Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Classification
Classification vs. Prediction
Classification:
Prediction or Regression:
predicts categorical class labels
classifies data (constructs a model) based on the
training set and the values (class labels) in a
classifying attribute and uses it in classifying new data
models continuous-valued functions, i.e., predicts
unknown or missing values
Typical Applications
credit approval, target marketing, medical diagnosis
treatment effectiveness analysis
Classification—A Two-Step Process
Model construction: describing a set of predetermined
classes
Each tuple/sample is assumed to belong to a predefined class, as
determined by the class label attribute
The set of tuples used for model construction: training set
The model is represented as classification rules, decision trees, or
mathematical formulae
Model usage: for classifying future or unknown objects
Estimate accuracy of the model
Accuracy rate is the percentage of test set samples that are
correctly classified by the model
Test set is independent of training set, otherwise over-fitting will
occur
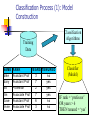
Classification Process (1): Model
Construction
Training
Data
NAME
M ike
M ary
B ill
Jim
D ave
A nne
RANK
YEARS TENURED
A ssistant P rof
3
no
A ssistant P rof
7
yes
P rofessor
2
yes
A ssociate P rof
7
yes
A ssistant P rof
6
no
A ssociate P rof
3
no
Classification
Algorithms
Classifier
(Model)
IF rank = ‘professor’
OR years > 6
THEN tenured = ‘yes’
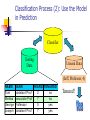
Classification Process (2): Use the Model
in Prediction
Classifier
Testing
Data
Unseen Data
(Jeff, Professor, 4)
NAME
T om
M erlisa
G eorge
Joseph
RANK
YEARS TENURED
A ssistant P rof
2
no
A ssociate P rof
7
no
P rofessor
5
yes
A ssistant P rof
7
yes
Tenured?
Supervised vs. Unsupervised Learning
Supervised learning (classification)
Supervision: The training data (observations,
measurements, etc.) are accompanied by labels
indicating the class of the observations
New data is classified based on the training set
Unsupervised learning (clustering)
The class labels of training data is unknown
Given a set of measurements, observations, etc. with
the aim of establishing the existence of classes or
clusters in the data
Important Issues
Data cleaning
Relevance analysis (feature selection)
Remove the irrelevant or redundant attributes
Data transformation
Generalize and/or normalize data
Accuracy
Scalability
Robustness
Decision tree classifiers
Widely used learning method
Easy to interpret: can be re-represented
as if-then-else rules
Approximates function by piece wise
constant regions
Does not require any prior knowledge of
data distribution, works well on noisy
data.
Setting
Given old data about customers and payments,
predict new applicant’s loan eligibility.
Previous customers
Age
Salary
Profession
Location
Customer type
Classifier
Decision rules
Salary > 5 L
Prof. = Exec
New applicant’s data
Good/
bad
Decision trees
Tree where internal nodes are simple decision
rules on one or more attributes and leaf nodes
are predicted class labels.
Salary < 1 M
Prof = teaching
Good
Bad
Age < 30
Bad
Good
Training Dataset
This
follows
an
example
from
Quinlan’s
ID3
age
<=30
<=30
30…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income student credit_rating
high
no fair
high
no excellent
high
no fair
medium
no fair
low
yes fair
low
yes excellent
low
yes excellent
medium
no fair
low
yes fair
medium
yes fair
medium
yes excellent
medium
no excellent
high
yes fair
medium
no excellent
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
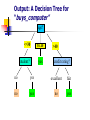
Output: A Decision Tree for
“buys_computer”
age?
<=30
student?
overcast
30..40
yes
>40
credit rating?
no
yes
excellent
fair
no
yes
no
yes
Tree learning algorithms
ID3 (Quinlan 1986)
Successor C4.5 (Quinlan 1993)
SLIQ (Mehta et al)
SPRINT (Shafer et al)
Basic algorithm for tree building
Greedy top-down construction.
Gen_Tree (Node, data)
Stopping
criteria
make node a leaf?
Yes
Stop
Selection
Find best attribute and best split on attribute
criteria
Partition data on split condition
For each child j of node Gen_Tree (node_j, data_j)
Split criteria
Select the attribute that is best for classification.
Intuitively pick one that best separates instances of
different classes.
Quantifying the intuitive: measuring separability:
First define impurity of an arbitrary set S consisting of
K classes
Information entropy:
k
Entropy( S ) pi log pi
i 1
Zero when consisting of only one class, one when all
classes in equal number.
Information gain
k
Other measures of impurity: Gini:
Gini
0
i 1
0.5
Entropy
1
Gini ( S ) 1 pi
p1
0
1
1
Information gain on partitioning S into r subsets
Impurity (S) - sum of weighted impurity of each
subset
r
Gain( S , S1..S r ) Entropy( S )
j 1
Sj
S
Entropy( S j )
2
Information Gain (ID3/C4.5)
Select the attribute with the highest information gain
Assume there are two classes, P and N
Let the set of examples S contain p elements of class P
and n elements of class N
The amount of information, needed to decide if an
arbitrary example in S belongs to P or N is defined as
p
p
n
n
I ( p, n)
log 2
log 2
pn
pn pn
pn
Information Gain in Decision Tree
Induction
Assume that using attribute A a set S will be partitioned
into sets {S1, S2 , …, Sv}
If Si contains pi examples of P and ni examples of N,
the entropy, or the expected information needed to
classify objects in all subtrees Si is
pi ni
E ( A)
I ( pi , ni )
i 1 p n
The encoding information that would be gained by
branching on A
Gain( A) I ( p, n) E ( A)
Attribute Selection by Information
Gain Computation
Class P: buys_computer =
“yes”
Class N: buys_computer =
“no”
I(p, n) = I(9, 5) =0.940
Compute the entropy for
age:
age
<=30
30…40
>40
pi
2
4
3
ni I(pi, ni)
3 0.971
0 0
2 0.971
5
4
I ( 2,3)
I ( 4,0)
14
14
5
I (3,2) 0.69
14
E ( age)
Hence
Gain(age) I ( p, n) E (age)
Similarly
Gain(income) 0.029
Gain( student ) 0.151
Gain(credit _ rating ) 0.048
Gini Index (IBM IntelligentMiner)
If a data set T contains examples from n classes, gini index,
n
gini(T) is defined as
gini(T ) 1 p 2
j 1
where pj is the relative frequency of class j in T.
If a data set T is split into two subsets T1 and T2 with sizes
N1 and N2 respectively, the gini index of the split data
contains examples from n classes, the gini index gini(T) is
defined as
gini split (T )
j
N 1 gini( ) N 2 gini( )
T1
T2
N
N
The attribute provides the smallest ginisplit(T) is chosen to
split the node (need to enumerate all possible splitting
points for each attribute).
Extracting Classification Rules from Trees
Represent the knowledge in the form of IF-THEN rules
One rule is created for each path from the root to a leaf
The leaf node holds the class prediction
Example
age = “<=30” AND student = “no” THEN buys_computer = “no”
age = “<=30” AND student = “yes” THEN buys_computer = “yes”
age = “31…40”
THEN buys_computer = “yes”
age = “>40” AND credit_rating = “excellent” THEN
buys_computer = “yes”
IF age = “>40” AND credit_rating = “fair” THEN buys_computer =
“no”
IF
IF
IF
IF
Avoid Overfitting in Classification
The generated tree may overfit the training data
Too many branches, some may reflect anomalies
due to noise or outliers
Result is in poor accuracy for unseen samples
Two approaches to avoid overfitting
Prepruning: Halt tree construction early—do not split
a node if this would result in the goodness measure
falling below a threshold
Postpruning: Remove branches from a “fully grown”
tree—get a sequence of progressively pruned trees
Use a set of data different from the training data
to decide which is the “best pruned tree”
Classification in Large Databases
Scalability: Classifying data sets with millions of examples
and hundreds of attributes with reasonable speed
Why decision tree induction in data mining?
relatively faster learning speed (than other classification
methods)
convertible to simple and easy to understand
classification rules
can use SQL queries for accessing databases
comparable classification accuracy with other methods