Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
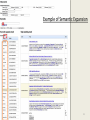
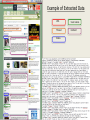
Internet Memory Research From Web Archiving services to Web scale data processing platform GA IIPC, Paris, May 19th 2014 Overview Internet Memory Research • Company • Vision • Technologies Services • Archive the Net • Mignify • Newstretto Use-Cases • Improve your Selection Process • Search in your Web archive • Extract valuable information Internet Memory Research 2 Internet Memory Research Spin-off of the Internet Memory Foundation French start-up, founded in 2011 20+ engineers Actively engaged in the Web Information Mining field: • EU Projects: DOPA, Annomarket, TrendMiner, Rethink Big, ASAP • Clusters Cap Digital & Systematic • Alliance Big Data • Conferences: Search, iexpo, Crawl the Web... Internet Memory Research 3 Vision • The Web is full of valuable data: Variety Quantity • This data is not so easy to collect, access and process at large scale • Making Web data available will create many new business opportunities for the data ecosystem 22/05/2017 Internet Memory Research 4 Technologies • Large Scale Crawler with high performances • Scalable platform based on A distributed architecture Big data components (Hadoop, Hbase, HDFS,...) • Set of proprietary and open source analytic agents providing Text Mining & Data Mining Semantical operations Statistical operations • Infrastructure 170+ servers Innovative infrastructure with low consumption Internet Memory Research 5 References Internet Memory Research 6 From ✓ ✓ ✓ SaaS, automated software service with a friendly user interface Qualified team to provide quality Combining new technology and user needs Any institution whose aim is to collect and For preserve web material for historical, whom? cultural or heritage purpose National Libraries Large scale crawl for the German National Library 22/05/2017 Archives / Research Selective crawls with high level of Quality Assurance Internet Memory Research A.V. Archives Advanced module for web video and social media content 7 To Web data processing platform Market place for technological bricks Crawl on demande Sources Packages Set of extracted data (price, posts, micro-formats) Internet Memory Research 8 Through Innovative app fighting information deluge and bringing you information sur mesure You give Keywords, and it brings back From the Web and social media Selected hot and relevant news, without all the noise. Today 8+M URLs are sent to the platform and around of the ¼ URLs match with users favorite topics. 22/05/2017 Internet Memory Research 9 Improve your Selection Process o Manual selection VS Newstretto o Automated refreshment rate for active sources (RSS, Forums,...) o Smart discovery crawl for large crawls (topic, language, TLD, ...) Internet Memory Research 10 Nb of Sources 740.000+ RSS feeds Nb of Resources 11 millions (RSS item pages) Size 50 Gb Example of RSS Refreshment Rate (sample) Internet Memory Research 11 Search in your Large Corpus o Full text Index with Elastic Search o Automated categorization (News, Forums, Blogs,...) o Semantic expansion o TopicMatching Internet Memory Research 12 Example of Semantic Expansion Internet Memory Research 13 Extract valuable information from your large corpus for Users / Researchers o o o o o o o Cleaned text Keywords to add Cloud Outlinks to analyze Graphs Structure unstructured data (forums,...) Named entities (partner’s brick) Summarization (partner’s brick) More are coming soon... Internet Memory Research 14 Example of Extracted Data URL User names Thread Content Dates Internet Memory Research 15 What if you could integrate those tools on the top of your current corpus? Internet Memory Research 16 Internet Memory Research Chloé Martin [email protected] Co-founder & Sales Manager http://archivethe.net [email protected] @archivethenet http://mignify.com [email protected] @mignify http://newstretto.com [email protected] @newstretto With the support of the European Commission Internet Memory Research 17