeirotis, Agichtein, Jain, Gavano, SIGMOD 2006]
Information extraction applications extract structured
relations from unstructured text
May 19 1995, Atlanta -- The Centers for Disease Control
and Prevention, which is in the front line of the world's
response to the deadly Ebola epidemic in Zaire ,
is finding itself hard pressed to cope with the crisis…
Disease Outbreaks in The New York Times
Information
Extraction System
(e.g., NYU’s Proteus)
Date
Disease Name
Location
Jan. 1995
Malaria
Ethiopia
July 1995
Mad Cow Disease U.K.
Feb. 1995
Pneumonia
U.S.
May 1995
Ebola
Zaire
52
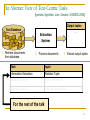
An Abstract View of Text-Centric Tasks
[Ipeirotis, Agichtein, Jain, Gavano, SIGMOD 2006]
Output tuples
Text Database
…
Extraction
System
1. Retrieve documents
from database
2. Process documents
3. Extract output tuples
Task
tuple
Information Extraction
Relation Tuple
Database Selection
Word (+Frequency)
Focused Crawling
Web Page about a Topic
For the rest of the talk
53
Executing a Text-Centric Task
Output tuples
Text Database
Extraction
…
System
1. Retrieve
documents from
database
Similar to relational world
2. Process
documents
3. Extract output
tuples
Two major execution paradigms
Scan-based: Retrieve and process documents
sequentially
Index-based: Query database (e.g., [case fatality rate]),
retrieve and process documents in results
→underlying data distribution dictates what is best
Indexes are only “approximate”: index is on
keywords, not on tuples of interest
Choice of execution plan affects output
completeness (not only speed)
Unlike the relational world
54
Execution Plan Characteristics
Output tuples
Text Database
1.
Question: How
do we choose the…
Extraction
fastest execution
plan for reaching
System
a
target
recall
?
Retrieve documents
from database
2. Process documents
3. Extract output tuples
Execution Plans have two main characteristics:
Execution Time
Recall (fraction of tuples retrieved)
“What is the fastest plan for discovering 10% of the disease
outbreaks mentioned in The New York Times archive?”
55
Outline
Description and analysis of crawl- and query-based plans
Scan
Crawl-based
Filtered Scan
Iterative Set Expansion
Automatic Query Generation
Query-based
(Index-based)
Optimization strategy
Experimental results and conclusions
56
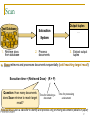
Scan
Output tuples
Text Database
Extraction
…
System
1. Retrieve docs
from database
2. Process
documents
3. Extract output
tuples
Scan retrieves and processes documents sequentially (until reaching target recall)
Execution time = |Retrieved Docs| · (R + P)
Question: How many documents
does Scan retrieve to reach target
recall?
Time for retrieving a
document
Time for processing
a document
Filtered Scan uses a classifier to identify and process only promising documents (details in paper)
57
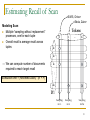
Estimating Recall of Scan
<SARS, China>
Modeling Scan for tuple t:
What is the probability of seeing t (with
frequency g(t)) after retrieving S documents?
A “sampling without replacement” process
Token
t
d1
d2
S documents
...
After retrieving S documents, frequency of
tuple t follows hypergeometric distribution
Recall for tuple t is the probability that
frequency of t in S docs > 0
dS
...
dN
D
Probability of seeing tuple t
after retrieving S documents
g(t) = frequency of tuple t
Sampling
for t
58
Estimating Recall of Scan
<SARS, China>
<Ebola, Zaire>
Modeling Scan:
Multiple “sampling without replacement”
processes, one for each tuple
Overall recall is average recall across
tuples
Tokens
t1
t2
Sampling
for t1
Sampling
for t2
...
tM
d1
d2
→ We can compute number of documents
required to reach target recall
d3
...
Execution time = |Retrieved Docs| · (R + P)
dN
D
Sampling
for tM
59
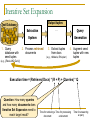
Iterative Set Expansion
Output tuples
Text Database
…
Extraction
Query
System
1. Query
database with
seed tuples
Generation
2. Process retrieved
documents
3. Extract tuples
from docs
(e.g., <Malaria, Ethiopia>)
4. Augment seed
tuples with new
tuples
(e.g., [Ebola AND Zaire])
Execution time = |Retrieved Docs| * (R + P) + |Queries| * Q
Question: How many queries
and how many documents does
Iterative Set Expansion need to
reach target recall?
Time for retrieving a Time for processing
document
a document
Time for answering
a query60
Using Querying Graph for Analysis
We need to compute the:
Number of documents retrieved after
sending Q tuples as queries (estimates time)
Number of tuples that appear in the
retrieved documents (estimates recall)
tuples
t1
Documents
d1
<SARS, China>
t2
d2
<Ebola, Zaire>
To estimate these we need to compute the:
Degree distribution of the tuples
discovered by retrieving documents
Degree distribution of the documents
retrieved by the tuples
(Not the same as the degree distribution of a
randomly chosen tuple or document – it is easier to
discover documents and tuples with high degrees)
t3
d3
<Malaria, Ethiopia>
t4
d4
t5
d5
<Cholera, Sudan>
<H5N1, Vietnam>
61
Summary of Cost Analysis
Our analysis so far:
Takes as input a target recall
Gives as output the time for each plan to reach target recall
(time = infinity, if plan cannot reach target recall)
Time and recall depend on task-specific properties of database:
tuple degree distribution
Document degree distribution
Next, we show how to estimate degree distributions on-the-fly
62
Estimating Cost Model Parameters
tuple and document degree distributions belong to known distribution families
Task
Document Distribution
tuple Distribution
Information Extraction
Power-law
Power-law
Content Summary Construction
Lognormal
Power-law (Zipf)
Focused Resource Discovery
Uniform
Uniform
10000
100000
y = 43060x-3.3863
10000
1000
y = 5492.2x-2.0254
Number of Tokens
Number of Documents
1000
100
10
1
1
10
Document Degree
100
100
10
1
1
10
100
Token Degree
1000
63
Can characterize distributions with only a few parameters!
Parameter Estimation
Naïve solution for parameter estimation:
Start with separate, “parameter-estimation” phase
Perform random sampling on database
Stop when cross-validation indicates high confidence
We can do better than this!
No need for separate sampling phase
Sampling is equivalent to executing the task:
→Piggyback parameter estimation into execution
64
On-the-fly Parameter Estimation
Correct (but unknown) distribution
Pick most promising execution
plan for target recall assuming
“default” parameter values
Start executing task
Update parameter estimates
during execution
Switch plan if updated statistics
indicate so
Initial,
default
estimation
Updated
estimation
Updated
estimation
Important
Only Scan acts as “random sampling”
65
All other execution plan need parameter adjustment (see paper)
Outline
Description and analysis of crawl- and query-based plans
Optimization strategy
Experimental results and conclusions
66
Correctness of Theoretical Analysis
100,000
Execution Time (secs)
10,000
Scan
1,000
Filt. Scan
Automatic Query Gen.
Iterative Set Expansion
100
0.00
0.10
0.20
0.30
0.40
0.50
Recall
0.60
Solid lines: Actual time
Dotted lines: Predicted time with correct parameters
0.70
0.80
0.90
1.00
Task: Disease Outbreaks
Snowball IE system
182,531 documents from NYT
67
16,921 tuples
Experimental Results (Information Extraction)
100,000
Execution Time (secs)
10,000
Scan
Filt. Scan
1,000
Iterative Set Expansion
Automatic Query Gen.
OPTIMIZED
100
0.00
0.10
0.20
0.30
0.40
0.50
Recall
0.60
0.70
0.80
0.90
1.00
Solid lines: Actual time
Green line: Time with optimizer
(results similar in other experiments – see paper)
68
Conclusions
Common execution plans for multiple text-centric tasks
Analytic models for predicting execution time and recall
of various crawl- and query-based plans
Techniques for on-the-fly parameter estimation
Optimization framework picks on-the-fly the fastest plan
for target recall
69
Can we do better?
Yes. For some information extraction systems
70
Bindings Engine (BE) [Slides: Cafarella 2005]
Bindings Engine (BE) is search engine where:
No downloads during query processing
Disk seeks constant in corpus size
#queries = #phrases
BE’s approach:
“Variabilized” search query language
Pre-processes all documents before query-time
Integrates variable/type data with inverted index,
minimizing query seeks
71
BE Query Support
cities such as <NounPhrase>
President Bush <Verb>
<NounPhrase> is the capital of <NounPhrase>
reach me at <phone-number>
Any sequence of concrete terms and typed
variables
NEAR is insufficient
Functions (e.g., “head(<NounPhrase>)”)
72
BE Operation
Like a generic search engine, BE:
BE further requires:
Downloads a corpus of pages
Creates an index
Uses index to process queries efficiently
Set of indexed types (e.g., “NounPhrase”), with a
“recognizer” for each
String processing functions (e.g., “head()”)
A BE system can only process types and
functions that its index supports
73
as
billy
cities
friendly
give
mayors
nickels
seattle
such
words
docid2
…
docid1
docid2
docid3
docid0
docid1
docid2
…
docid#docs-1
#docs
docid0
docid1
docid2
#docs
docid0
docid1
#docs
docid0
docid1
docid2
docid#docs-1
#docs
docid0
docid1
docid2
…
…
#docs
docid0
#docs
docid0
docid1
#docs
docid0
docid1
#docs
docid0
#docs
docid0
#docs
docid#docs-1
docid#docs-1
74
Query: such as
as
billy
cities
friendly
give
mayors
nickels
seattle
such
words
Returned docs:
#docs
docid0
docid1
docid2
104
21
150
322
…
docid#docs-1
2501
1. Test for equality
2. Advance smaller pointer
3. Abort when a list is exhausted
322
#docs
docid0
docid1
docid2
15
99
322
426
…
docid#docs-1
1309
75
“such as”
as
billy
cities
friendly
give
mayors
nickels
seattle
such
words
docid docid pos
……
#docs
#docsdocid
docid
docid
docid
0 pos
0 0 docid
1 1 pos
1 2
#posns
pos0
pos1
…
#docs-1 #docs-1
#docs-1
pos#pos-1
In phrase queries, match positions as well
docid docid pos
……
#docs
#docsdocid
docid
docid1 1 pos
docid
0 pos
0 0 docid
1 2
#posns
pos0
pos1
…
#docs-1 #docs-1
#docs-1
pos#pos-1
76
Neighbor Index
At each position in the index, store “neighbor text”
that might be useful
Let’s index <NounPhrase> and <Adj-Term>
“I love cities such as Atlanta.”
Left
Right
AdjT: “love”
77
Neighbor Index
At each position in the index, store “neighbor text”
that might be useful
Let’s index <NounPhrase> and <Adj-Term>
“I love cities such as Atlanta.”
Left
AdjT: “I”
NP: “I”
Right
AdjT: “cities”
NP: “cities”
78
Neighbor Index
Query: “cities such as <NounPhrase>”
“I love cities such as Atlanta.”
Left
AdjT: “such”
Right
AdjT: “Atlanta”
NP: “Atlanta”
79
“cities such as <NounPhrase>”
as
billy
cities
friendly
give
mayors
nickels
Atlanta
such
words
#docs docid0 pos0 docid1 pos1
19
…
docid#docs-1 pos#docs-1
… neighbor
pos
…
#posns
#posns
pos0 pos
neighbor
pos
0
0 1 pos1
#pos-1
1
pos#pos-1
…
12
blk_offset #neighbors neighbor0
str0
neighbor1
str1
<offset>
such
NPright
Atlanta
3
AdjTleft
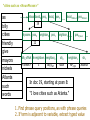
In doc 19, starting at posn 8:
“I love cities such as Atlanta.”
1. Find phrase query positions, as with phrase queries
80
2. If term is adjacent to variable, extract typed value
Current Research Directions
Modeling explicit and Implicit network structures
Knowledge Discovery from Biological and Medical Data
Automatic sequence annotation bioinformatics, genetics
Actionable knowledge extraction from medical articles
Robust information extraction, retrieval, and query processing
Modeling evolution of explicit structure on web, blogspace, wikipedia
Modeling implicit link structures in text, collections, web
Exploiting implicit & explicit social networks (e.g., for epidemiology)
Integrating information in structured and unstructured sources
Robust search/question answering for medical applications
Confidence estimation for extraction from text and other sources
Detecting reliable signals from (noisy) text data (e.g.,: medical surveillance)
Accuracy (!=authority) of online sources
Information diffusion/propagation in online sources
Information propagation on the web
In collaborative sources (wikipedia, MedLine)
81
Page Quality: In Search of an Unbiased Web Ranking
[Cho, Roy, Adams, SIGMOD 2005]
“popular pages tend to get even more popular, while
unpopular pages get ignored by an average user”
82
Sic Transit Gloria Telae: Towards an Understanding of the
Web’s Decay [Bar-Yossef, Broder, Kumar, Tomkins, WWW 2004]
83
Modeling Social Networks for
Epidemiology, security, …
Email exchange mapped onto cubicle locations.
84
Some Research Directions
Modeling explicit and Implicit network structures
Knowledge Discovery from Biological and Medical Data
Automatic sequence annotation bioinformatics, genetics
Actionable knowledge extraction from medical articles
Robust information extraction, retrieval, and query processing
Modeling evolution of explicit structure on web, blogspace, wikipedia
Modeling implicit link structures in text, collections, web
Exploiting implicit & explicit social networks (e.g., for epidemiology)
Integrating information in structured and unstructured sources
Query processing over unstructured text
Robust search/question answering for medical applications
Confidence estimation for extraction from text and other sources
Detecting reliable signals from (noisy) text data (e.g.,: medical surveillance)
Information diffusion/propagation in online sources
Information propagation on the web
In collaborative sources (wikipedia, MedLine)
85
Agichtein & Eskin, PSB 2004
Mining Text and Sequence Data
ROC50 scores for each class and method
86
Some Research Directions
Modeling explicit and Implicit network structures
Knowledge Discovery from Biological and Medical Data
Automatic sequence annotation bioinformatics, genetics
Actionable knowledge extraction from medical articles
Robust information extraction, retrieval, and query processing
Modeling evolution of explicit structure on web, blogspace, wikipedia
Modeling implicit link structures in text, collections, web
Exploiting implicit & explicit social networks (e.g., for epidemiology)
Integrating information in structured and unstructured sources
Robust search/question answering for medical applications
Confidence estimation for extraction from text and other sources
Detecting reliable signals from (noisy) text data (e.g.,: medical surveillance)
Accuracy (!=authority) of online sources
Information diffusion/propagation in online sources
Information propagation on the web
In collaborative sources (wikipedia, MedLine)
87
Structure and evolution of blogspace
[Kumar, Novak, Raghavan, Tomkins, CACM 2004, KDD 2006]
Fraction of nodes in components of various sizes within Flickr and Yahoo!
360 timegraph, by week.
88
Current Research Directions
Modeling explicit and Implicit network structures
Knowledge Discovery from Biological and Medical Data
Automatic sequence annotation bioinformatics, genetics
Actionable knowledge extraction from medical articles
Robust information extraction, retrieval, and query processing
Modeling evolution of explicit structure on web, blogspace, wikipedia
Modeling implicit link structures in text, collections, web
Exploiting implicit & explicit social networks (e.g., for epidemiology)
Integrating information in structured and unstructured sources
Robust search/question answering for medical applications
Confidence estimation for extraction from text and other sources
Detecting reliable signals from (noisy) text data (e.g.,: medical surveillance)
Accuracy (!=authority) of online sources
Information diffusion/propagation in online sources
Information propagation on the web, news
In collaborative sources (wikipedia, MedLine)
89
Thank You
Details:
http://www.mathcs.emory.edu/~eugene/
90