Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
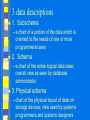
Database Management Infsy 540 Dr. R. Ocker Importance of data & information Data and information are corporate resources which must be managed. Data Bases The management of the information resource is now handled through data bases We will cover how information used to be managed (file environments) and how it has progressed to its current state Hierarchy of data organization in computer storage bit byte filed record file database Hierarchy of Data Organization in Computer Storage Example Component of Data Organization SUPPLIERS Database Logical Components File PARTS SHIPMENTS SUPPLIERS NO. NAME STREET ADDRESS 13 50.Oak Gasket Co. CITY ST ZIP Tifflin OH 44883 . . 3251 Reliable Supp. 11 Cedar Teaneck NJ 07666 Record Field (attribute) Physical (Storage) Components Byte Bit 13 Gasket Co. 50 Oak Tifflin Reliable Suppliers 01000001 (represents “A” in the ASCII-8 character code) 0 OH 44883 Traditional file environment most orgs. began information processing on a small scale automating one application at a time systems grew independently - not according to a grand plan typically, each division developed its own applications Traditional file environment within each division, – each functional area developed systems in isolation from other functional areas – accounting, finance, manufacturing etc. all developed their own systems and data files. traditional file processing – encourages each functional area in a corporation to develop specialized applications Traditional file environment each application requires a unique data file – probably a subset of a larger master file subsets of the master file lead to data redundancy, processing inflexibility and wasted storage resources these “islands of information systems” made it difficult to integrate information Problems with traditional file environment 1.data redundancy – presence of duplicate data in multiple files – error prone 2. lack of flexibility – traditional file system cannot deliver ad hoc reports – information needed for ad hoc reports is somewhere in the system, but too difficult/expensive to easily retrieve Problems with traditional file environment 3. poor security – because there is little control or management of data, access to and dissemination of information is not controlled 4. lack of data sharing and availability – due to lack of control over data resource, not easy to share data - pieces of information is in different files in different parts of organization File environment Data and the programs that use them are highly interdependent DATA BASE Environment data base - consists of data elements and the relationships between them it is a collection of data organized to – service many applications at the same time – by storing and managing data so that they appear to be in one location DATA BASE Environment DBMS - database management system special software to create and maintain a database and allow individual business applications to extract data they need without having to create separate files DBMS promotes independence between data, programs, and the database Logical and Physical views of Data DBMS separates the logical and physical views of data logical view - presents data as they would be perceived by end users or business specialists physical view - shows how data are actually organized and structured on physical storage media (e.g. within the database) DBMS and data definition DBMS enables us to define a database on 3 levels subschema schema physical schema Schema since there are many different pieces of data, we need a map showing how the data are associated map sometimes called a data model or schema complete logical view of the database Schema logical description of an entire database shows the relationships among the data – chart of types of data that are used; – gives names of groups and relationships between them; – framework Subschema logical description of the part of a database required by a particular function or application program application programmer/user does not need to know about the entire database schema neither schemas nor subschema reflects the way the data are stored physically 3 data descriptions 1. Subschema – a chart of a portion of the data which is oriented to the needs of one or more programmers/users 2. Schema – a chart of the entire logical data base; overall view as seen by database administrator 3. Physical schema – chart of the physical layout of data on storage devices; view seen by systems programmers and systems designers Advantages of DBMS reduces complexity by central management of data, access, utilization and security data redundancy and inconsistency can be reduced by eliminating files in which the same data elements are repeated program-data independence -programs can be written independently of the physical layout of the data; if physical layout of data changes, applications are unaffected Advantages of DBMS program development and maintenance costs can be reduced flexibility of IS can be enhanced by permitting rapid and inexpensive ad hoc queries access and availability of info. can be increased data base models data model - method for organizing databases on the conceptual level different types of database models hierarchical, network, relational, objectoriented Relational Model data files are represented as tables – rows and columns – called relations each relation is given a name column – called an attribute and given a name row – called a tuple – contains data Tables/Relations table rows are records for individual entities table columns are fields of the records – describe the attributes of the entities Relations different subjects/topics are stored in separate tables – e.g. employee table and sales table instance of a relation – the content of the relation at a particular instant in time Properties of relations There is one column in the relation for each attribute of the relation. Each column is given a name that is unique in the relation. The order of the columns or attributes in the relation has no significance The order of the rows is not significant. There cannot be any duplicate rows. Relation Key relation key – an attribute or set of attributes that uniquely identifies tuples (rows) in a relation. A relation key is formally defined as a set of one or more relation attributes joined together. all records in a table must have a unique primary key - can be a group of attributes combined to form a unique identifier Designing a Relational Database to design a database – break down the information you want to keep as separate subjects – then determine how the subjects are related to each other. Steps 1. determine the purpose of the database – this will determine what information you want from the database. – From this, you can determine what subjects you need to store facts about (the tables) and what facts you need to store about each subject (the fields/attributes of the tables) Steps 2. determine the tables – can be the trickiest step in the database design process. – The reports you want to print, the forms you want to use, the questions you want answered - don't necessarily provide clues about the structure of the tables that produce them. – These things tell you what you want to know, but not how to categorize the information into tables. Steps 3. determine the fields (attributes) – decide what you need to know about the people, things, or events recorded in the table. – Fields/attributes - describe characteristics of the table. – Each record/row in the table contains the same set of fields – Each field in the table should relate directly to the subject of the table. Steps 4. Determine the primary key – the power in a relational database management system – comes from its ability to quickly search for, find and bring together information stored in separate tables. – To do this, each table in the database should include a field or set of fields that uniquely identifies each individual row in the table. – This is called a primary key. Steps 5. determine the relationships – Once information has been divided into tables, you need a way to bring it back together again in meaningful ways. – You create relationships between the tables in your database. – The DBMS uses the relationships to find associated information stored in the tables. Steps To set up a relationship between two tables - Table A and Table B – you add one table's primary key to the other table, so that it appears in both tables. Steps 6. refine your design test your design by entering some records in each table - look at relationships. Fix database where necessary. Trends in Database Management Distributed databases data warehouses data mining Distributed processing and distributed data bases distributed processing – the distribution of computer processing – among multiple geographically or functionally separate locations – linked by a communications network distributed database - one that is stored in more than one physical location A System with a Distributed Database Site 1 Site 3 . . . Database Fragment 1 Telecommunications Network Database Fragment 3 Site 2 Users have access to the entire database over the network . . . Database Fragment 2 Distributed Data Bases data are placed where they are used most often but entire database available to each user enable structure of the database to mirror the structure of the org. – traffic on the network is lessened bec. data maintained where they are used the most Data warehouses Subject-oriented, integrated collection of data, both internal and external data accumulated over time maintained to support decision making Data warehouses Objective – to continually select data from operational databases – transform the data into a uniform format – open warehouse to endusers through an easy-to-use interface Power of data warehouses Offer users analytical tools such as decision support systems and on-line analytical processing for data mining Data mining Automated discovery of potentially significant relationships among various categories of data use specialized software e.g. an insurance company discovers the best predictors of the frequency of a certain type of claim