Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Stream Data Introduction
or
“Stream Data in 30 minutes or less…”
Magdiel Galán
CSE591: DataMining
Dr. Huan Liu
Spring 2004
Outline
Streaming Data description
Main Concepts
Uses/Applications
Problems/Challenges
variance & k-means
aging & sliding windows
algorithms
References
Warning…
Disclaimer
Just Quick/Short tour on Data Stream
concepts
Although some algorithms, proof equations
are included on the presentation, they are for
reference and will be briefly discussed during
class presentation.
Sizing the challenge
WalMart Records 20 Million Transactions
Google Handles 100 Million Searches
AT&T produces 275 million call records
Earth sensing satellite produces GBs of
data
This just in a day!
Characteristics/Description
Stream data sets are…
Continuous
Massive
Unbounded
Possibly infinite
Fast changing and requires fast, realtime response
Example: Network Management
Application
Network Management involves monitoring and configuring
network hardware and software to ensure smooth
operation
Monitor link bandwidth usage, estimate traffic demands
Quickly detect faults, congestion and isolate root cause
Load balancing, improve utilization of network
resources
AT&T collects 100 GBs of NetFlow data each day!
from [GGR02]
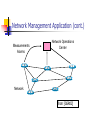
Network Management Application (cont.)
Measurements
Alarms
Network Operations
Center
Network
from [GGR02]
Uses/Applications
Banking/Stocks/Financials
credit card fraud detection
stock trends monitoring
Sensors
power grid balancing
engine controls
collision avoidance
driver sleep monitor
Problems/Challenges
‘Zillions of data
Continuous/Unbounded
Examples arrive faster than they can be mined
Application may require fast, real-time
response
Examples:
life threatening: collision avoidance
lost revenue/transactions: hung-up networks
Problems/Challenges
Time/Space constrained
Not enough memory
Can’t afford storing/revisiting the data
Single pass computation
External memory algorithms for handling data
sets larger than main memory cannot be
used.
Do not support continuous queries
Too slow real-time response
Problems/Challenges
In summary…
Can’t stop to smell the roses…
Only one chance/single pass/look at the data
Problems/Challenges
Other Considerations
Classical algorithms (i.e. CART, C4.5) do not scale up to
data stream [DH00]
Difficult to compute answers accurately with limited
memory
Most need entire data set for analysis
Random access (or multiple passes) to the data
With probability at least 1 - , algorithms compute an
approximate answer within a factor of the actual answer
Noise (bad sensors, outliers)
Aging/Old/Stale data
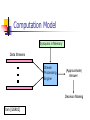
Computation Model
Synopsis in Memory
Data Streams
Stream
Processing
Engine
(Approximate)
Answer
Decision Making
from [GGR02]
Model Components
Synopsis
Summary of the data
Processing Engine
Implementation/Management System
Samples, Histograms
STREAM (Stanford): general-purpose
Aurora (Brown/MIT): sensor monitoring, dataflow
Telegraph (Berkeley): adaptive engine for sensors
Decision Making
Apply Data Mining techniques
Decision Trees, Clusters, Association Rules
Model Components
The remaining of the slides will focus
on Decision Making
and Synopsis Calculation
Synopsis: Dealing with
Time/Space Constraints
Since data can’t be contained, or revisited, the best
alternative is to summarize what has been seen.
Basic stream synopsis computation
Random Sampling: Generate statistics using a
representative sample of the data
Histograms: Distribution/Grouping data representation
Wavelets: Mathematical tool for hierarchical
decomposition of functions/signals
For this discusion, will focus on Histograms
Types of Histograms
Equi-Depth
V-Optimal
Element counts per bucket are kept constant
Minimize frequency variance within buckets
Exponential Histograms (EH)
Bucket sizes are non-decreasing powers of 2
Size: Total number of 1’s in the bucket.
For every bucket other than the last bucket, there are at least
k/2 and at most k/2+1 buckets of that size
Example: k=4: (1,1,2,2,2,4,4,4,8,8,..)
Essential component of “sliding windows” technique
addressing “aging” data.
Equi-Depth[GGR02]
V-Optimal[GGR02]
Exponential Histograms (EH)
Notice the total
count of elements
from [GGR02]
Sliding Windows Technique
Background:
Some applications rely on ALL historical data
But for most applications, OLD data is
considered less relevant and could skew results
from NEW trends or conditions
new processes/procedures
new hardware/sensors
new fashion trends
Sliding Windows (cont.)
Common approaches addressing Old data:
Aging Model [BDMO03]
elements are associated with “weights” that decrease
over time
may use some exponential decay formulas
Sliding Windows Model
Only last “N” elements are considered
Incorporate examples as they arrive
The record “expires” at time t+N (N is the window
length)
Count only the “1’s” in bit-stream data
Sliding Windows Description
Sliding Windows Approach (pseudo-pseudo code)
Consider only the last N elements.
Define k=1/ε, and approximate k/2 to nearest integer.
Time Stamp each “1” that arrives in the stream and
insert into a first bucket, shifting any initial ones.
If the number of buckets with same value exceeds k/2
+2, merge the oldest buckets, but keeping at least k/2
buckets of the same value
First bucket value is “1” since there is only one “1”
Merging creates a new bucket with size equal to the sum
Eliminate last bucket if its last 1 time stamp exceeds N
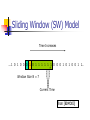
Sliding Window (SW) Model
Time Increases
….1 0 1 0 0 0 1 0 1 1 1 1 1 1 0 0 0 1 0 1 0 0 1 1…
Window Size N = 7
Current Time
from [BDMO03]
Example Run
Assume k/2 = 2
32,16,8,8,4,4,2,1,1
Example Run
Assume k/2 = 2
32,16,8,8,4,4,2,1,1
1
Data Stream segment could be “00010”
Example Run
Assume k/2 = 2
32,16,8,8,4,4,2,1,1,1
Merge!
32,16,8,8,4,4,2,2,1
Merged!
Example Run
Assume k/2 = 2
32,16,8,8,4,4,2,1,1
32,16,8,8,4,4,2,2,1
32,16,8,8,4,4,2,2,1,1
32,16,16,8,4,2,1
* Example from [DGIM02]/[GGR02]
Example Run
Assume k/2 = 2
32,16,8,8,4,4,2,1,1
32,16,8,8,4,4,2,2,1
32,16,8,8,4,4,2,2,1,1
32,16,16,8,4,2,1
Keep in mind, the values represent TOTAL 1’s
Statistics Over Sliding Windows
Bitstream: Count the number of ones [DGIM02]
Exact solution: Θ(N) bits
Algorithm BasicCounting:
1 + ε approximation (relative error!)
Space: O(1/ε (log2N)) bits
Time: O(log N) worst case, O(1) amortized per record
Lower Bound:
Space: Ω(1/ε (log2N)) bits
Complexity
Number of buckets m:
m [# of buckets of size j]*[# of different
bucket sizes]
(k/2 +1) * ((log(2N/k)+1) = O(k* log(N))
Each bucket requires O(log N) bits.
Total memory:
O(k log2 N) = O(1/ε * log2 N) bits
from [BDMO03]
Benefits of Sliding Windows
Incorporates new elements as they appear.
Easy to calculate statistics over data
streams with respect to the last N elements
based on the histogram.
Can estimate the number of 1’s within a
factor of (1 + ε) using only θ((1/ε)(log2 N))
bits of memory.
from [BDMO03]
Expansion of Sliding Windows
The original Sliding Window Method was not fully
applicable to two important statistics during the
“merging” of the buckets:
k-median and variance
A solution was devised by Babcock, Datar,
Motwani and O’Callaghan [BDMO02]
Their work derived a methodology for Variance,
that was also applied for k-medians.
Variance and k-Medians
Variance: Σ(xi – μ)2, μ = Σ xi/N
k-median clustering:
Given: N points (x1… xN) in a metric space
Find k points C = {c1, c2, …, ck} that minimize
Σ d(xi, C) (the assignment distance)
Clustering to be covered in detail future
presentation
from [BDMO03]
Notation
Current window, size = N
Bm
Bm-1
………………
B2
Vi = Variance of the ith bucket
ni = number of elements in ith bucket
μi = mean of the ith bucket
from [BDMO03]
B1
Variance – composition
Bi,j = concatenation of buckets i and j
n i, j n i n j
μ i, j =
n i μ i + n jμ j
ni + n j
Vi, j = Vi + Vj +
from [BDMO03]
nin j
ni + n j
(μ i - μ j )
2
Decision Making
The problem of addressing time changing data had
also significant influence on decision algorithms.
Pedro Domingos, who had originally developed a
successful decision table algorithm (VFDT), also
conceptualized the need to work with recent data,
resulting in a new algorithm known as CVFDT.
VFDT - Very Fast Decision Tree
CVFDT - Concept Drift Very Fast Decision Tree
Implemented a window approach
Decision Making
Both VFDT and CVFDT make use of a statistical
result known as Hoeffding* bound
Used to estimate the minimum number of necessary
examples needed to make a decision for a node in a
decision tree.
This is the key concept for these algorithms to work.
* W.Hoefding, Probability Inequalities sums bounded Variables,
Journal American Statistics Association, 1963
Hoeffding Bound
random variable a whose range is R
n independent observations of a; Mean: ā
Hoeffding bound states:
With probability 1- , the true mean of a is at
least ā - ,
2
where
R ln( 1 / )
from [DH00]/[HSD01]
2n
Hoeffding Bound
Significance…
This estimate/bound is incorporated into an
ID3 type decision tree, hence VFDT/CVFDT
The information gain is evaluated against
R 2 ln( 1 / )
2n
VFDT Algorithm
R 2 ln( 1 / )
2n
from [DH00]
VFDT Algorithm Results
from [DH00]
CVFDT vs. VFDT
CVFDT is an extension to VFDT that
incorporated “windowing”
CFVDT concept:
Generate tree as regular but using a window of “w”
elements.
Monitor changes in gain for attributes.
If changes, generate alternate subtree with new
“best” attribute, but keep on background.
Replace if new subtree becomes more accurate.
The END – “El Final”
Concepts Covered:
Data Streams Constraints (time/space)
Data Streams Model
Histograms
Synopsis
Decision Maker
Exponential Histogram
Sliding Windows
Variance
Hoeffding Bounds
Decision Tree Classifier
References
[BDMO03] B. Babcock, M. Datar, R. Motwani, and J. L. O’Callaghan. “Maintaining Variance
and k-Medians over Data Stream Windows”. ACM PODS, 2003.
http://citeseer.nj.nec.com/591910.html
http://www.stanford.edu/~babcock/papers/pods03.ppt
[DH00] P. Domingos and G. Hulten. “Mining High-Speed Data Streams”. ACM KDD, 2000.
http://citeseer.nj.nec.com/domingos00mining.html
[HSD01] G. Hulten, L. Spencer and P. Domingos. “Mining Time-Changing Data Streams”.
ACM KDD, 2001.
http://citeseer.nj.nec.com/hulten01mining.html
[DGIM02] Mayur Datar, Aristides Gionis, Piotr Indyk and Rajeev Motwani. “Maintaining
Stream Statistics over Sliding Windows” ACM-SIAM SODA 2002.
http://www.stanford.edu/~babcock/papers/pods03.ppt
[GGR02] Minos Garofalakis, Johannes Gehrke and Rajeev Rastogi. “Querying and Mining
Data Streams: You Only Get One Look”. SIGMOD 2002 (tutorial).
http://www.bell-labs.com/user/minos/Talks/streams-tutorial02.ppt