Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Microsoft SQL Server wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Relational model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Clusterpoint wikipedia , lookup
Functional Database Model wikipedia , lookup
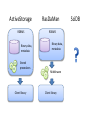
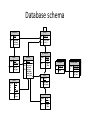
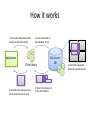
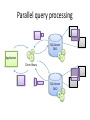
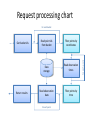
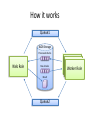
Активное распределенное хранилище для многомерных массивов Дмитрий Медведев ИКИ РАН Scientific data arrays • Arrays are widely used in environmental sciences to store modelling results, satellite observations, raster maps, etc. • Datasets can be quite large, up to several terabytes. • Most data are stored as file collections in proprietary formats or universally adopted formats like netCDF, GRIB, HDF5. • File access can be problematic: Scientists need to know about too many file formats Usually files must be completely downloaded before they can be used Thousands of files can be processed in one data request; only a small portion of their contents appears in the result set • Currently available database solutions do not have convenient array storage capabilities. ActiveStorage • ActiveStorage is a generic storage for arrays of primitive data types. • Its data model is based on the Unidata’s Common Data Model, used in netCDF, HDF5 and OpenDAP. • Basically, ActiveStorage is a SQL Server database with CLR stored procedures and a client library. • The stored procedures and the client library provide an abstraction layer for data access. • Large arrays are split into chunks and can be spread across several parallel database servers for better performance. ActiveStorage RDBMS Binary data, metadata RasDaMan RDBMS Binary data, metadata Stored procedures Middleware Client library Client library SciDB Common Data Model Dataset -name Group -name DataType Dimension Attribute -name -length -name -value -dataType Variable -char -byte -short -int -long -float -double -String -name -shape -dataType This is the Common Data Model (CDM) used in the recent versions of OpenDAP, netCDF and HDF5. Its purpose is the representation of multidimensional scientific data. Database schema dimensions groups PK dim_id PK group_id FK1 dim_group dim_name dim_length FK1 group_name parent_id grp_attributes shapes PK,FK2 PK FK1 var_id dim_index dim_id dim_type variables PK var_id FK1 var_group var_name var_type data_table index_table vector_size FK2 PK,FK1 PK group_id att_name FK2 att_type att_value types PK type_id servers PK,FK1 PK PK PK type_name type_length var_id host port db_name login passwd var_attributes PK,FK2 PK var_id att_name FK1 att_type att_value data table data table data table PK chunk_key PK chunk_key PK chunk_key chunk chunk chunk directory table directory table directory table PK,FK1 chunk_key PK,FK1 chunk_key PK dim_index PK,FK1 chunk_key PK dim_index PK dim_index key_min key_min key_max key_min key_max key_max Splitting an array into chunks Non-chunked array 1 seek 8 seeks Chunked array • We store chunks in BLOB fields of a database table • Chunks do not need to be the same size 4 seeks 4 seeks chunk_key chunk 0 <Chunk0> 1 <Chunk1> 2 <Chunk2> 3 <Chunk3> Data and directory tables ns1_air0_directory ns1_air0_data PK chunk_key chunk PK,FK1 PK chunk_key dim_index I1 I1 key_min key_max Two tables are automatically created for each new variable: • Data table • Directory table The data table stores data chunks in BLOB columns. The directory table contains information about chunk boundaries. A chunk consists of a header and a data block. Header x0min x0max ... Data xn-1min xn-1max How it works 1. Pass multi-dimensional data request to the client library 2. Issue commands to the database server Application Client library 4. Assemble the data parts into one multi-dimensional array SQL Server DB 3. Return the data parts to the client library 3. Select the requested data from several chunks Parallel query processing SQL Server DB 1 Application Client library SQL Server DB 2 Parallel query performance 1 database server 4 parallel database servers NCEP/NCAR Weather Reanalysis • Continually updating gridded data set • Incorporates observations and global climate model output • 74 weather parameters • 5000 netCDF files, 30 – 500 MB each Time coverage: Grids: • 1948 – 2008 • Regular grid, 2.5 x 2.5 degrees • 4-hourly values • T62 Gaussian grid, 192 x 94 points. Database contents NCEP/NCAR Weather Reanalysis Database Group: “ns5” Group: “ns2” Group: “ns4” Group: “ns1” Group: “ns3” “time” “time” “lat” data data data “lon” “lat” “lon” “level” ns1 – Single-layer data on regular grid ns2 – Single-layer data on Gaussian grid ns3, ns4, ns5 – Multi-layer data on regular grid data data data NCDC Integrated Surface Database Fixed ground stations Ships Mobile stations Buoys • 1901 – 2008 time coverage. • 470 000 ASCII files packed with gzip. • 30 million sensors. • 50 GB packed; 400 GB unpacked. • 1.7 billion observations. When you’ve downloaded and unpacked the data... Control data section Mandatory data section Section marker Additional data section 0189010020999992007022817004+80050+016250FM-12+000899999V0202201N008019999999N0090001N1+00631+00541098651ADDGA1031+003009999KA1120N+99999... date time lat lon Group marker Parameter group Fixed stations ActiveStorage database for NCDC data The main challenges: • Observation times are irregular • Observations are distributed unevenly in time and space • Different stations have different sets of observed parameters • Huge number of observations M Modifications to ActiveStorage ActiveStorage was designed to handle dense multidimensional arrays, with only a small number of missing values. 0 It works well for regularly gridded data. 0 N Some multidimensional data are sparse and can not be represented by a single data block. Modifications to ActiveStorage 0 0 1 2 1 0 1 2 2 0 3 1 2 0 1 2 (3,0,x,y,z) • Sparse arrays can be represented as a tree hierarchy of dense data blocks • Some data blocks can be empty • Hierarchy levels are treated as additional dimensions Modifications to ActiveStorage data PK chunk_key directory PK,FK1 PK chunk_key dim_index I1 I1 key_min key_max chunk data PK chunk_key directory PK,FK1 PK chunk_key dim_index I1 I1 I1 var0 key_min key_max chunk data PK chunk_key directory PK,FK1 PK chunk_key dim_index I1 I1 I1 I1 var0 var1 key_min key_max chunk Time series representation Point IDs Time series • Time series are stored as a set of 1D arrays • 1 array → 1 geographical point • One geographical point may have observations from several sensors • Sensors can be distinguished by observation parameters (station code, observation type, call letters, etc.) Buckets Bucket IDs Bucket latitude 1⁰ 2 2 5 9 5 6 9 longitude Arrays of point IDs 1⁰ • The whole spatio-temporal domain is divided into buckets • Each bucket contains a subset of observations from several geographical points • A set of IDs of geographical points is stored as a 1D array • For each bucket we store only those points that have observations in this bucket Database contents NCDC Integrated Surface Database Group: “mandatory” Group: additional “time” “buckets” “time” data data data “buckets” data data data coords pointId PK lat lon I1 I1 The “coords” table helps to select time series by latitude/longitude Request processing chart Get bucket ids Return results Read point ids from bucket Filter points by coordinates Data storage Read observation times Read observation data Filter points by time for each point for each point for each bucket Request processing times Location Sensors Observations Time Moscow 5 53621 1s Madrid 13 50992 2s Gulf of Guinea 195 3717 9s • Moscow, Madrid – fixed stations • Gulf of Guinea – buoys, ships Small number of sensors Large number of sensors Large number of observations Small number of observations * All requests are 2 x 2 degrees, 01/01/2007 – 12/31/2007 ActiveStorage on Windows Azure VMs VMs VMs HTTP Load Balancer IIS Web Role Instance Worker Role Instance Agent Agent HTTP Blobs Windows Azure Fabric Application Storage Compute Fabric … Tables Queues How it works Queue1 BLOB Storage Processed chunks Web Role Raw chunks Result Queue2 Worker Role Worker Role Worker Role ActiveStorage on Windows Azure Advantages Easy and natural implementation of parallel query execution. BLOB read rates are quite good: 6.5 MB/s + 0.1 s overhead. Very scalable. CTP problem: replication overhead BLOB writes are several times slower than SQL Server. Message exchange rate is slow (several seconds).