Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
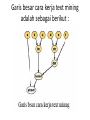
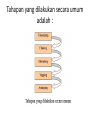
Text Mining Definisi • adalah suatu proses untuk mengambil informasi dari teks yang ada. • Text mining mencari pola-pola yang ada di teks teks dalam bahasa natural yang tidak terstuktur seperti buku, email, artikel, halaman web, dll. • Kegiatan yang biasa dilakukan oleh text mining adalah text categorization, text clustering, conception/entity extraction, dll. Text Mining vs data Mining • Yang membedakan hanyalah sumber data yang digunakan • Data pada Data Mining data yang digunakan adalah data terstruktur • Text mining data yang digunakan adalah data yang tidak terstruktur berupa teks. 3 proses kegiatan text mining 1. Characterization of data Teks yang ada distrukturkan dengan proses seperti parsing, dan diamsukkan ke dalam sebuah database 2. Data mining Dari data yang ada, dilakukan sebuah pencarian dengan algoritma tertentu untuk mendapatkan pola dari data tersebut 3. Data visualization Hasil pencarian yang ada akan diinterpretasi dan dikeluarkan dalam bentuk output yang dapat dimengerti dengan mudah. Preprocessing data TM • yaitu proses pendahulu yang diterapkan terhadap data teks yang bertujuan untuk menghasilkan data numerik. Tahap Preprosesing 1. Penghapusan format dan markup Jika dokumen yang digunakan bukan berupa teks murni maka tahap ini dilakukan. Karena dokumen teks yang biasanya kita lihat berupa format non teks seperti html, pdf atau dalam bentuk word. Formatformat ini mengharuskan sebuah teks dilengkapi unsur-unsur tambahan untuk dapat menghasilkan tampilan yang friendly dimata kita. Informasiinformasi itu dihilangkan karena dianggap tidak perlu dan tidak mencerminkan isi sebuah dokumen teks 2. Penghapusan tanda baca dan angka Tanda baca juga dianggap tidak penting, karena kebetulan dalam penelitian yang saya lakukan tidak memperhatikan keterkaitan kata, kalimat ataupun sejenisnya, so kata dianggap berdiri sendiri. Tahap Preprosesing 3. Pengubahan dari huruf besar ke huruf kecil semua. 4. Parsing dan Stemming Penguraian kata kedalam bentuk tunggal dan pembentukan kata kedalam bentuk dasarnya, sehingga kata-kata yang mempunyai bentuk kata dasar yang sama akan dikelompokkan. 5. Pembobotan Dimulai dengan perhitungan jumlah kata dalam setiap dokumen, yang kemudian akan dihitung menggunakan skema pembobotan yang dikehendaki. Aplikasi Text Mining • Aplikasi Marketing Text mining dapat digunakan untuk cross-selling dan up-selling dengan menganalisis data yang tidak terstruktur yang dihasilkan oleh call center. • Aplikasi Keamanan Pada tahun 2007 ,EUROPOL mengembangkan sistem terintegrasi yang mampu mengakses ,memyimpan dan menganalisis sejumlah besar sumber data terstruktur dan tak terstruktur untuk melacak organisasi kriminal transnasional. • Aplikasi Biomedis PubGene yang menggabungkan text mining biomedis dengan visualisasi jaringan sebagai sebuah layanan Internet. Contoh lainnya yaitu GoPubMed Semantic similarity yang juga telah digunakan oleh sistem text mining, yaitu, GOAnnotato. • Aplikasi Akademik National Centre for Text Mining yang merupakan hasil kolaborasi Universitas Manchester dan Liverpool,digunakan untuk menyediakan customized tools,fasiitas penelitian ,dan saran pada text mining untuk komunitas akademik. Proses Text Mining • Input dari proses text mining berupa kumpulan data terstruktur maupun tidak terstruktur. • Sedangkan outputnya merupakan pengetahuan berkonteks khusus yang dapat digunakan untuk mengambil keputusan. • Kontrol atau hambatan prosesnya mencakup keterbatasan hardware, masalah privasi,kesulitan pemrosesan teks yang ditampilkan dalam bentuk natural language. • Mekanisme proses termasuk teknik yang tepat,peralatan software,dan domain keahlian. Proses Text Mining Pada level yang sangat tinggi proses text mining dapat dipecah menjadi 3 task yaitu : 1) Membentuk Korpus : Bertujuan mengumpulkan semua dokumen yang berhubungan dengan konteks yang sedang dipelajari. Setelah dikumpulkan,dokumen-dokumen teks di ubah dan diorganisir dalam suatu bentuk sehingga dokumen-dokumen tersebut berada dalam bentuk representasi yang sama. 2) Menciptakan term-document matrix : Pada tahap ini,pendigitalan dan peorganisasian dokumen (korpus) digunakan untuk menciptakan term-document matrix (TDM).Tujuan utama tahap ini adalah menkonvert daftar dokumen yang terorganisir kedalam TDM dimana sel-sel nya berisi indeks yang paling tepat. 3) Menggali pengetahuan : text mining menggunakan data mining algoritma seperti klasifikasi,clustering,assosiasi,dan sequence discovery untuk menggali pengetahuan dari algoritma tersebut. Garis besar cara kerja text mining adalah sebagai berikut : Tahapan yang dilakukan secara umum adalah : Tokenizing Tahap Tokenizing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya Filtering Tahap Filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa menggunakan algoritma stop list (membuang kata yang kurang penting) atau word list (menyimpan kata penting) Stemming Tahap stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Tagging Tahap tagging adalah tahap mencari bentuk awal / root dari tiap kata lampau atau kata hasil stemming Analyzing Tahap analyzing merupakan tahap penentuan seberapa jauh keterhubungan antar kata-kata antar dokumen yg ada. Text Mining Tools Commercial Software Tools : ClearForest,IBM Intelligent Miner Data Mining Suite,Megaputer Text Analyst ,SAS Text Miner,SPSS Text Mining,The Statistica Text Mining,VantagePoint,The WordSTat Analysis module,dll. Free Software Tools : bersifat open source diantranya GATE,LingPipe,S-EM(Spy-EM) dan Vivisimo/Clusty. Web Mining • Proses menemukan hubungan intrinsik dari data web yang diekspresikan dalam bentuk tekstual ,linkage atau informasi yang berguna. • Web mining dapat didefinisikan sebagai penemuan dan analisis informasi yang menarik dan berguna dari web,mengenai web dan biasanya menggunakan peralatan berbasis web. • Berdasarkan analisis target,web mining dapat dibagi menjadi 3 jenis yaitu : – Web usage mining, – Web content mining dan – Web structure mining. Analisis Target • Web Usage Mining: Web usage mining adalah penggalian informasi yg berguna dari data yang dihasilkan melalui kunjungan dan transaksi halaman web. Web usage mining mengacu pada pengembangan informasi yang berguna melalui analisis web server log,profil pengguna dan informasi transaksi. • Web Content Mining: Mengacu pada penggalian data yang berguna dari halaman web. Dokumen-dokumen mungkin digali dalam beberapa mesin dengan format yang dapat dibaca sehingga teknik otomatis dapat menghasilkan beberapa informasi mengenai halaman web.Web content mining kadang disebut juga web text mining, karena isi teks adalah daerah yang paling banyak diteliti. Teknologi yang biasa digunakan dalam web content mining adalah NLP (Natural language processing) dan IR (Information retrieval). • Web Structure Mining: Proses penggalian informasi yang berguna dari link-link yang tertanam pada dokumen web. Web structure mining digunakan untuk mengidentifikasi kepemilikan web dan hub,yang mana merupakan pilar dari algoritma page-rank(peringkat halaman). Tahapan Web Mining • Tahapan pada web mining dibagi menjadi tiga kelompok yaitu: preprocess, process, dan, post process. • Tahapan preprocess meliputi data cleaning, transaction identification, integration, dan transformation. • Pada tahap process diterapkan sejumlah formulasi statistik antara lain untuk mengurangi jumlah atribut dengan cara membuang atribut yang tidak berpengaruh (information gain). Pada tahap ini dapat juga dilakukan teknik clustering, asosiasi, dan klasifikasi. • Pada tahap post processing dilakukan analisis lebih lanjut untuk mengolah hasil mining pada tahapan sebelumnya. Hal ini perlu dilakukan sebab sering sekali hasil yang diperoleh pada tahap process tidak memberikan sesuatu yang dapat digunakan secara langsung, sehingga diperlukan teknik lainnya seperti visualisasi grafik dan analisis statistik lainnya. • Tahapan process merupakan tahapan utama dalam web mining. Pada tahap ini, atribut yang akan diolah harus diminimalisasi terlebih dahulu dengan tujuan untuk membuang atirbut yang tidak perlu sehingga hanya atribut yang mempunyai relevansi kuat yang akan diproses, sehingga efisiensi space dan waktu dapat dicapai dan kualitas data yang dihasilkan lebih baik. Salah satu cara untuk mereduksi atribut adalah dengan information gain. Penerapan Web Mining • Peralatan Web Mining menganalisis web logs untuk informasi berguna yang berkaitan dengan pelanggan yang dapat membantu personalisasi situs web berdasarkan perilaku pengguna. Peralatan web mining juga digunakan untuk mencari web untuk kata kunci,frase dan konten lainnya. Web Mining Software • Perangkat lunak open source untuk web mining termasuk RapidMiner, yang menyediakan modul untuk pengelompokan teks, kategorisasi teks, ekstraksi informasi, yang dinamakan pengakuan entitas, dan analisis sentimen. RapidMiner digunakan misalnya pada aplikasi penyaringan berita otomatis untuk personalisasi survey berita. Selesai