Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Privacy preserving data mining –
randomized response and
association rule hiding
Li Xiong
CS573 Data Privacy and Anonymity
Partial slides credit: W. Du, Syracuse University, Y. Gao, Peking University
Privacy Preserving Data Mining
Techniques
Protecting sensitive raw data
Randomization (additive noise)
Geometric perturbation and projection (multiplicative
noise)
Randomized response technique
Categorical data perturbation in data collection model
Protecting sensitive knowledge (knowledge
hiding)
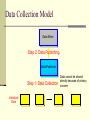
Data Collection Model
Data Miner
Step 2: Data Publishing
Data Publisher
Step 1: Data Collection
Individual
Data
Data cannot be shared
directly because of privacy
concern
Background:
Randomized Response
The true
answer
is “Yes”
Biased coin:
P( Head )
0.5
Do you smoke?
P(Yes )
( 0.5)
Head
Tail
Yes
No
P'(Yes) P(Yes) P(No) (1 )
P'(No) P(Yes) (1 ) P(No)
Decision Tree Mining using
Randomized Response
Multiple attributes encoded in bits
Biased coin:
P( Head )
0.5
P(Yes )
( 0.5)
Head True answer E: 110
Tail
False answer !E: 001
Column distribution can be estimated for
learning a decision tree!
Using Randomized Response Techniques for Privacy-Preserving Data Mining, Du, 2003
Accuracy of Decision tree built on
randomized response
Generalization for Multi-Valued
Categorical Data
q1
q2
q3
q4
True Value: Si
Si
Si+1
Si+2
Si+3
P'(s1) q1 q4 q3 q2 P(s1)
P'(s2) q2 q1 q4 q3P(s2)
P'(s3) q3 q2 q1 q4 P(s3)
P'(s4)
q4
q3
q2
q1
P(s4)
M
A Generalization
RR Matrices [Warner 65], [R.Agrawal 05], [S. Agrawal 05]
RR Matrix can be arbitrary
a11 a12 a13 a14
a21 a22 a23 a24
M
a31 a32 a33 a34
a41 a42 a43 a44
Can we find optimal RR matrices?
OptRR:Optimizing Randomized Response Schemes for Privacy-Preserving Data Mining,
Huang, 2008
What is an optimal matrix?
Which of the following is better?
1 0 0
M1 0 1 0
0 0 1
13
1
M 2 3
1
3
1
3
1
3
1
3
1
3
1
3
1
3
Privacy: M2 is better
Utility: M1 is better
So, what is an optimal matrix?
Optimal RR Matrix
An RR matrix M is optimal if no other RR
matrix’s privacy and utility are both better
than M (i, e, no other matrix dominates M).
Privacy Quantification
Utility Quantification
A number of privacy and utility metrics have
been proposed.
Privacy: how accurately one can estimate
individual info.
Utility: how accurately we can estimate aggregate
info.
Metrics
Privacy: accuracy of estimate of individual values
Utility: difference between the original probability and the
estimated probability
Optimization Methods
Approach 1: Weighted sum:
w1 Privacy + w2 Utility
Approach 2
Fix Privacy, find M with the optimal Utility.
Fix Utility, find M with the optimal Privacy.
Challenge: Difficult to generate M with a fixed
privacy or utility.
Proposed Approach: Multi-Objective
Optimization
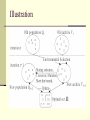
Optimization algorithm
Evolutionary Multi-Objective Optimization (EMOO)
The algorithm
Start with a set of initial RR matrices
Repeat the following steps in each iteration
Mating: selecting two RR matrices in the pool
Crossover: exchanging several columns between the
two RR matrices
Mutation: change some values in a RR matrix
Meet the privacy bound: filtering the resultant matrices
Evaluate the fitness value for the new RR matrices.
Note : the fitness values is defined in terms of privacy and utility
metrics
Illustration
Output of Optimization
The optimal set is often plotted in the objective space as
Pareto front.
Worse
M6
M8
Utility
M1 M2
M5
M4
M7
M3
Better
Privacy
For First attribute of Adult data
Privacy Preserving Data Mining
Techniques
Protecting sensitive raw data
Randomization (additive noise)
Geometric perturbation and projection (multiplicative
noise)
Randomized response technique
Protecting sensitive knowledge (knowledge
hiding)
Frequent itemset and association rule hiding
Downgrading classifier effectiveness
Frequent Itemset Mining and
Association Rule Mining
Frequent itemset mining: frequent set of items in a transaction data set
Association rules: associations between items
Frequent Itemset Mining and
Association Rule Mining
First proposed by Agrawal, Imielinski, and Swami in SIGMOD 1993
SIGMOD Test of Time Award 2003
“This paper started a field of research. In addition to containing an innovative
algorithm, its subject matter brought data mining to the attention of the database
community … even led several years ago to an IBM commercial, featuring supermodels,
that touted the importance of work such as that contained in this paper. ”
Apriori algorithm in VLDB 1994
#4 in the top 10 data mining algorithms in ICDM 2006
R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between sets of items in
large databases. In SIGMOD ’93.
Apriori: Rakesh Agrawal and Ramakrishnan Srikant. Fast Algorithms for Mining
Association Rules. In VLDB '94.
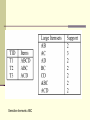
Basic Concepts: Frequent Patterns and
Association Rules
Transaction-id
Items bought
Itemset: X = {x1, …, xk} (k-itemset)
10
A, B, D
Frequent itemset: X with minimum
20
A, C, D
30
A, D, E
40
B, E, F
50
B, C, D, E, F
Customer
buys both
Customer
buys diaper
support count
Support count (absolute support): count
of transactions containing X
Association rule: A B with minimum
support and confidence
Support: probability that a transaction
contains A B
s = P(A B)
Confidence: conditional probability that
a transaction having A also contains B
c = P(A | B)
Customer
buys beer
Association rule mining process
Find all frequent patterns (more costly)
Generate strong association rules
May 22, 2017
20
Illustration of Frequent Itemsets and
Association Rules
Transaction-id
Items bought
10
A, B, D
20
A, C, D
30
A, D, E
40
B, E, F
50
B, C, D, E, F
Frequent itemsets (minimum support count = 3) ?
{A:3, B:3, D:4, E:3, AD:3}
Association rules (minimum support = 50%, minimum confidence = 50%) ?
A D (60%, 100%)
D A (60%, 75%)
May 22, 2017
Association Rule Hiding: what? why??
Problem: hide sensitive association rules in
data without losing non-sensitive rules
Motivations: confidential rules may have
serious adverse effects
SIGMOD Ph.D. Workshop
IDAR’07
22
Problem statement
Given
a database D to be released
minimum threshold “MST”, “MCT”
a set of association rules R mined from D
a set of sensitive rules Rh R to be hided
Find a new database D’ such that
the rules in Rh cannot be mined from D’
the rules in R-Rh can still be mined as many as
possible
SIGMOD Ph.D. Workshop
IDAR’07
Solutions
Data modification approaches
Basic idea: data sanitization D->D’
Approaches: distortion,blocking
Drawbacks
Cannot control hiding effects intuitively, lots of I/O
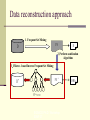
Data reconstruction approaches
Basic idea: knowledge sanitization D->K->D’
Potential advantages
Can easily control the availability of rules and control the
hiding effects directly, intuitively, handily
SIGMOD Ph.D. Workshop
IDAR’07
Distortion-based Techniques
Sample Database
Distorted Database
A
B
C
D
1
1
1
0
1
0
0
1
1
0
0
0
1
1
0
1
1
1
0
1
1
1
0
0
1
A
B
C
D
1
1
1
0
1
0
1
1
0
0
0
1
1
1
0
Distortion
Algorithm
Rule A→C has:
Support(A→C)=80%
Confidence(A→C)=100%
Rule A→C has now:
Support(A→C)=40%
Confidence(A→C)=50%
Side Effects
Before Hiding
Process
After Hiding
Process
Side Effect
Rule Ri has had
conf(Ri)>MCT
Rule Ri has now
conf(Ri)<MCT
Rule Eliminated
(Undesirable Side
Effect)
Rule Ri has had
conf(Ri)<MCT
Rule Ri has now
conf(Ri)>MCT
Ghost Rule
(Undesirable Side
Effect)
Large Itemset I has
had sup(I)>MST
Itemset I has now
sup(I)<MST
Itemset Eliminated
(Undesirable Side
Effect)
Distortion-based Techniques
Challenges/Goals:
To minimize the undesirable Side Effects that the hiding
process causes to non-sensitive rules.
To minimize the number of 1’s that must be deleted in the
database.
Algorithms must be linear in time as the database
increases in size.
Sensitive itemsets: ABC
Data distortion [Atallah 99]
Hardness result:
The distortion problem is NP Hard
Heuristic search
Find items to remove and transactions to
remove the items from
Disclosure Limitation of Sensitive Rules, M. Atallah, A. Elmagarmid, M.
Ibrahim, E. Bertino, V. Verykios, 1999
Heuristic Approach
A greedy bottom-up search through the
ancestors (subsets) of the sensitive itemset
for the parent with maximum support (why?)
At the end of the search, 1-itemset is selected
Search through the common transactions
containing the item and the sensitive itemset
for the transaction that affects minimum
number of 2-itemsets
Delete the selected item from the identified
transaction
Results comparison
Blocking-based Techniques
Initial Database
A
B
C
D
1
1
1
0
1
0
1
1
0
0
0
1
1
1
0
New Database
A
B
C
D
1
1
1
0
1
0
?
1
1
?
0
0
1
1
0
1
1
1
0
1
1
1
0
1
1
Blocking
Algorithm
Support and Confidence becomes marginal.
In New Database: 60% ≤ conf(A → C) ≤ 100%
Data reconstruction approach
1.Frequent Set Mining
DD
FS
R
2.Perform sanitization
Algorithm
3.FP-tree - based Inverse Frequent Set Mining
FS ’
D’
FP-tree
SIGMOD Ph.D. Workshop
IDAR’07
R-Rh
The first two phases
1. Frequent set mining
Generate all frequent itemsets with their supports and
support counts FS from original database D
2. Perform sanitization algorithm
Input: FS output in phase 1, R, Rh
Output: sanitized frequent itemsets FS’
Process
Select hiding strategy
Identify sensitive frequent sets
Perform sanitization
In best cases, sanitization algorithm can ensure
from FS’ ,we can exactly get the non-sensitive
rules set R-Rh SIGMOD Ph.D. Workshop
2007-7-10
IDAR’07
FS
R
FS’
R-Rh
36
Example: the first two phases
Oiginal Database: D
TID
T1
T2
T3
T4
T5
T6
Items
ABCE
ABC
ABCD
ABD
AD
ACD
Frequent Itemsets: FS
A:6 100%
1. Frequent
B:4
66%
set mining
C:4
66%
σ= 4
D:4
66%
MST=66%
MCT=75%
AB:4 66%
AC:4 66%
AD:4 66%
Association Rules: R
confidence support
B A 100%
66%
C A 100%
66%
D A 100%
66%
rules
2. Perform
sanitization
algorithm
A:6 100%
C:4
66%
rules confidence support
D:4
66%
C A 100%
66%
AC:4 66%
D A 100%
66%
AD:4 66%
Association Rules: R-R h
Frequent Itemsets: FS'
SIGMOD Ph.D. Workshop
IDAR’07
2007-7-10 37
Open research questions
Optimal solution
Itemsets sanitization
The support and confidence of the rules in R- Rh should remain
unchanged as much as possible
Integrating data protection and knowledge (rule) protection
Coming up
Cryptographic protocols for privacy
preserving distributed data mining
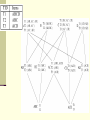
Classification of current algorithms
Data
modification
Hide
rules
Hide large
itemsets
DataDistortion
Algo1a
Algo1b
Algo2a
WSDA
PDA
Algo2b Algo2c
Naïve MinFIA
MaxFIA IGA RRA
RA SWA
Border-Based
Integer-Programing
Sanitization-Matrix
DataBlocking
CR
CR2
GIH
Data reconstruction
CIILM
Weight-based Sorting Distortion Algorithm
(WSDA) [Pontikakis 03]
High Level Description:
Input:
Initial Database
Set of Sensitive Rules
Safety Margin (for example 10%)
Output:
Sanitized Database
Sensitive Rules no longer hold in the Database
WSDA Algorithm
High Level Description:
1st step:
Retrieve the set of transactions which support
sensitive rule RS
For each sensitive rule RS find the number N1 of
transaction in which, one item that supports the
rule will be deleted
WSDA Algorithm
High Level Description:
2nd step:
For each rule Ri in the Database with common
items with RS compute a weight w that denotes
how strong is Ri
For each transaction that supports RS compute a
priority Pi, that denotes how many strong rules
this transaction supports
WSDA Algorithm
High Level Description:
3rd step:
Sort the N1 transactions in ascending order
according to their priority value Pi
4th step:
For the first N1 transactions hide an item that is
contained in RS
WSDA Algorithm
High Level Description:
5th step:
Update confidence and support values for other
rules in the database
Proposed Solution
Discussion
Sanitization algorithm
Compared with early popular data sanitization :
performs sanitization directly on knowledge level of
data
Inverse frequent set mining algorithm
Deals with frequent items and infrequent items
separately: more efficiently, a large number of
outputs
Our solution provides user with a knowledge level window
to perform sanitization handily and generates a number of
secure databases
SIGMOD Ph.D. Workshop
IDAR’07
2007-7-10 46