Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Open Database Connectivity wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Functional Database Model wikipedia , lookup
Relational model wikipedia , lookup
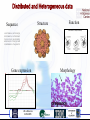
Comparison of Data Access and Integration Technologies in the Life Science Domain Dr Richard Sinnott Technical Director National e-Science Centre ||| Deputy Director Technical Bioinformatics Research Centre University of Glasgow Derek Houghton Database Manager Human Genetics Unit Medical Research Council Edinburgh [email protected] [email protected] 19th September 2005 UK e-Science AHM 2005 Life Sciences and Grids Extensive Research Community >1000 per research university Extensive Applications Many people care about them Health, Food, Environment, … Interacts with many disciplines Physics, Chemistry, Maths/Statistics, Nano-engineering, … Huge and expanding number of databases relevant to bioinformatics community Heterogeneity, Interdependence, Complexity, Change, Dirty… Linking using in co-ordinated, secure manner full of open issues to be addressed Compute demands growing as more in-silico research undertaken UK e-Science AHM 2005 Database Growth PDB Content Growth •DBs growing exponentially!!! •Biobliographic (MedLine, …) •Amino Acid Seq (SWISS-PROT, …) •3D Molecular Structure (PDB, …) •Nucleotide Seq (GenBank, EMBL, …) •Biochemical Pathways (KEGG, WIT…) •Molecular Classifications (SCOP, CATH,…) •Motif Libraries (PROSITE, Blocks, …) UK e-Science AHM 2005 Distributed and Heterogeneous data Structure Sequence LPSYVDWRSA ECGGCWAFSA TSGSLISLSE NTRGCDGGYI GGINTEENYP Function GAVVDIKSQG IATVEGINKI QELIDCGRTQ TDGFQFIIND YTAQDGDCDV Gene expression UK e-Science AHM 2005 Morphology More genomes …... Yersinia pestis Arabidopsis thaliana Buchnerasp. APS Caenorhabitis Campylobacter Chlamydia elegans jejuni pneumoniae Helicobacter Mycobacterium pylori leprae rat mouse Aquifex aeolicus Vibrio cholerae Archaeoglobus Borrelia Mycobacterium fulgidus burgorferi tuberculosis Drosophila melanogaster Escherichia Thermoplasma coli acidophilum Neisseria Plasmodium Pseudomonas Ureaplasma meningitidis falciparum aeruginosa urealyticum Z2491 Rickettsia Saccharomyces Salmonella UK e-Science prowazekiiAHM 2005 cerevisiae enterica Bacillus subtilis Thermotoga maritima Xylella fastidiosa UK e-Science AHM 2005 + links to plant/crops, environmental, health, … information sources Populations Organisms Physiology Tissues Protein-protein interaction (pathways) Protein Structures Gene expressions Nucleotide structures Systems Biology Is Grid the Answer? Some key problems to be addressed Tools that simplify access to and usage of data Internet hopping is not ideal! Tools that simplify access to and usage of large scale HPC facilities qsub [-a date_time] [-A account_string] [-c interval] [-C directive_prefix] [-e path] [-h] [-I] [-j join] [-k keep] [-l resource_list] [-m mail_options] [-M user_list] [-N name] [-o path] [-p priority] [-q destination] [-r c] [-S path_list] [-u user_list] [-v variable_list] [-V] [-W additional_attributes] [-z] [script] Tools designed to aid understanding of complex data sets and relationships between them e.g. through visualisation Make it all easy to use! Scientists should not have to be Linux script experts, …nor set up/configure complex Grid software or follow complex procedures for getting, using Grid certificates, …nor have detailed understanding of low level data schemas for all data sites, … etc etc UK e-Science AHM 2005 Overview of BRIDGES Biomedical Research Informatics Delivered by Grid Enabled Services (BRIDGES) NeSC (Edinburgh and Glasgow) and IBM Started October 2003 – due to end soon Supporting project for CFG project Generating data on hypertension Rat, Mouse, Human genome databases Variety of tools used BLAST, BLAT, Gene Prediction, visualisation, … Variety of data sources and formats Microarray data, genome DBs, project partner research data, … Aim is integrated infrastructure supporting Data federation Security UK e-Science AHM 2005 BRIDGES Project CFG Virtual Publically Curated Data Ensembl Organisation OMIM Glasgow SWISS-PROT Private Edinburgh MGI VO Authorisation Private data Oxford Information Integrator Synteny Service Magna Vista Service London HUGO … RGD Leicester DATA HUB OGSA-DAI Private data data Private data Netherlands Private data Private data + UK e-Science AHM 2005 + + Primary BRIDGES Data Use Case Given gene name/identifier, issue a query to federated database and present all available information back to the user in a user friendly/configurable way Several client side applications were developed for this purpose: MagnaVista, GeneVista, “JOS-AHM-vista” MagnaVista and “JOSAHM-vista” are Java applications GeneVista based upon portlet technologies Notes focus was on developing working solutions for scientists and not to compare OGSA-DAI and IBM II several team changes throughout project UK e-Science AHM 2005 Overview of Data Access and Integration Technologies Overview of Information Integrator suite of wrappers for relational (Oracle, DB2, Sybase, …) and nonrelational (flat files, Excel spreadsheets, XML databases, …) targets which extend integration capabilities of DB2 database allows to establish ‘federated’ view of distributed data allowing applications access to data as though in single, local DB2 database Data Data in DB2 wrapper Client Running Life Sciences App wrapper Information Integrator wrapper SQL API (JDBC, ODBC, ) Data in Oracle DB Data in Flat files Catalogue free for academic use (IBM Scholars program) comes with suite of tools and utilities with which DB administrator can monitor and optimize database can interact with DB either by command line or graphical interface options to create Java/SQL stored procedures and customized functions UK e-Science AHM 2005 Overview of Data Access and Integration Technologies Overview of OGSA-DAI middleware provides application developers with a range of service interfaces allowing data access and integration via the Grid OGSA-DAI is not a database management system rather it uses Grid infrastructure to perform queries on a set of relational/nonrelational data sources and conveys result sets back to the user application via SOAP Through OGSA-DAI interfaces, disparate, heterogeneous data sources and resources can be treated as a single logical resource OGSA-DAI is free/open source has number of data source types both relational and non-relational with which it can communicate OGSA-DAI documentation is clear/concise (We’ve had!) good support from the development team UK e-Science AHM 2005 Comparing Data Access and Integration Technologies How to compare? Set-up installation Post-installation Initial user experiences Challenges of life sciences Schema Changes Data Independence Creating Federated Views Performance UK e-Science AHM 2005 Set-Up Installation IBM Information Integrator Process of accessing, obtaining, installing and configuring IBM II is non-trivial Access through “Scholar’s Program” can be a time consuming procedure and requires authorisation Advanced knowledge of the vendor clients that the wrappers may use (e.g. Sybase 12.5ASE Client) eases the installation process especially true on Linux as need to manually edit config. files/run rebinding scripts if clients installed later BRIDGES team also went on training course from IBM which helped OGSA-DAI is (by contrast) a much friendlier affair one visits the download site, signs up for access and is issued with a username and password for authentication to the download area new releases are advertised by email (submitted during the sign up process) all downloads supplied with obligatory README file which provides guidance as to the setup procedure and additional downloads needed – e.g. JDBC drivers, apache utilities With OGSA-DAIv4 release the install process can also be done via a GUI UK e-Science AHM 2005 Post-Installation IBM Information Integrator IBM provides MANY!!!!! Redbooks available on their website at the time of BRIDGES work in applying IBM II, these were not descriptively named so it was a matter of opening each one to discover title/topics dealt with time consuming searching for specific information Online search facility useful especially for syntax questions Within the last few months, navigation around IBM’s website has improved significantly providing easier access to online documentation and resources OGSA-DAI comes with its own HTML documentation which can be downloaded separately as required content and navigability of this has improved over each release as more detailed coding examples have been given User support is quick and efficient with a response time typically < 24 hours UK e-Science AHM 2005 Basic Usage Experience IBM Information Integrator Attempts were made initially to use IBM II’s XML wrapper to query Swissprot/Uniprot DB DB is in XML format and available for ftp download (over 1.1GB) wrapper failed in its attempt to work with this file, as, according to IBM white paper the whole document is loaded in memory as a Document Object Model (DOM) – Could have split the file into chunks but cumbersome solution Decided to parse the file and import it into DB2 relational tables Each flat file wrapper has to be manually configured to match the file ‘columns’ – no greater effort to actually write a programme to parse the file and then add to DB » Once in DB have all the benefits of indexing, optimisation etc initial parse of the Swissprot DB used table ‘Inserts’ to commit data immediately to DB2 database as file read by the parsing program – Java SAX parsing used and primary and foreign keys updated using insert triggers – took 84 hours for the 1.1GB file with around 500,000 inserts to the database Wrapper format inconsistencies, e.g. OMIM UK e-Science AHM 2005 Basic Usage Experience …ctd IBM Information Integrator IBM II insists that the flat file being wrapped exists on a computer with exactly the same user setup/privileges as the data server itself not the case with the BRIDGES federated data Grid!! – unlikely to be the case with other life science data sets…??? Fine grained security model something explored within BRIDGES based upon PERMIS technology – (see demo at NeSC booth for more info) UK e-Science AHM 2005 Basic Usage Experience …ctd OGSA-DAI Used basic Perform documents for doing federated queries Returned data stored locally (in files) and accessed by client application and rendered to users Is this Integration? From client perspective, they see no difference!!! – More elegant solution would be to have middleware do “integration” but issues… UK e-Science AHM 2005 Schema Changes In BRIDGES two-relational data sources allowed programmatic access: Ensembl (MySQL - Rat, Mouse and Human Genomes, Homologs and Database Cross Referencing) MGI (Sybase - mainly Mouse publications and some QTL data.) Flat files downloaded for RGD (Rat Genome Database), OMIM (Online Mendelian Inheritance in Man), Swissprot/Uniprot, HUGO (Human Gene Ontology), GO (Gene Ontology) Don’t expect to be give schema for flat file!!! Changes made to schema of third party DB completely out of our control Ensembl change the name of their main gene database every month! DB schema drastically altered on 3 occasions during BRIDGES project MGI have had one major overhaul of all their table structure In these cases queries to these remote data sources will fail!!! UK e-Science AHM 2005 Schema Changes …ctd We used Materialized Query Tables (MQTs) in IBM II to insulate queries from remote schema changes MQT is local cache of remote table/view and can be set to refresh after a specified time interval or not at all up to the minute data (refreshed frequently) vs slightly older data but impervious to schema changes MQT can be optimized to try the remote connection first, if available run query, if not use local cache Query fails if remote schema changes!!! Bridges_wget application checks for remote DB connections if the connection made – runs sample query naming columns to see if schema has changed – If all is well, remote flat files are checked for modification dates – If newer ones found they are downloaded, parsed and loaded into the DB » Goes some way to keeping the BRIDGES DB up to date with current data – Parsers are not semantically intelligent so require updating the code (Java) to meet with file format modifications UK e-Science AHM 2005 Data Independence Key issue challenge is fact that data sources largely independent Not always possible to find column to act as foreign key over which joining two (or more) databases can occur When there is a candidate, often the column name is not named descriptively to give clue as to which database might be joined to which For example, in case of Ensembl a row containing a gene identifier contains a Boolean column indicating whether a reference exists in another database RGD_BOOL=1 indicates that a cross reference can be made to the RGD database for this gene identifier – Must query Ensembl RGD_XREF table to obtain unique ID for entry in RGD database – Query to RGD may contain references to other databases and indeed back to Ensembl » …potentially have circular referencing problem!!! Solved by caching all available unique identifiers and their associated database from all remote data sources in local materialized query table – When match found, associated data resource queried and all results returned to user » Up to user to decide which information to use UK e-Science AHM 2005 Creating Federated Views In setting up federated view with IBM II various steps needed: choose which wrapper to use; define a ‘Server’ containing all connection parameters; create ‘Nicknames’ for the server local DB2 tables mapped to their remote counterparts; ‘Discover’ function supports this process connects to the remote resource and displays all the metadata available Such advanced features are not available with OGSA-DAI UK e-Science AHM 2005 Performance Comparison Example of single query response, we ran a search for the PAX7 gene across the BRIDGES federated view of 7 bio databases. This returned One entry from Ensembl Mouse Table (27 columns) One entry from Ensembl Human Table (27 columns) One entry from the HUGO database (20 columns) Eighty five entries from MGI including full abstract and publication details. (11 columns) One full entry from the OMIM database including fully annotated publication details. (19 columns) Two full entries from Swissprot/Uniprot including full sequence and reference data. (50 columns) The average response time for MagnaVista was 44 sec includes time to rebuild the application perspective GUI OGSA-DAI solutions are of this order also UK e-Science AHM 2005 Conclusions Big advantage of using IBM II is all utilities that come with database management system. This includes : replication of databases which can be configured to update from single transaction committed to a set time interval for bulk updates; creation of explain tables which will graphically show the query author the amount of table scans done as the result of the executed query and thereby allow different solutions to be compared; creation of tasks which can be executed immediately or at specified times, e.g. when the database is less used; running statistics and reorganizing tables; taking Snapshots of the database to see where bottlenecks may be occurring. OGSA-DAI as used in BRIDGES has shown we can implement data “access” solutions also Less overheads in learning DB2 We note that since our evaluations were made, IBM have prototyped an OGSA-DAI wrapper for Information Integrator. UK e-Science AHM 2005 Conclusions We focused largely on data access (and not integration) Client apps took care of majority of the data integration issues Tried to explore OGSA-DQP but without immediate success Changes in personnel, keeping IBM II solution alive! Future challenges and recommendations standards/data models crucial to data access and integration often gaining access to the database itself most often not possible JDSS report describes these issues in detail BRIDGES queries fairly simplistic in nature – returning all data sets associated with a named gene GEMEPS project looking towards more complex queries, e.g. lists of genes that have been expressed and their up/down expression values as might arise in microarray experiments Collaboration with Cornell and Riken Institute, Japan BRIDGES to be refined/extended and used within the (not so!) recently funded Scottish Bioinformatics Research Network UK e-Science AHM 2005 DEMO UK e-Science AHM 2005