Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
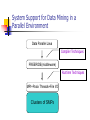
Research Overview Gagan Agrawal Associate Professor Personnel Involved Ph.D student Masters (thesis) student Ge Yang Undergrad student Liang Chen Wei Du Ruoming Jin Feng Li (Jointly with Joel Saltz) Xiaogang Li Leo Glimcher Faculty collaborations: Joel Saltz, Tahsin Kurc, Umit Catalyurek, Srini Parthasarathy, Raghu Machiraju An Overall Vision Our world will be full of distributed and dynamic data sources High speed networking (Grid computing) Sensor networks, mobile systems, embedded devices Processing this information involves many challenges A lot of data, distributed Often, continuous data streams (can’t store all data, realtime processing constraint) Complex interplay of communication and computational costs Application programmers want more transparency Research Projects Compilers: Compiling XQuery (Query Language for XML data), Compiling for a distributed heterogeneous (grid) environment, parallelizing scientific data intensive and data mining codes Middleware and Runtime Support: FREERIDE (Framework for Rapid Implementation of Datamining Engines), ongoing work on distributed processing of data streams Data mining and OLAP algorithms: Mining for streaming data, Parallel and scalable mining algorithms, OLAP algorithms Compiling Data Intensive Applications for a Grid Environment Compiling XQuery Vision: XML has become an accepted standard for distribution of datasets XQuery is the well-accepted high-level query language for querying and processing XML datasets Compiling complex data-intensive reduction operations written in XQuery Reductions written using recursion Data-centric execution strategies Using XML Schemas to describe the datasets - System Support for Data Mining in a Parallel Environment Data Parallel Java Compiler Techniques FREERIDE(middleware) Runtime Techniques MPI+Posix Threads+File I/O Clusters of SMPs Distributed Processing of Data Streams Processing continuous data streams arising from distributed sources A number of system and algorithmic challenges Real time requirement on processing rate – tradeoffs between accuracy of analysis and efficiency Placement of data – obviously want to process an individual stream close to the source of data Feedback based control of accuracy – cannot allow any computational or communication stage to become the bottleneck Performance modeling: impact of output size, level of sampling etc. on performance Recently started work in this area …. Algorithms for Mining and OLAP Decision tree construction for streaming data: new one-pass algorithm with statistical accuracy bound Parallel and scalable decision tree construction: use sampling, but without losing accuracy Data cube construction: Parallel algorithms with optimal communication volume Tiling based algorithms for scaling output sizes