Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Microsoft Access wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Oracle Database wikipedia , lookup
Concurrency control wikipedia , lookup
Functional Database Model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Relational model wikipedia , lookup
Clusterpoint wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
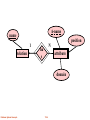
Storage and File Organization General Overview - rel. model Relational model - SQL Formal & commercial query languages Functional Dependencies Normalization Physical Design Indexing Database System Concepts 11.2 Review DBMSs store data on disk Disk characteristics: 2 orders of magnitude slower than MM Unit of read/write operations a block/page (multiple of sectors) Access time = seek time + rotation time + transfer time Sequential I/O much faster than random I/O Database Systems try to minimize the overhead of moving data from and to disk Database System Concepts 11.3 Review Methods to improve MM to/from disk transfers 1. Improve the disk technology a. Use faster disks (more RPMs) b. Parallelization (RAID) + some redundancy 2. Avoid unnecessary reads from disk a. Buffer management: go to buffer (MM) instead of disk b. Good file organization 3. Other (OS based improvements): disk scheduling (elevator algorithm, batch writes, etc) Database System Concepts 11.4 Buffer Management Keep pages in a part of memory (buffer), read directly from there What happens if you need to bring a new page into buffer and buffer is full: you have to evict one page Replacement policy: LRU : Least Recently Used (CLOCK) MRU: Most Recently Used Toss-immediate : remove a page if you know that you will not need it again Pinning (needed in recovery, index based processing,etc) Other DB specific RPs: DBMIN, LRU-k, 2Q Database System Concepts 11.5 File Organization Basics A database is a collection of files, file is a collection of records, record (tuple) is a collection of fields (attributes) Files are stored on Disks (that use blocks to read and write) Two important issues: 1. Representation of each record 2. Grouping/Ordering of records and storage in blocks Database System Concepts 11.6 File Organization Goal and considerations: Compactness Overhead of insertion/deletion Retrieval speed: sometime we prefer to bring more tuples than necessary in MM and use CPU to filter out the unnecessary ones! Database System Concepts 11.7 Record Representation Fixed-Length Records Example Account( acc-number char(10), branch-name char(20), balance real) Each record is 38 bytes. Store them sequentially, one after the other Record0 at position 0, record1 at position 38, record2 at position 76 etc Compactness (350 bytes) Database System Concepts 11.8 Fixed-Length Records Simple approach: Store record i starting from byte n (i – 1), where n is the size of each record. Record access is simple but records may cross blocks Modification: do not allow records to cross block boundaries Insertion of record i: Add at the end Deletion of record i: Two alternatives: move records: 1. i + 1, . . ., n to i, . . . , n – 1 2. record n to i do not move records, but link all free records on a free list Database System Concepts 11.9 Free Lists 2nd approach: FLR with Free Lists Store the address of the first deleted record in the file header. Use this first record to store the address of the second deleted record, and so on Can think of these stored addresses as pointers since they “point” to the location of a record. More space efficient representation: reuse space for normal attributes of free records to store pointers. (No pointers stored in in-use records.) Better handling ins/del Less compact: 420 bytes Database System Concepts 11.10 Variable-Length Records 3rd approach: Variable-length records arise in database systems in several ways: Storage of multiple record types in a file. Record types that allow variable lengths for one or more fields. Record types that allow repeating fields or multivalued attribute. Byte string representation Attach an end-of-record () control character to the end of each record Difficulty with deletion (leaves holes) Difficulty with growth 4 Field Count Database System Concepts R1 R2 11.11 R3 Variable-Length Records: Slotted Page Structure 4th approach VLR-SP Slotted page header contains: number of record entries end of free space in the block location and size of each record Records stored at the bottom of the page External tuple pointers point to record ptrs: rec-id = <page-id, slot#> Database System Concepts 11.12 Rid = (i,N) Page i Rid = (i,2) Rid = (i,1) 20 N ... 16 2 24 N 1 # slots SLOT DIRECTORY Insertion: 1) Use FP to find space and insert 2) Find available ptr in the directory (or create a new one) 3) adjust FP and number of records Deletion ? Database System Concepts 11.13 Pointer to start of free space Variable-Length Records (Cont.) Fixed-length representation: reserved space pointers 5th approach: Fixed Limit Records (for VLR) Reserved space – can use fixed-length records of a known maximum length; unused space in shorter records filled with a null or end-of-record symbol. Database System Concepts 11.14 Pointer Method 6th approach: Pointer method Pointer method A variable-length record is represented by a list of fixed-length records, chained together via pointers. Can be used even if the maximum record length is not known Database System Concepts 11.15 Pointer Method (Cont.) Disadvantage to pointer structure; space is wasted in all records except the first in a a chain. Solution is to allow two kinds of block in file: Anchor block – contains the first records of chain Overflow block – contains records other than those that are the first records of chairs. Database System Concepts 11.16 Ordering and Grouping records Issue #1: In what order we place records in a block? 1. Heap technique: assign anywhere there is space 2. Ordered technique: maintain an order on some attribute So, we can use binary search if selection on this attribute. Database System Concepts 11.17 Sequential File Organization Suitable for applications that require sequential processing of the entire file The records in the file are ordered by a search-key Database System Concepts 11.18 Sequential File Organization (Cont.) Deletion – use pointer chains Insertion –locate the position where the record is to be inserted if there is free space insert there if no free space, insert the record in an overflow block In either case, pointer chain must be updated Need to reorganize the file from time to time to restore sequential order Database System Concepts 11.19 Clustering File Organization Simple file structure stores each relation in a separate file Can instead store several relations in one file using a clustering file organization E.g., clustering organization of customer and depositor: SELECT account-number, customer-name FROM depositor d, account a WHERE d.customer-name = a.customer-name H good for queries involving depositor customer, and for queries involving one single customer and his accounts H bad for queries involving only customer H results in variable size records Database System Concepts 11.20 File organization Issue #2: In which blocks should records be placed Many alternatives exist, each ideal for some situation , and not so good in others: Heap files: Add at the end of the file.Suitable when typical access is a file scan retrieving all records. Sorted Files:Keep the pages ordered. Best if records must be retrieved in some order, or only a `range’ of records is needed. Hashed Files: Good for equality selections. Assign records to blocks according to their value for some attribute Database System Concepts 11.21 Data Dictionary Storage Data dictionary (also called system catalog) stores metadata: that is, data about data, such as Information about relations names of relations names and types of attributes of each relation names and definitions of views integrity constraints User and accounting information, including passwords Statistical and descriptive data number of tuples in each relation Physical file organization information How relation is stored (sequential/hash/…) Physical location of relation operating system file name or disk addresses of blocks containing records of the relation Information about indices (Chapter 12) Database System Concepts 11.22 Data dictionary storage Stored as tables!! E-R diagram? Relations, attributes, domains Each relation has name, some attributes Each attribute has name, length and domain Also, views, integrity constraints, indices User info (authorizations etc) statistics Database System Concepts 11.23 A-name name 1 relation position N ha s attribute domain Database System Concepts 11.24 Data Dictionary Storage (Cont.) A possible catalog representation: Relation-metadata = (relation-name, number-of-attributes, storage-organization, location) Attribute-metadata = (attribute-name, relation-name, domain-type, position, length) User-metadata = (user-name, encrypted-password, group) Index-metadata = (index-name, relation-name, index-type, index-attributes) View-metadata = (view-name, definition) Database System Concepts 11.25 Large Objects Large objects : binary large objects (blobs) and character large objects (clobs) Examples include: text documents graphical data such as images and computer aided designs audio and video data Large objects may need to be stored in a contiguous sequence of bytes when brought into memory. If an object is bigger than a page, contiguous pages of the buffer pool must be allocated to store it. May be preferable to disallow direct access to data, and only allow access through a file-system-like API, to remove need for contiguous storage. Database System Concepts 11.26 Modifying Large Objects If the application requires insert/delete of bytes from specified regions of an object: B+-tree file organization (described later in Chapter 12) can be modified to represent large objects Each leaf page of the tree stores between half and 1 page worth of data from the object Special-purpose application programs outside the database are used to manipulate large objects: Text data treated as a byte string manipulated by editors and formatters. Graphical data and audio/video data is typically created and displayed by separate application checkout/checkin method for concurrency control and creation of versions Database System Concepts 11.27 Data organization and retrieval File organization can improve data retrieval time Select * From depositors Where bname=“Downtown” Ordered File Heap OR Brighton A-217 Mianus A-215 100 blocks Downtown A-101 Perry A-218 Downtown A-101 200 recs/block Downtown A-110 Ans: 150 recs ...... .... Searching a heap: must search all blocks (100 blocks) Searching an ordered File: 1. Binary search for the 1st tuple in answer : log 100 = 7 block accesses 2. scan blocks with answer: no more than 2 Total <= 9 block accesses Database System Concepts 11.28 Data organization and retrieval But... file can only be ordered on one search key: Ordered File (bname) Brighton Downtown Downtown ...... A-217 A-101 A-110 Ex. Select * From depositors Where acct_no = “A-110” Requires linear scan (100 BA’s) Solution: Indexes! Auxiliary data structures over relations that can improve the search time Database System Concepts 11.29 A simple index Index file A-101 A-102 A-110 A-215 A-217 ...... Brighton Downtown Downtown Mianus Perry ...... A-217 A-101 A-110 A-215 A-102 700 500 600 700 400 Index of depositors on acct_no Index records: <search key value, pointer (block, offset or slot#)> To answer a query for “acct_no=A-110” we: 1. Do a binary search on index file, searching for A-110 2. “Chase” pointer of index record Database System Concepts 11.30 Index Choices 1. Primary: index search key = physical order search key vs Secondary: all other indexes Q: how many primary indices per relation? 2. Dense: index entry for every search key value vs Sparse: some search key values not in the index 3. Single level vs Multilevel (index on the indices) Database System Concepts 11.31 Measuring ‘goodness’ On what basis do we compare different indices? 1. Access type: what type of queries can be answered: selection queries (ssn = 123)? range queries ( 100 <= ssn <= 200)? 2. Access time: what is the cost of evaluating queries Measured in # of block accesses 3. Maintenance overhead: cost of insertion / deletion? (also BA’s) 4. Space overhead : in # of blocks needed to store the index Database System Concepts 11.32 Indexing Primary (or clustering) index on SSN 123 234 345 456 567 Database System Concepts STUDENT Ssn Name 123 smith 234 jones 345 smith … … 11.33 Address main str forbes ave forbes ave … Indexing Secondary (or non-clustering) index: duplicates may exist forbes ave forbes ave forbes ave main str main str Address-index Database System Concepts • Can have many secondary indices • but only one primary index STUDENT Ssn Name 123 smith 234 jones 345 tomson 456 stevens 567 smith 11.34 Address main str forbes ave main str forbes ave forbes ave Indexing secondary index: typically, with ‘postings lists’ Postings lists forbes ave main str Database System Concepts STUDENT Ssn Name 123 smith 234 jones 345 tomson 456 stevens 567 smith 11.35 Address main str forbes ave main str forbes ave forbes ave Indexing Primary/sparse index on ssn (primary key) 123 456 >=123 … >=456 Database System Concepts STUDENT Ssn Name 123 smith 234 jones 345 tomson 456 stevens 567 smith 11.36 Address main str forbes ave main str forbes ave forbes ave Indexing Secondary / dense index 123 234 345 456 567 Database System Concepts Secondary on a candidate key: No duplicates, no need for posting lists Ssn 345 234 123 567 456 11.37 Name tomson jones smith smith stevens Address main str forbes ave main str forbes ave forbes ave Primary vs Secondary 1. Access type: Primary: SELECTION, RANGE Secondary: SELECTION, RANGE but index must point to posting lists 2. Access time: Primary faster than secondary for range (no list access, all results clustered together) 3. Maintenance Overhead: Primary has greater overhead (must alter index + file) 4. Space Overhead: Database System Concepts secondary has more.. (posting lists) 11.38 Dense vs Sparse 1. Access type: both: Selection, range (if primary) 2. Access time: Dense: requires lookup for 1st result Sparse: requires lookup + scan for first result 3. Maintenance Overhead: Dense: Must change index entries Sparse: may not have to change index entries 4. Space Overhead: Dense: 1 entry per search key value Sparse: < 1 entry per search key value Database System Concepts 11.39 Summary • All combinations are possible Dense Sparse Primary rare usual secondary usual • at most one sparse/clustering index • as many as desired dense indices • usually: one primary index (probably sparse) and a few secondary indices (non-clustering) Database System Concepts 11.40