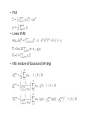Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Large Scale Machine Learning based on MapReduce & GPU Lanbo Zhang Motivation • Massive data challenges – More and more data to process (Google: 20,000 terabytes per day) – Data arrives faster and faster • Solutions – Invent faster ML algorithms: online algorithms • Stochastic gradient decent v.s. batch gradient decent – Parallelize learning processes: MapReduce, GPU, etc. MapReduce • A programming model invented by Google – Jeffrey Dean , Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, Proceedings of the 6th conference on Symposium on Opearting Systems Design & Implementation (OSDI), p.10-10, December 06-08, 2004, San Francisco, CA • The objective – To support distributed computing on large data sets on clusters of computers • Features – – – – Automatic parallelization and distribution Fault-tolerance I/O scheduling Status and monitoring User Interface • Users need to implement two functions – map (in_key, in_value) -> list(out_key, intermediate_value) – reduce (out_key, list(intermediate_value)) -> list(out_value) • Example: Count word occurrences Map (String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: EmitIntermediate(w, "1"); Reduce (String output_key, Iterator intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result)); MapReduce Usage Statistics in Google MapReduce for Machine Learning • C. T. Chu, S. K. Kim, Y. A. Lin, Y. Yu, G. R. Bradski, A. Y. Ng, and K. Olukotun, "Map-reduce for machine learning on multicore," in NIPS 2006 • Algorithms that can be expressed in summation form could be parallelized in the MapReduce framework – Locally weighted linear regression (LWLR) – Logistic regression(LR): Newton-Raphson method – Naive Bayes (NB) – PCA – Linear SVM – EM: mixture of Gaussians (M-step) Time complexity P: # of cores P’: speedup of matrix inversion and eigen-decomposition on multicore Experimental Results Speedup from 1 to 16 cores over all datasets Apache Hadoop • http://hadoop.apache.org/ • An open-source implementation of MapReduce • An excellent tutorial – http://hadoop.apache.org/common/docs/current/mapred_tutorial.html (with the famous examples of WordCount) – Very helpful if you need to quickly develop a simple Hadoop program • A comprehensive book – Tom White. Hadoop: The Definitive Guide. O'Reilly Media. May 2009 http://oreilly.com/catalog/9780596521981 – Topics: Hadoop distributed file system, Hadoop I/O, How to set up a Hadoop cluster, how to develop a Hadoop application, Administration, etc. – Helpful if you want to become a Hadoop expert Key User Interfaces of Hadoop • Class Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT> – Implement the map function to define your map routines • Class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> – Implement the reduce function to define your reduce routines • Class JobConf – the primary interface to configure job parameters, which include but not limited to: • • • • Input and output path (Hadoop Distributed File System) Number of Mappers and Reducers Job name … Apache Mahout • http://lucene.apache.org/mahout/ • A library of parallelized machine learning algorithms implemented on top of Hadoop • Applications – Clustering – Classification – Batch based collaborative filtering – Frequent itemset mining –… Mahout in progress • Algorithms already implemented – K-Means, Fuzzy K-Means, Naive Bayes, Canopy clustering, Mean Shift, Dirichlet process clustering, Latent Dirichlet Allocation, Random Forests, etc. • Algorithms to be implemented – Stochastic gradient decent, SVM, NN, PCA, ICA, GDA, EM, etc. GPU for Large-Scale ML • Graphics Processing Unit (GPU) is a specialized processor that offloads 3D or 2D graphics rendering from the CPU • GPUs’ highly parallel structure makes them more effective than general-purpose CPUs for a range of complex algorithms NVIDIA GeForce 8800 GTX Specification Number of Streaming Multiprocessors 16 Multiprocessor Width 8 Local Store Size 16 KB Total number of Stream Processors 128 Peak SP Floating Point Rate 346 Gflops Clock 1.35 GHz Device Memory 768 MB Peak Memory Bandwidth 86.4 GB/s Connection to Host CPU PCI Express CPU -> GPU bandwidth 2.2 GB/s* GPU -> CPU bandwidth 1.7 GB/s* Logical Organization to Programmers • Each block can have up to 512 threads that synchronize • Millions of blocks can be issued Programming Environment: CUDA • Compute Unified Device Architecture (CUDA) • A parallel computing architecture developed by NVIDIA • The computing engine in GPUs is accessible to software developers through industry standard programming language SVM on GPUs • Catanzaro, B., Sundaram, N., and Keutzer, K. 2008. Fast support vector machine training and classification on graphics processors. In Proceedings of the 25th international Conference on Machine Learning (Helsinki, Finland, July 05 - 09, 2008). ICML '08, vol. 307. SVM Training • Quadratic Program • The SMO algorithm SVM Training on GPU • Each thread computes the following variable for each point: Result: SVM training on GPU (Speedup over LibSVM) 40 35 30 25 20 15 10 5 0 Adult Faces Forest Mnist Usps Web SVM Classification • SVM classification task involves finding which side of the hyperplane a point lies on • Each thread evaluates kernel function for a point Result: SVM classification on GPU (Speedup over LibSVM) GPUMiner: Parallel Data Mining on Graphics Processors • Wenbin Fang, etc. Parallel Data Mining on Graphics Processors. Technical Report HKUST-CS08-07, Oct 2008 • Three components – The CPU-based storage and buffer manager to handle I/O and data transfer between CPU and GPU – The GPU-CPU co-processing parallel mining module – The GPU-based mining visualization module • Two mining algorithms implemented – K-Means clustering – Apriori (frequent pattern mining algorithm) GPUMiner: System Architecture The bitmap technique • Use a bitmap to represent the association between data objects and clusters (for K-means), and the association between items and transactions (for Apriori) • Supports efficient row-wise and column-wise operations exploiting the thread parallelism on the GPU • Use a summary vector to store the number of ones to accelerate counting on the number of ones in a row/column K-means • Three functions executed on GPU in parallel – makeBitmap_kernel – computeCentriod_kernel – findCluster_kernel Apriori • To find those frequent itemsets among a large number of transactions • The trie-based implementation – – – – Uses a trie to store candidates and their supports Uses a bitmap to store the Item-Transaction matrix Obtain the item supports by counting 1s in the bitmap The 1-bit counting and intersection operations are implemented as GPU programs Experiments • Settings – GPU: NVIDIA GTX280, 30*8 processors – CPU: Intel Core2 Quad Core Result: K-means • Baseline: Uvirginia – 35x faster than the four-threaded CPU-based couterpart Result: Apriori • Baselines – CPU-based Apriori – Best implementation of FIMI’03 Conclusion • Both MapReduce and GPU are feasible strategies for large-scale parallelized machine learning • MapReduce aims at parallelization over computer clusters • The hardware architecture of GPUs makes them a natural choice for parallelized ML