Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
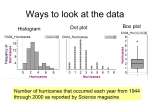
Appendix B Statistical Methods Statistical Methods: Graphing Data Frequency distribution Histogram Frequency polygon Table of Contents B.1 - Graphing data. (a) Our raw data are tallied into a frequency distribution. (b) The same data are portrayed in a bar graph called a histogram. (c) A frequency polygon is plotted over the histogram. (d) The resultant frequency polygon is shown by itself. Table of Contents Descriptive Statistics Measures of Central Tendency Mean Median Mode Skewed Distributions Negative/Positive Measuring Variability Standard Deviation Table of Contents B.2 - Measures of central tendency. The mean, median, and mode usually converge, as in the case of our TV viewing data. Table of Contents B.3 - Measures of central tendency in skewed distributions. In a symmetrical distribution (a), the three measures of central tendency converge. However, in a negatively skewed distribution (b) or in a positively skewed distribution (c), the mean, median, and mode are pulled apart as shown here. Typically, in these situations the median provides the best index of central tendency. Table of Contents B.4 - The standard deviation and dispersion of data. Although both these distributions of golf scores have the same mean, their standard deviations will be different. In (a) the scores are bunched together and there is less variability than in (b), yielding a lower standard deviation for the data in distribution (a). Table of Contents B.5 - Steps in calculating the standard deviation. (1) Add the scores (X) and divide by the number of scores (N) to calculate the mean (which comes out to 3.0 in this case). (2) Calculate each score’s deviation from the mean by subtracting the mean from each score (the results are shown in the second column). (3) Square these deviations from the mean and total the results to obtain (d2) as shown in the third column. (4) Insert the numbers for N and d2 into the formula for the standard deviation and compute the results. Table of Contents The Normal Distribution Psychological tests – Relative measures – Standard deviation the unit of measure Conversion to percentile scores Table of Contents B.6 - The normal distribution. Many characteristics are distributed in a pattern represented by this bellshaped curve (each dot represents a case). The horizontal axis shows how far above or below the mean a score is (measured in plus or minus standard deviations). The vertical axis shows the number of cases obtaining each score. In a normal distribution, most cases fall near the center of the distribution, so that 68.26% of the cases fall within plus or minus 1 standard deviation of the mean. The number of cases gradually declines as one moves away from the mean in either direction, so that only 13.59% of the cases fall between 1 and 2 standard deviations above or below the mean, and even fewer Table of Contents cases (2.14%) fall between 2 and 3 standard deviations above or below the mean. B.7- The normal distribution and SAT scores. The normal distribution is the basis for the scoring system on many standardized tests. For example, on the Scholastic Aptitude Test (SAT), the mean is set at 500 and the standard deviation at 100. Hence, an SAT score tells you how many standard deviations above or below the mean you scored. For example, a score of 700 means you scored 2 standard deviations above the mean. Table of Contents Measuring Correlation Correlation coefficient – Positive = direct relationship – Negative = inverse relationship Magnitude: 0 to plus/minus 1 Scatter diagrams Correlation of determination Table of Contents B.8 - Scatter diagrams of positive and negative correlations. Scatter diagrams plot paired X and Y scores as single points. Score plots slanted in the opposite direction result from positive (top row) as opposed to negative (bottom row) correlations. Moving across both rows (to the right), you can see that progressively weaker correlations result in more and more scattered plots of data points. Table of Contents B.9 - Scatter diagram of the correlation between TV viewing and SAT scores. Our hypothetical data relating TV viewing to SAT scores are plotted in this scatter diagram. Compare it to the scatter diagrams seen in Figure B.8 and see whether you can estimate the correlation between TV viewing and SAT scores in our data (see the text for the answer). Table of Contents B.10 - Computing a correlation coefficient. The calculations required to compute the Pearson productmoment coefficient of correlation are shown here. The formula looks intimidating, but it’s just a matter of filling in the figures taken from the sums of the columns shown above the formula. Table of Contents B.11 - Correlation and the coefficient of determination. The coefficient of determination is an index of a correlation’s predictive power. As you can see, whether positive or negative, stronger correlations yield greater predictive power. Table of Contents Hypothesis Testing Inferential statistics Sample Population Null hypothesis vs. research hypothesis Statistical significance Table of Contents B.12 - The relationship between the population and the sample. In research, we are usually interested in a broad population, but we can observe only a small sample from the population. After making observations of our sample, we draw inferences about the population, based on the sample. This inferential process works well as long as the sample is reasonably representative of the population. Table of Contents