Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
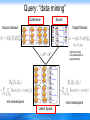
Heterogeneous Cross Domain Ranking in Latent Space Bo Wang1, Jie Tang2, Wei Fan3, Songcan Chen1, Zi Yang2, Yanzhu Liu4 1Nanjing University of Aeronautics and Astronautics 2Tsinghua University 3IBM T.J. Watson Research Center, USA 4Peking University 1 Introduction • The web is becoming more and more heterogeneous • Ranking is the fundamental problem over web – unsupervised v.s. supervised – homogeneous v.s. heterogeneous 2 Motivation Dr. Tang Association... write SVM... cite ISWC IJCAI 1) How to capture the correlation SDM between Authors heterogeneous objects? ICDM 2) How to preserve the preference orders PAKDD between objects across heterogeneous domains? WWW write ? Prof. Wang publish write write EOS... Semantic... write Pc member Data Mining: Concepts and Techniques Limin KDD ISWC publish Conferences write Main Challenges cite publish cite IJCAI Principles of Data Mining publish WWW cite Query: “data mining” Papers write Tree CRF... publish publish Prof. Li ? Annotation... coauthor Write coauthor ? P. Yu ? ? Dr. Tang Tree CRF... SVM... EOS... Prof. Wang Limin Heterogeneous cross domain ranking 3 Outline • Related Work • Heterogeneous cross domain ranking • Experiments • Conclusion 4 Related Work • Learning to rank – Supervised: [Burges, 05] [Herbrich, 00] [Xu and Li, 07] [Yue, 07] – Semi-supervised: [Duh, 08] [Amini, 08] [Hoi and Jin, 08] – Ranking adaptation: [Chen, 08] • Transfer learning – Instance-based: [Dai, 07] [Gao, 08] – Feature-based: [Jebara, 04] [Argyriou, 06] [Raina, 07] [Lee, 07] [Blitzer, 06] [Blitzer, 07] – Model-based: [Bonilla, 08] 5 Outline • Related Work • Heterogeneous cross domain ranking – Basic idea – Proposed algorithm: HCDRank • Experiments • Conclusion 6 Query: “data mining” Conference Source Domain Expert KDD KDD A X PKDD SDM B Y PAKDD ADMA C Z Target Domain Jiawei Han Alice Jie Tang Jerry Bo Wang Bob Tom might be empty! (no labelled data in target domain) KDD A Jiawei Han PKDD B Jerry PAKDD C Jie Tang Bob mis-ranked pairs KDD X SDM Y ADMA Z Alice Bo Wang Tom Latent Space 7 mis-ranked pairs Learning Task In the HCD ranking problem, the transfer ranking task can be defined as: Given limited number of labeled data L_T, a large number of unlabeled data S from the target domain, and sufficiently labeled data L_S from the source domain, the goal is to learn a ranking function f_T^* for predicting the rank levels of unlabeled data in the target domain. Key issues: -Different feature distributions/different feature spaces -Number of rank levels different -Number of labeled training examples very unbalanced (thousands vs a few) 8 The Proposed Algorithm — HCDRank How to optimize? Loss function in source domain How to define? Loss function in target domain penalty Non-convex Loss function: Number of mis-ranked pairs unsolvable C: cost-sensitive parameter which deals with imalance of labeled data btwn domains \lambda: balances the empirical loss and the penalty 10 Dual problem alternately optimize matrix M and D O(2T*sN logN) O((2T+1)*sN log(N) + d3 Construct transformation matrix d: feature number, N = nr of instance O(d3) of nonpairs for training, s: number zero features 11 Learn weight vector of target domain learning in latent space Apply learnt weight vector to predict O(sN logN) Outline • Related Work • Heterogeneous cross domain ranking • Experiments – Ranking on Homogeneous data – Ranking on Heterogeneous data – Ranking on Heterogeneous tasks • Conclusion 12 Experiments • Data sets – Homogeneous data set: LETOR_TR • 50/75/106 queries with 44/44/25 features for TREC2003_TR, TREC2004_TR and OHSUMED_TR – Heterogeneous academic data set: ArnetMiner.org • 14,134 authors, 10,716 papers, and 1,434 conferences – Heterogeneous task data set: • 9 queries, 900 experts, 450 best supervisor candidates • Evaluation measures – P@n : Precision@n – MAP : mean average precision – NDCG : normalized discount cumulative gain 13 Ranking on Homogeneous data • LETOR_TR – We made a slight revision of LETOR 2.0 to fit into the crossdomain ranking scenario – three sub datasets: TREC2003_TR, TREC2004_TR, and OHSUMED_TR • Baselines 14 TREC2003_TR TREC2004_TR Cosine Similarity=0.01 Cosine Similarity=0.23 OHSUMED_TR 15 Cosine Similarity=0.18 Observations • Ranking accuracy HCDRank is +5.6% to +6.1% in terms of MAP better • Effect of difference when cosine similarity is high (TREC2004), simply combining the two domains would result in a better ranking performance • Training time: next slide 16 Training Time BUT: HCDRank can easily be parallelized And training process only needs to be run once on a data set 17 Ranking on Heterogeneous data • ArnetMiner data set (www.arnetminer.org) 14,134 authors, 10,716 papers, and 1,434 conferences • Training and test data set: – 44 most frequent queried keywords from log file • Author collection: Libra, Rexa and ArnetMiner • Conference collection: Libra, ArnetMiner • Ground truth: – Conference: online resources – Expert: two faculty members and five graduate students from CS provided human judgments for expert ranking 18 Feature Definition Features Description L1-L10 Low-level language model features H1-H3 High-level language model features S1 How many years the conference has been held S2 The sum of citation number of the conference during recent 5 years S3 The sum of citation number of the conference during recent 10 years S4 How many years have passed since his/her first paper S5 The sum of citation number of all the publications of one expert S6 How many papers have been cited more than 5 times S7 How many papers have been cited more than 10 times 16 features for a conference, 17 features for an expert 19 Expert Finding Results 20 Observations • Ranking accuracy HCDRank outperforms the baselines especially the two unsupervised systems • Feature analysis next slide: final weight vectors which exploits the data information from two domains and adjusts the weight learn from single domain data • Training time: next slide 21 Feature Correlation Analysis 22 Ranking on Heterogeneous tasks • Expert finding task v.s. best supervisor finding task • Training and test data set: – expert finding task: ranking lists from ArnetMiner or annotated lists – best supervisor finding task: 9 most frequent queries from log file of ArnetMiner • For each query, we collected 50 best supervisor candidates, and sent emails to 100 researchers for annotation • Ground truth: – Collection of feedbacks about the candidates (yes/ no/ not sure) 23 Best supervisor finding • Training/test set and ground truth – 724 mails sent – Fragment of mail 24 – Feedbacks in effect > 82 (increasing) – Rate each candidate by the definite feedbacks (yes/no) 24 Feature Definition Features L1-L10 H1-H3 B1 B2 B3 B4 B5 B6 B7 B8 SumCo1-SumCo8 AvgCo1-AvgCo8 SumStu1-SumStu8 AvgStu1-AvgStu8 25 Description Low-level language model features High-level language model features The year he/she published his/her first paper The number of papers of an expert The number of papers in recent 2 years The number of papers in recent 5 years The number of citations of all his/her papers The number of papers cited more than 5 times The number of papers cited more than 10 times PageRank score The sum of coauthors’ B1-B8 scores The average of coauthors’ B1-B8 scores The sum of his/her advisees’ B1-B8 scores The average of his/her advisees’ B1-B8 scores Best supervisor finding results 26 Outline • Related Work • Heterogeneous cross domain ranking • Experiments • Conclusion 28 Conclusion • Formally define the problem of heterogeneous cross domain ranking and propose a general framework • We provide a preferred solution under the regularized framework by simultaneously minimizing two ranking loss functions in two domains • The experimental results on three different genres of data sets verified the effectiveness of the proposed algorithm 29