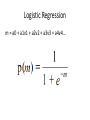Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
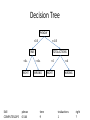
Special Topics in Educational Data Mining HUDK5199 Spring term, 2013 February 18, 2013 Today’s Class • Classification • And then some discussion of features in Excel between end of class and 5pm – We will start today, and continue in future classes as needed Types of EDM method (Baker & Siemens, under review) • Prediction – Classification – Regression – Latent Knowledge Estimation • Structure Discovery – – – – Clustering Factor Analysis Domain Structure Discovery Network Analysis • Relationship mining – – – – Association rule mining Correlation mining Sequential pattern mining Causal data mining • Distillation of data for human judgment • Discovery with models 3 We have already studied • Prediction – Classification – Regression – Latent Knowledge Estimation • Structure Discovery – – – – Clustering Factor Analysis Domain Structure Discovery Network Analysis • Relationship mining – – – – Association rule mining Correlation mining Sequential pattern mining Causal data mining • Distillation of data for human judgment • Discovery with models 4 Today’s Class • Prediction – Classification – Regression – Latent Knowledge Estimation • Structure Discovery – – – – Clustering Factor Analysis Domain Structure Discovery Network Analysis • Relationship mining – – – – Association rule mining Correlation mining Sequential pattern mining Causal data mining • Distillation of data for human judgment • Discovery with models 5 Prediction • Pretty much what it says • A student is using a tutor right now. Is he gaming the system or not? • A student has used the tutor for the last half hour. How likely is it that she knows the skill in the next step? • A student has completed three years of high school. What will be her score on the college entrance exam? Classification • There is something you want to predict (“the label”) • The thing you want to predict is categorical – The answer is one of a set of categories, not a number – CORRECT/WRONG (sometimes expressed as 0,1) • This is what we used in Latent Knowledge Estimation – HELP REQUEST/WORKED EXAMPLE REQUEST/ATTEMPT TO SOLVE – WILL DROP OUT/WON’T DROP OUT – WILL SELECT PROBLEM A,B,C,D,E,F, or G Where do those labels come from? • • • • • • • Field observations Text replays Post-test data Tutor performance Survey data School records Where else? Classification • Associated with each label are a set of “features”, which maybe you can use to predict the label Skill ENTERINGGIVEN ENTERINGGIVEN USEDIFFNUM ENTERINGGIVEN REMOVECOEFF REMOVECOEFF USEDIFFNUM …. pknow 0.704 0.502 0.049 0.967 0.792 0.792 0.073 time 9 10 6 7 16 13 5 totalactions 1 2 1 3 1 2 2 right WRONG RIGHT WRONG RIGHT WRONG RIGHT RIGHT Classification • The basic idea of a classifier is to determine which features, in which combination, can predict the label Skill ENTERINGGIVEN ENTERINGGIVEN USEDIFFNUM ENTERINGGIVEN REMOVECOEFF REMOVECOEFF USEDIFFNUM …. pknow 0.704 0.502 0.049 0.967 0.792 0.792 0.073 time 9 10 6 7 16 13 5 totalactions 1 2 1 3 1 2 2 right WRONG RIGHT WRONG RIGHT WRONG RIGHT RIGHT Classification • Of course, usually there are more than 4 features • And more than 7 actions/data points • These days, 800,000 student actions, and 26 features, would be a medium-sized data set Classifiers • There are literally hundreds of classification algorithms that have been proposed/published/tried out • A good data mining package will have many implementations – – – – RapidMiner SAS Enterprise Miner Weka KEEL Domain-Specificity • Specific algorithms work better for specific domains and problems • We often have hunches for why that is • But it’s more in the realm of “lore” than really “engineering” Some algorithms you probably don’t want to use • Support Vector Machines – Conducts dimensionality reduction on data space and then fits hyperplane which splits classes – Creates very sophisticated models – Great for text mining – Great for sensor data – Usually pretty lousy for educational log data Some algorithms you probably don’t want to use • Genetic Algorithms – Uses mutation, combination, and natural selection to search space of possible models – Obtains a different answer every time (usually) – Seems really awesome – Usually doesn’t produce the best answer Some algorithms you probably don’t want to use • Neural Networks – Composes extremely complex relationships through combining “perceptrons” – Usually over-fits for educational log data Note • Support Vector Machines and Neural Networks are great for some problems • I just haven’t seen them be the best solution for educational log data Some algorithms you might find useful • • • • • Step Regression Logistic Regression J48/C4.5 Decision Trees JRip Decision Rules K* Instance-Based Classifier • There are many others! Logistic Regression Logistic Regression • Already discussed in class • Fits logistic function to data to find out the frequency/odds of a specific value of the dependent variable • Given a specific set of values of predictor variables Logistic Regression m = a0 + a1v1 + a2v2 + a3v3 + a4v4… Logistic Regression p(m) 1.2 1 0.8 0.6 0.4 0.2 0 -4 -3 -2 -1 0 1 2 3 4 Parameters fit • Through Expectation Maximization Relatively conservative • Thanks to simple functional form, is a relatively conservative algorithm – Less tendency to over-fit Good for • Cases where changes in value of predictor variables have predictable effects on probability of predictor variable class Good when multi-level interactions are not particularly common • Can be given interaction effects through automated feature distillation – We’ll look at this later • But is not particularly optimal for this Note • RapidMiner and Weka do not actually choose features for you • You have to select features by hand • Or in java code that calls RapidMiner or Weka • Easy to implement step-wise regression by hand, painful to implement other feature selection algorithms Step Regression Step Regression • Fits a linear regression function – (discussed in detail in a later class) – with an arbitrary cut-off • Selects parameters • Assigns a weight to each parameter • Computes a numerical value • Then all values below 0.5 are treated as 0, and all values >= 0.5 are treated as 1 Example • Y= 0.5a + 0.7b – 0.2c + 0.4d + 0.3 • Cut-off 0.5 a b c d 1 1 1 1 0 0 0 0 -1 -1 1 3 Parameters fit • Through Iterative Gradient Descent • This is a simple enough model that this approach actually works… Most conservative • This is the most conservative classifier except for the fabled “0R” – More on that in a minute Good for • Cases where relationships between predictor and predicted variables are relatively linear Good when multi-level interactions are not particularly common • Can be given interaction effects through automated feature distillation – We’ll look at this later • But is not particularly optimal for this Feature Selection • Greedy – simplest model • M5’ – in between • None – most complex model Greedy • Also called Forward Selection – Even simpler than Stepwise Regression 1. Start with empty model 2. Which remaining feature best predicts the data when added to current model 3. If improvement to model is over threshold (in terms of SSR or statistical significance) 4. Then Add feature to model, and go to step 2 5. Else Quit M5’ • Will be discussed in detail in regression lecture 0R 0R • Always say 0 Decision Trees Decision Tree PKNOW <0.5 >=0.5 TIME Skill COMPUTESLOPE TOTALACTIONS <6s. >=6s. RIGHT WRONG pknow 0.544 time 9 <4 RIGHT >=4 WRONG totalactions 1 right ? Decision Tree Algorithms • There are several • I usually use J48, which is an open-source reimplementation of C4.5 (Quinlan, 1993) J48/C4.5 • Can handle both numerical and categorical predictor variables – Tries to find optimal split in numerical variable • Repeatedly looks for variable which best splits the data in terms of predictive power for each variable (using information gain) • Later prunes out branches that turn out to have low predictive power • Note that different branches can have different features! Can be adjusted… • To split based on more or less evidence • To prune based on more or less predictive power Relatively conservative • Thanks to pruning step, is a relatively conservative algorithm – Less tendency to over-fit Good when data has natural splits 16 14 12 10 8 6 4 2 20 0 1 18 16 14 12 10 8 6 4 2 0 1 2 3 4 5 6 7 8 9 10 11 2 3 4 5 6 7 8 9 10 11 Good when multi-level interactions are common Good when same construct can be arrived at in multiple ways • A student is likely to drop out of college when he – Starts assignments early but lacks prerequisites • OR when he – Starts assignments the day they’re due Decision Rules Many Algorithms • Differences are in terms of what metric is used and how rules are generated • Most popular subcategory (including JRip and PART) repeatedly creates decision trees and distills best rules Generating Rules from Decision Tree 1. Create Decision Tree 2. If there is at least one path that is worth keeping, go to 3 else go to 6 3. Take the “Best” single path from root to leaf and make that path a rule 4. Remove all data points classified by that rule from data set 5. Go to step 1 6. Take all remaining data points 7. Find the most common value for those data points 8. Make an “otherwise” rule using that Relatively conservative • Leads to simpler models than most decision trees – Less tendency to over-fit Very interpretable model • Unlike most other approaches Example (Baker & Clarke-Midura, under review) 1. IF the student spent at least 66 seconds reading the parasite information page, THEN the student will obtain the correct final conclusion (confidence = 81.5%) 2. IF the student spent at least 12 seconds reading the parasite information page AND the student read the parasite information page at least twice AND the student spent no more than 51 seconds reading the pesticides information page, THEN the student will obtain the correct final conclusion (confidence = 75.0%) 3. IF the student spent at least 44 seconds reading the parasite information page AND the student spent under 56 seconds reading the pollution information page, THEN the student will obtain the correct final conclusion (confidence = 68.8%) 4. OTHERWISE the student will not obtain the correct final conclusion (confidence = 89.0%) Good when multi-level interactions are common Good when same construct can be arrived at in multiple ways • A student is likely to drop out of college when he – Starts assignments early but lacks prerequisites • OR when he – Starts assignments the day they’re due K* Instance-Based Classifier • Takes a data point to predict • Finds the K closest points to that data point, by Euclidean distance – K often equals 3 • Gives data point whichever class is most common among those 3 points Good when data is very divergent • Lots of different processes can lead to the same result • Impossible to find general rules • But data points that are similar tend to be from the same class Big Drawback • To use the model, you need to have the whole data set Big Advantage • Sometimes works when nothing else works • Has been useful for my group in affect detection Comments? Questions? Generating Confidences • Each of these approaches gives not just a final answer, but a confidence (or pseudoconfidence) • Many applications of confidences – we’ll discuss in detail in next lecture Generating Confidences • Step Regression – raw value of regression • Logistic Regression – p(m) • Jrip/J48 – ratio of correct classifications to incorrect classifications in each leaf – I will show you an example of this in a minute Hands-On Activity • Running algorithm in RapidMiner 4.6 • Using some made-up data, just to see how things work Open RapidMiner • And open classifier.xml • Let’s go through this script Use RapidMiner • Run JRip without cross-validation • Run JRip with action-level cross-validation • Run Jrip with batch-level cross-validation – Set to implement student-level cross-validation – We’ll discuss this more in the next lecture Confidences • How to interpret model confidence from RapidMiner output Let’s look at the data • Are there any features we shouldn’t be using? Remove those features • Run the model again Run other algorithms • J48 Run other algorithms • J48 • K* Run other algorithms • J48 • K* • Step Regression Run other algorithms • J48 • K* • Step Regression – Why didn’t Step Regression work? – How can we fix it? Comments? Questions? Comments or Questions • About Assignment 3? Next Class • Wednesday, February 20 • Behavior Detection • Assignment Due: 3. Behavior Detection Excel • Plan is to go as far as we can by 5pm • We will continue after next class session • Vote on which topics you most want to hear about Topics • • • • • • • • • • • • Using average, count, sum, stdev (asgn. 4 data set) Relative and absolute referencing (made up data) Copy and paste values only (made up data) Using sort, filter (asgn. 4 data set) Making pivot table (asgn. 4 data set) Using vlookup (Jan. 28 class data set) Using countif (asgn. 4 data set) Making scatterplot (Jan. 28 class data set) Making histogram (asgn. 4 data set) Equation Solver (Jan. 28 class data set) Z-test (made up data) 2-sample t-test (made up data) • Other topics? The End