Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
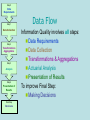
EFFECTIVE PREDICTIVE MODELINGDATA,ANALYTICS AND PRACTICE MANAGEMENT Richard A. Derrig Ph.D. OPAL Consulting LLC Karthik Balakrishnan Ph.D. ISO Innovative Analytics CANE Meeting Southbridge, MA September 26, 2008 Topics in Predictive Modeling • • • • • • • Introduction Explanatory vs. Predictive Modeling Data Quality Data augmentation Data adjustments Predictive Problems/software issues Analytic Methods of Interest Introduction • Research by IBM indicates only 1% of data collected by organizations is used for analysis • Predictive Modeling and Data Mining widely embraced by leading businesses – 2002 Strategic Decision Making survey by Hackett Best Practices determined that world class companies adopted predictive modeling technologies at twice the rate of other companies – Important commercial application is Customer retention: 5% increase in retention 95% increase in profit – It costs 5 to 10 times more to acquire new business • Another study of 24 leading companies found that they needed to go beyond simple data collection Models Explanatory vs Predictive • Explanatory Model The association of some target or decision variable with explanatory variables through mathematical formulations in which it is assumed that all variables are known with certainty. • Example: Underwriting Model, decision to accept or reject is target Models Explanatory vs Predictive • Predictive Model The association of some target or decision variable with predictor variables through mathematical formulations in which it is assumed that all predictor variables are known with possibly varying probabilities . • Example: Claim Investigation Model, decision to investigate is target Data Mining • Data Mining, also known as Knowledge-Discovery in Databases (KDD), is the process of automatically searching large volumes of data for patterns. In order to achieve this, data mining uses computational techniques from statistics, machine learning and pattern recognition. • www.wikipedia.org Successful Implementation of Predictive Modeling • Data availability and quality are essential • Insights from different areas are needed • Multidisciplinary effort – – – – – – Quantitative experts IT Business experts Managers Upper management buy in Not just for Actuarials DATA Manage the Human Side of Data and Analytics • Data Collection: Design and Reality • Understand and convey business benefits • Belief, model understanding, model complexity • ‘Tribal’ Knowledge as model attributes • Behavioral change and transparency • Disruption in ‘standard’ processes • Threat of obsolescence (automation) Don’t over rely on the technology; recognize the disruptive role you play DATA CRISP-DM • Cross Industry Standard Process for Data Mining • Standardized approach to data mining • www.crisp-dm.org Phases of CRISP-DM DATA Data Quality • Scope of problem • How it is addressed • New educational resources for actuaries Survey of Actuaries • Data quality issues have a significant impact on the work of actuaries – About a quarter of their time is spent on such issues – About a third of projects are adversely affected – See “Dirty Data on Both Sides of the Pond” – 2008 CAS Winter Forum – Data quality issues consume significantly more time on large predictive modelling Projects Statistical Data Editing • Process of Checking data for errors and correcting them • Uses subject matter experts • Uses statistical analysis of data • May include using methods to “fill in” missing values • Final result of SDE is clean data as well as summary of underlying causes of errors Step 0 Data Requirements Step 1 EDA: Overview Data Collection Step 2 Transformations Aggregations Step 3 Analysis Step 4 Presentation of Results Final Step Decisions • Typically first step in analyzing data • Purpose: – Explore structure of the data – Find outliers and errors • Uses simple statistics and graphical techniques • Examples include histograms, descriptive statistics and frequency tables Step 0 Data Requirements Step 1 Data Collection Step 2 Transformations Aggregations Step 3 Analysis Step 4 Presentation of Results Final Step Decisions EDA: Histograms Data Educational Materials Working Party Formation • The closest thing to data quality on the CAS syllabus are introductions to statistical plans • The CAS Data Management and Information Committee realized that SOX and Predictive Modeling have increased the need for quality data • So they formed the CAS Data Management Educational Materials working party to find and gather materials to educate actuaries CAS Data Management Educational Materials Working Party Publications • Book reviews of data management and data quality texts in the CAS Actuarial Review starting with the August 2006 edition • These reviews are combined and compared in “Survey of Data Management and Data Quality Texts,” CAS Forum, Winter 2007, www.casact.org • “Actuarial IQ (Information Quality)” published in the Winter 2008 edition of the CAS Forum: http://www.casact.org/pubs/forum/08wforum/ Step 0 Data Requirements Step 1 Data Collection Step 2 Transformations Aggregations Step 3 Analysis Step 4 Presentation of Results Final Step Decisions Data Flow Information Quality involves all steps: Data Requirements Data Collection Transformations & Aggregations Actuarial Analysis Presentation of Results To improve Final Step: Making Decisions Data Augmentation • Add information from Internal data • Add information from external data • For overview of inexpensive sources of data see: “Free and Cheap Sources of Data”, 2007 Predictive modeling seminar and “External Data Sources” at 2008 Ratemaking Seminar Data Augmentation – Internal Data • Create aggregated statistics from internal data sources – Number of lawyers per zip – Claim frequency rate per zip – Frequency of back claims per state • Use unstructured data – Text Mining Data Augmentation – External Data • • • • • Census data: Household type per zip Industry data: California DOI data, IRC Marketing data: Third party vendors IRC Data: Auto Injury data ISO data:?? Data Adjustments • Trend – Adjust all records to common cost level – Use model to estimate trend • Development – Adjust all losses to ultimate – Adjust all losses to a common age – Use model to estimate future development Analytic Model Development • Rule # 1: Use appropriate tool • Rule #2: There are no other rules Shameless Advertisement • Derrig, R.A. and Francis, L.A. 2008 Distinguishing the Forest from the Trees, Next VARIANCE and CAS Seattle Computers advance