Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
An Effective Combination of Multiple
Classifiers for Toxicity Prediction
FSKD 2006, Xi’An, China
Gongde GUO, Daniel NEAGU, Xuming Huang and Yaxin Bi
1
Bradford, UK
Bradford,
West Yorkshire
National Museum of Film and Television
School of Informatics,
University of
Bradford
2
Outline
Short Introduction to Predictive Data Mining and Toxicology
Problems of Single Classifier-based Models for Predictive Toxicology
A Potential Solution: Multiple Classifier Systems
A Case Study of Model Library
Primitive Knowledge of Dempster-Shafer Theory
Mass and Belief Functions
Dempster’s Rule of Combination
Proposed Combination Scheme
Data sets (7)
Descriptors
Dimensionality
Machine Learning Algorithms
Feature Selection Methods
Organisation
Definition of a New Mass Function
Combination Method
Experimental Results
Conclusions
3
Predictive Data Mining
•
•
•
The processes of data classification/ regression
having the goal to obtain predictive models for a
specific target, based on predictive relationships
among large number of input variables.
Classification defines characteristics of data and
identifies a data item as member of one of several
predefined categorical classes.
Regression uses the existing numerical data
values and maps them to a real valued prediction
(target) variable.
4
Predictive Toxicology
Predictive Toxicology:
a multi-disciplinary science
requires close collaboration among toxicologists,
chemists, biologists, statisticians and AI/ML
researchers.
The goal of toxicity prediction is to describe
the relationship between chemical properties,
biological and toxicological processes:
relates features of a chemical structure to a
property, effect or biological activity associated with
the chemical
5
Problems of Single Classifier-based Models
for Predictive Toxicology
Most of the toxicity data sets contain:
Numerous irrelevant descriptors, e.g. there are 250
descriptors in PHENOLS data set. However, only few of
them (less than 20 descriptors) have high correlation to the
class.
Skewed distribution of classes and a low ratio of instances
to features, e.g. there are 253 descriptors in APC data set.
But only 116 instances are available for training and testing.
Moreover, the class distribution is uneven: 4:28:24:60
Missing values and noisy data.
Single classifier-based models, i.e. probabilistic
decision theory, discriminant analysis, fuzzy-neural
networks, belief networks, non-parametric methods,
tree-structured classifiers, and rough sets, are not
sufficiently discriminative for all the data sets
considered.
6
A Potential Solution:
Multiple Classifiers Systems
A multiple classifier system is a powerful solution to difficult
classification problems involving large sets and noisy input because it
allows simul’taneous use of ‘arbitrary feature descriptors and
classification pro’cedures.
The ultimate goal of designing a multiple classifier system is to achieve
the best possible classification performance for the task at hand. Empirical
studies have observed that different classifier designs potentially offer
complementary information about the patterns to be classified, which
could be harnessed to improve the performance of the selected classifier.
Many different approaches have been developed for classifier combination,
e.g. Majority voting, Entropy-based combination, Dempster-Shafer
theory-based combination, Bayesian classifier combination, Fuzzy
inference, Gating networks, Sta’tistical models.
7
A Case Study of Model Library
Datasets (1)
DEMETRA*
1.
2.
3.
4.
5.
LC50 96h Rainbow Trout
acute toxicity (ppm)
282 compounds
EC50 48h Water Flea acute
toxicity (ppm) (Daphnia)
264 compounds
LD50 14d Oral Bobwhite
Quail (mg/ kg)
116 compounds
LC50 8d Dietary Bobwhite
Quail (ppm)
123 compounds
LD50 48h Contact Honey
Bee (μg/ bee)
105 compounds
*http://www.demetra-tox.net
8
A Case Study of Model Library
Datasets (2)
CSL APC* Datasets
5 endpoints
A single endpoint/descriptor set used for our
experiments
Mallard Duck
LD50 toxicity value
60 organophosphates
248 descriptors
*http://www.csl.gov.uk
9
A Case Study of Model Library
Datasets (3)
TETRATOX*/LJMU** Dataset
Tetrahymena Pyriformis
inhibition of growth IGC50
Phenols data
250 phenolic compounds
187 descriptors
*http://www.vet.utk.edu/tetratox/
**http://www.ljmu.ac.uk
10
A Case Study of Model Library
Descriptors
Multiple descriptor types
Various software packages to calculate 2D and 3D
attributes*
http://www.demetra-tox.net
11
A Case Study of Model Library
Dimensionality
Dataset Four
Model
Parameter
file
Results
file
Feature Selection
Feature Selection
Feature Selection
Feature Selection
Dataset Three
Algorithms
Dataset Two
Algorithms
Dataset One
Algorithms
Algorithms
12
A Case Study of Model Library
Machine Learning Algorithms
Machine Learning algorithms are chosen for their
representability and diversity, easy, simple and fast
access.
Instance-based Learning algorithm (IBL)
Decision Tree learning algorithm (DT)
Repeated Incremental Pruning to Produce Error
Reduction (RIPPER)
Multi-Layer Perceptrons (MLPs)
Support Vector Machine (SVM)
13
A Case Study of Model Library
Feature Selection Methods
• Feature Selection Methods involved in this
study are:
Correlation-based feature selection (CFS)
Chi-Chi squared ranking filter (Chi)
Consistency Subset evaluator (CS)
Gain Ratio feature evaluation (GR)
Information Gain ranking filter (IG)
KNNMFS feature selection (KNNMFS)
ReliefF ranking filter (ReliefF)
SVM feature evaluator (SVM)
14
A Case Study of Model Library
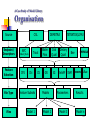
Organisation
Source
Endpoint/
Descriptors
Feature
Selection
File Type
Files
CSL
APC
Trout
Mallard_Duck
CFS
Chi
Feature Subsets
Model 1
CS
DEMETRA
Water
Flea
GR
Models
Model 2
Oral
Quail
IG
TETRATOX/LJMU
Dietary
Quail
ReliefF
Bee
SVM
Parameters
Model 3
PHENOLS
Raw
KNNMFS
Results
Model n
15
Primitive Knowledge of D-S Theory:
Mass and Belief Functions
Definition 1. Let Θ be a frame of discernment, given
a subset H
Θ, a mass function is defined as a mapping
m: 2Θ [0, 1], and satisfies the following conditions:
(1) m(Ø)=0
(2) H m( H ) 1
Definition 2. let Θ be a frame of discernment and m
be a mass function on Θ, the belief function of a subset
H Θ is defined as
Bel(H)= BH m( B )
and satisfies the following conditions:
(1) Bel(Ø)=0
(2) Bel(Θ)=1
16
Primitive Knowledge of D-S Theory:
Dempster’s Rule of Combination
Definition 3: Let m1 and m2 be two mass functions on
the frame of discernment Θ, and for any subset H Θ,
the orthogonal sum of two mass functions on H is
defined as:
m( H ) m1 m 2
(H )
1
X ,Y , X Y H
m1 ( X ) m2 (Y )
X ,Y , X Y
m1 ( X ) m 2 (Y )
The above equation is used to combine two mass
functions into a third mass function, pooling pieces of
evidence to support propositions of interest.
17
Proposed Combination Scheme
Definition of a New MASS Function
let be a classifier, C={c1,c2,…,c|C|} be a list of class labels, and d be any test instance, an
assignment of class labels to d is denoted by (d) = {s1,s2,…,s|C|}, where si 0,
i=1,2,…,|C| represents the relevance of the instance d to the class label ci. The greater
the score assigned to a class, the greater the possibility of the instance being under this
class. For convenience of discussion, we define a function , (ci)=si+ for all ci
C, where 1> >0 represents the prior knowledge of classifier . It is clear that
(ci)>0. Alternatively, (d) is written as (d)={ (c1), (c2),…, (c |C|)}
Definition 4. Let C be a frame of discernment, where each class label ci C is a
proposition that the instance d is of class label ci, and (d) be a piece of evidence that
indicates a possibility that the instance comes from each class label ciC, then a mass
function is defined as a mapping, m: 2C [0, 1], i.e. mapping a basic probability
assignment (bpa) to ci C for 1≤ i ≤ |C| as follows:
m({ci })
(ci )
where 1 i | C |
|C|
(
c
)
j1 j
18
Proposed Combination Scheme
Combination Method
Let be a group of L learning algorithms, 1k , 2k ,..., nk be a
group of classifiers associated with learning algorithm Lk , where
1 k L and n is a parameter that is related to the number of
feature subsets, then each of the classifiers, ik assigns an input
instance d to Yi k . The results output by multi-classifiers are
represented as a matrix:
Y11 Y21 Yn1
2 2
2
Y
Y
Y
n
1 2
L L
L
Y1 Y2 Yn
k
k
k
where Y i k is a vector denoted as (mi (c1 ), mi (c2 ), ...,mi (c|C| )).
m(.) - is the mass function defined before.
19
Proposed Combination Scheme
Combination Method - continue
The combination task based on this matrix is made both on the columns and
rows, i.e. for each column, all the rows will be combined using formula (1),
and then the combined results in each column will be combined again using
formula (2), therefore producing a new mass distribution over all the class
labels that represents the consensus of the assignments of the multiple
classifiers to test class labels. The final classification decision will be made
by using the decision rule of formula (3)
mi(ci ) mi1 mi2 ... miL [...[[ mi1 mi2 ] mi3 ] ... miL ] (ci )
(1)
bel(ci ) mi' m2' ... mK' [...[[ m1' m2' ] m3' ] ... mK' ]( ci )
(2)
DRC (d ) ci if bel(ci ) arg max c C {bel(ci ) | i 1,2,..., | C |}
(3)
i
20
Experimental Results (1)
85
Classification Accuracy
75
IBL
DT
RIPPER
65
MLP
SVM
MVC
55
MPC
APC
45
DRC
35
1
2
3
4
5
6
7
Data sets
21
Experimental Results (2)
Average Classification Accuracy
62
60
58
56
54
52
50
48
1
2
3
4
5
6
7
8
9
1-IBL 2-DT 3-RIPPER 4-MLPs 5-SVM 6-MVC 7-MPC 8-APC 9-DRC
22
Conclusions
In this work, we proposed an approach for combining multiple
classifiers using Dempster’s rule of combination. Based on our
experimental results, it is fairly to draw a conclusion:
• The performance of the combination method based on
Dempster’s rule of combination is better than that of any other
combination method studied.
• It is 2.97%, on average, better than the best individual
classification method SVM.
• Dempster’s rule of combination provides a theoretical
underpinning for achieving more accurate prediction through
aggregating the majority voting principle and the belief degrees
of decisions.
23
Acknowledgements
This work is part-funded by:
EPSRC GR/T02508/01: Predictive Toxicology Knowledge
Representation and Processing Tool based on a Hybrid
Intelligent Systems Approach
At: http://pythia.inf.brad.ac.uk/
EU FP5 Quality of Life DEMETRA QLRT-2001-00691:
Development of Environmental Modules for Evaluation of
Toxicity of pesticide Residues in Agriculture
At: http://www.demetra-tox.net
24
Thank you very much!
25