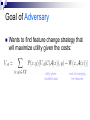Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
KDD 2004: Adversarial Classification Dalvi, Domingos, Mausam, Sanghai, Verma University of Washington Introduction Paper views classification as a game between classifier and the adversary Data is actively manipulated by the adversary to make classifier produce false negatives Proposes a (Naïve Bayes) classifier that is optimal given adversary’s optimal strategy Motivation (1) Many (all) data-mining algorithms assume that data-generating process is independent of classifier’s activities This is not true in domains like Spam detection Intrusion detection Fraud detection Surveillance Where data is actively manipulated by an adversary seeking to make classifier produce false negatives Motivation (2) In real world performance of classifier can degrade rapidly after deployment as adversary learns how to defeat it Solution: repeated, manual, ad hoc reconstruction of the classifier This problem is different from a concept drift, since data is actively manipulated – is a function of the classifier itself Outline Problem definition For Naïve Bayes: Optimal strategy for adversary against adversary-unaware classifier Optimal strategy for classifier playing against adversary Experimental results on 2 email spam datasets Problem definiton X = (X1, X2, … Xn) a set of features Instance space X. Instance x X has feature values xi Instances belong to 2 classes: Positive (malicious) are i.i.d. from P(X|+) Negative (innocent) are i.i.d. from P(X|–) Training set S, test set T A game between 2 players: Classifier tries to learn a function yC = C(x) that will correctly predict classes Adversary attempts to make Classifier classify positive (harmful) instances as negative by modifying an instance x: x’ = A(x) (note: adversary can not modify negative, ie. non-spam, instances) Cost/Utilities for Classifier Vi: cost of measuring feature Xi UC(yC, y): utility of classifying instance as yC having true class y Typically: –) < 0, UC(+, +) > 0, UC(+, UC(–, +) < 0 UC(–, –) > 0 makes an error correct classification Cost/Utilities for Adversary Wi(xi, x’): cost of changing ith feature from xi to xi’ UA(yC, y): utility accrued by adversary when classifier classifyes yc an instance of class y. Typically: UA(–, spam get through +) > 0 spam in detected UA(+, +) < 0 don’t care about non-spam UA(+, –) = 0, UA(–, –) = 0 Goal of Classifier Wants to build classifier C that will maximize expected utility taking into account adversaries actions: utility given modified data cost for observing a feature Goal of Adversary Wants to find feature change strategy that will maximize utility given the costs: utility given modified data cost of changing the features The game We assume that all parameters of both players are known to each other Game operates: 1. 2. 3. 4. Classifier starts assuming data in unaltered Adversary deploys optimal plan A(x) against classifier Classifier deploys optimal classifier C(A(x)) against adversary ... Classifier: No Adversary Naïve Bayes: Bayes’ optimal prediction given utility matrix for instance x is the class yC that maximizes: prediction expected utility Adversary strategy Adversary assumes: complete information classifier is unaware of adversary Naïve Bayes classifies x as positive if: Naïve Bayes Modify features so that inequality does not hold the cost is lower than expected utility Boils down to a integer linear program Classifier with Adversary Classifier assumes: training set is drawn from the real distribution Adversary uses optimal strategy Training set is not tampered by Adversary Maximize conditional utility: The only change is: adversary modifies only positive examples It will not modify example if: classifier’s prediction is negative, or transformation is to costly Naïve algorithm: for all positive examples and find probability they are modified Experiments 2 datasets: Ling-Spam: 2412 non-spam, 481 spam Email-Data: 642 non-spam, 789 spam Scenarios: Add words: adversary is adding words. Cost of adding a word is 1. (Adding unnecessary words) Add length: same as Add words, except cost is proportional to word length. (Spammer is paying for data transfer) Synonyms: replace existing word with its synonym. (Spammer does not want to alter the content) Utility matrix UA: adversary UC: classifier prediction true class +: spam –: no spam Scenarios: AddWords: can add max 20 words AddLength: can add max 200 characters Synonmy: can change max 20 synonyms False positives and False negatives By increasing UC we observe expected behavior AC never produces False Positive so average utility stays the same Adversary “helps” classifier to reduce FPs, because adversary is unlikely to send spam unaltered. So nonspam messages (unaltered) will now be classified as negative. Further work / Conclusions Further work: Repeated game Incomplete information Approximately optimal strategies Generalization to other classifiers Conclusions: Formalized the problem of adversarial manipulation Extended Naïve Bayes classifier Outperforms standard technique Other interesting papers (1) Best Paper: Probabilistic Framework for Semi-Supervised Clustering by Basu, Bilenko, and Mooney: gives a probabilistic model to find clusters that respect "must-link" and "cannot-link" constraints the EM-type algorithm is an incremental improvement over previous methods Other interesting papers (2) Data Mining in Metric Space: An Empirical Analysis of Supervised Learning Performance Criteria by Caruana and Niculescu-Mizil: a massive comparison of different learning methods with different binary datasets, on different measure of performance: accuracy given a threshold, area under the ROC curve, squared error, etc. measures that depend on ranking only, and measures that depend on scores being calibrated probabilities, form two clusters. maximum margin methods (SVMs and boosted trees) give excellent ranking but scores that are far from well-calibrated probabilities. squared error may be the best general-purpose measure. Other interesting papers (3) Cyclic Pattern Kernels for Predictive Graph Mining by Horvath, Gaertner, and Wrobel: kernel for classifying graphs based on cyclic and tree patterns Computationally efficient (does not suffer frequent sub-graphs limitations) they use it with SVM for classifying molecules