Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
eCommerce Technology
20-751
Data Mining
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Coping with Information
• Computerization of daily life produces data
– Point-of-sale, Internet shopping (& browsing), credit cards,
banks . . .
– Info on credit cards, purchase patterns, product preferences,
payment history, sites visited . . .
• Travel. One trip by one person generates info on
destination, airline preferences, seat selection, hotel,
rental car, name, address, restaurant choices . . .
• Data cannot be processed or even inspected
manually
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Data Overload
• Only a small portion of data collected is analyzed
(estimate: 5%)
• Vast quantities of data are collected and stored out of
fear that important info will be missed
• Data volume grows so fast that old data is never
analyzed
• Database systems do not support queries like
– “Who is likely to buy product X”
– “List all reports of problems similar to this one”
– “Flag all fraudulent transactions”
• But these may be the most important questions!
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Data Mining
“The key in business is to know something that
nobody else knows.”
— Aristotle Onassis
“To understand is to perceive patterns.”
PHOTO: LUCINDA DOUGLAS-MENZIES
PHOTO: HULTON-DEUTSCH COLL
— Sir Isaiah Berlin
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Data Mining
• Extracting previously unknown relationships from
large datasets
– summarize large data sets
– discover trends, relationships, dependencies
– make predictions
• Differs from traditional statistics
– Huge, multidimensional datasets
– High proportion of missing/erroneous data
– Sampling unimportant; work with whole population
• Sometimes called
– KDD (Knowledge Discovery in Databases)
– OLAP (Online Analytical Processing)
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
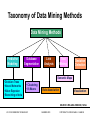
Taxonomy of Data Mining Methods
Data Mining Methods
Predictive
Modeling
• Decision Trees
• Neural Networks
• Naive Bayesian
• Branching criteria
Database
Segmentation
Link
Analysis
Text
Mining
Deviation
Detection
Semantic Maps
• Clustering
• K-Means
Rule Associa tion
Visualization
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Predictive Modeling
• Objective: use data about the past to predict future
behavior
• Sample problems:
– Will this (new) customer pay his bill on time? (classification)
– What will the Dow-Jones Industrial Average be on October
15? (prediction)
• Technique: supervised learning
– decision trees
– neural networks
– naive Bayesian
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Predictive Modeling
Honest
Tridas
Vickie
Mike
Wally
Waldo
Barney
Crooked
Which characteristics distinguish the two groups?
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Learned Rules in Predictive Modeling
Tridas
Vickie
Mike
Honest = has round eyes and a smile
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Rule Induction Example
Data:
height
short
tall
tall
short
tall
tall
tall
short
hair
blond
blond
red
dark
dark
blond
dark
blond
eyes
blue
brown
blue
blue
blue
blue
brown
brown
class
A
B
A
B
B
A
B
B
Devise a predictive rule to classify a new person as A or B
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Build a Decision Tree
hair
dark
blond
red
short, blue = B
tall, blue = B
tall, brown= B
{tall, blue = A}
short, blue = A
tall, brown = B
tall, blue = A
short, brown = B
Does not completely classify
blonde-haired people.
More work is required
Completely classifies dark-haired
and red-haired people
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
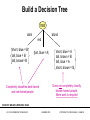
Build a Decision Tree
hair
dark
blond
red
short, blue = B
tall, blue = B
tall, brown= B
{tall, blue = A}
Decision tree is complete because
1. All 8 cases appear at nodes
2. At each node, all cases are in
the same class (A or B)
short, blue = A
tall, brown = B
tall, blue = A
short, brown = B
eye
blue
short = A
tall = A
brown
tall = B
short = B
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Learned Predictive Rules
hair
dark
blond
red
B
A
eyes
blue
A
brown
B
SOURCE: WELGE & REINCKE, NCSA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Decision Trees
• Good news: a decision tree can always be built from training
data
• Any variable can be used at any level of the tree
• Bad news: every data point may wind up at a leaf (tree has not
compressed the data)
height
tall
short
eyes
blue
brown
B
hair
blonde
A
brown
B
dark
eyes
hair
blonde
B
B
blue
dark
red
A
B
8 cases, 7 nodes. This tree has not summarized the data effectively
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Database Segmentation (Clustering)
• “The art of finding groups in data” Kaufman &
Rousseeuw
• Objective: gather items from a database into sets
according to (unknown) common characteristics
• Much more difficult than classification since the
classes are not known in advance (no training)
• Examples:
– Demographic patterns
– Topic detection (words about the topic often occur together)
• Technique: unsupervised learning
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Clustering Example
• Are there natural clusters in the data (36,10), (12,8),
(38,42), (13,6), (36,38), (16,9), (40,36), (35,19),
(37,7), (39,8)?
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Clustering
• K-means algorithm
• To divide a set into K clusters
• Pick K points at random. Use them to divide the set
into K clusters based on nearest distance
• Loop:
– Find the mean of each cluster. Move the point there.
– Redefine the clusters.
– If no point changes cluster, done
• K-means demo
• Agglomerative clustering: start with N clusters & merge
• Agglomerative clustering demo
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Neural Networks
Networks of processing units called neurons. This is the j th neuron:
Neuron computes a linear
function of the inputs
n INPUTS
x1, …, xn
1 OUTPUT yj
depends only on
the linear function
Neurons are
easy to simulate
n WEIGHTS
w1j , …, wnj
SOURCE: CONSTRUCTING INTELLIGENT AGENTS WITH JAVA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
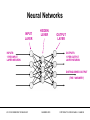
Neural Networks
INPUT
LAYER
HIDDEN
LAYER
INPUTS:
1 PER INPUT
LAYER NEURON
OUTPUT
LAYER
OUTPUTS:
1 PER OUTPUT
LAYER NEURON
DISTINGUISHED OUTPUT
(THE “ANSWER”)
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Neural Networks
Learning through back-propagation
1. Network is trained by giving it many inputs whose output is known
2. Deviation is “fed back” to the neurons to adjust their weights
3. Network is then ready for live data
DEVIATION
SOURCE: CONSTRUCTING INTELLIGENT AGENTS WITH JAVA
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
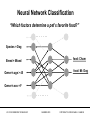
Neural Network Classification
“Which factors determine a pet’s favorite food?”
Species = Dog
food: Chum
Breed = Mixed
food: Mr. Dog
Owner’s age > 45
Owner’s sex = F
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Neural Network Demos
• Demo: Notre Dame football, Automated surveillance,
Handwriting analyzer
• Financial applications:
– Churning: are trades being instituted just to generate
commissions?
– Fraud detection in credit card transactions
– Kiting: isolate float on uncollected funds
– Money Laundering: detect suspicious money transactions
(US Treasury's Financial Crimes Enforcement Network)
• Insurance applications:
– Auto Insurance: detect a group of people who stage
accidents to collect on insurance
– Medical Insurance: detect professional patients and ring of
doctors and ring of references
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Rule Association
• Try to find rules of the form
IF <left-hand-side> THEN <right-hand-side>
• (This is the reverse of a rule-based agent, where the rules are
given and the agent must act. Here the actions are given and
we have to discover the rules!)
• Prevalence = probability that LHS and RHS occur
together (sometimes called “support factor,” “leverage” or “lift”)
• Predictability = probability of RHS given LHS
(sometimes called “confidence” or “strength”)
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Association Rules from
Market Basket Analysis
• <Dairy-Milk-Refrigerated> <Soft Drinks Carbonated>
– prevalence = 4.99%, predictability = 22.89%
• <Dry Dinners - Pasta> <Soup-Canned>
– prevalence = 0.94%, predictability = 28.14%
• <Paper Towels - Jumbo> <Toilet Tissue>
– prevalence = 2.11%, predictability = 38.22%
• <Dry Dinners - Pasta> <Cereal - Ready to Eat>
– prevalence = 1.36%, predictability = 41.02%
• <American Cheese Slices > <Cereal - Ready to Eat>
– prevalence = 1.16%, predictability = 38.01%
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Use of Rule Associations
• Coupons, discounts
– Don’t give discounts on 2 items that are frequently bought
together. Use the discount on 1 to “pull” the other
• Product placement
– Offer correlated products to the customer at the same time.
Increases sales
• Timing of cross-marketing
– Send camcorder offer to VCR purchasers 2-3 months after
VCR purchase
• Discovery of patterns
– People who bought X, Y and Z (but not any pair) bought W
over half the time
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Finding Rule Associations
• Example: grocery shopping
• For each item, count # of occurrences (say out of 100,000)
apples 1891, caviar 3, ice cream 1088, pet food 2451, …
• Drop the ones that are below a minimum support level
apples 1891, ice cream 1088, pet food 2451, …
• Make a table of each item against each other item:
apples ice cream pet food
apples
1891
685
24
ice cream
-----
1088
322
pet food
-----
-----
2451
• Discard cells below support threshold. Now make a cube for
triples, etc. Add 1 dimension for each product on LHS.
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Rule Association Demos
• Magnum Opus (RuleQuest, free download)
• See5/C5.0 (RuleQuest, free download)
• Cubist numerical rule finder (RuleQuest, free
download)
• IBM Interactive Miner
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Text Mining
• Objective: discover relationships among people &
things from their appearance in text
• Topic detection, term detection
– When has a new term been seen that is worth recording?
• Generation of “knowledge map”, a graph
representing terms/topics and their relationships
• SemioMap demo (Semio Corp.)
–
–
–
–
Phrase extraction
Concept clustering (through co-occurrence) not by document
Graphic navigation (link means concepts co-occur)
Processing time: 90 minutes per gigabyte
• Summary server (inxight.com)
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Catalog Mining
SOURCE: TUPAI SYSTEMS
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Visualization
• Objective: produce a graphic view of data so it
become understandable to humans
• Hyperbolic trees
• SpotFire (free download from www.spotfire.com)
• SeeItIn3D
• TableLens
• OpenViz
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Major Ideas
•
•
•
•
There’s too much data
We don’t understand what it means
It can be handled without human intervention
Relationships can be discovered automatically
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS
Q&A
20-751 ECOMMERCE TECHNOLOGY
SUMMER 2000
COPYRIGHT © 2000 MICHAEL I. SHAMOS