Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
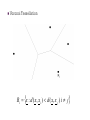
Pattern Recognition and Image Analysis Dr. Manal Helal – Fall 2014 Lecture 3 BAYES DECISION THEORY In Action 2 2 Recap Example Example (cont.) Example (cont.) Assign colours to objects. Example (cont.) Example (cont.) Example (cont.) Example (cont.) Assign colour to pen objects. Example (cont.) Example (cont.) Assign colour to paper objects. Example (cont.) Example (cont.) Bayes Discriminate Functions 14 15 Bayes Discriminate Functions Bayes Discriminate Functions (gi(x), i = 1, . . . , c), assigns feature vector x to class 1 … c 1. Minimum Error Rate Classification 2. Minimum Risk Classification Special Cases for 3) Euclidean Distance and 4) Mahalanobis Distance Discriminate Functions given last week. Other geometric functions are introduced in the following slides and many others in literature. DISCRIMINANT FUNCTIONS 5. DECISION SURFACES If Ri , R j are contiguous: g ( x) P(i x) P( j x) 0 Ri : P(i x) P( j x) + - R j : P( j x) P(i x) g ( x) 0 is the surface separating the regions. On one side is positive (+), on the other is negative (-). It is known as Decision Surface 16 17 If f(.) monotonic, the rule remains the same if we use: x i if : f (P(i x)) f (P( j x)) i j gi ( x) f ( P(i x)) is a discriminant function In general, discriminant functions can be defined independent of the Bayesian rule. They lead to suboptimal solutions, yet if chosen appropriately, can be computationally more tractable. Case 5: Decision Surface 6. BAYESIAN CLASSIFIER FOR NORMAL DISTRIBUTIONS Multivariate Gaussian pdf p ( x i ) 1 2 (2 ) i 1 2 1 exp ( x i ) i1 ( x i ) 2 i E x matrix in i i E ( x i )( x i ) called covariance matrix 19 20 ln( ) is monotonic. Define: g i ( x) ln( p( x i ) P(i )) ln p( x i ) ln P(i ) 1 T 1 g i ( x) ( x i ) i ( x i ) ln P(i ) Ci 2 1 Ci ( ) ln 2 ( ) ln i 2 2 Example: 2 0 i 2 0 g i ( x) 1 2 2 1 2 2 (x x ) 2 1 2 2 1 2 ( i1 x1 i 2 x2 ) ( i21 i22 ) ln( Pi ) Ci That is, g i (x) is quadratic and the surfaces g i ( x) g j ( x) 0 quadrics, ellipsoids, parabolas, hyperbolas, pairs of lines. For example: 21 Case 6: Hyper-planes Case 7: Arbitrary EXAMPLE: EXAMPLE (cont.): EXAMPLE (cont.): Find the discriminant function for the first class. EXAMPLE (cont.): Find the discriminant function for the first class. EXAMPLE (cont.): Similarly, find the discriminant function for the second class. EXAMPLE (cont.): The decision boundary: EXAMPLE (cont.): The decision boundary: EXAMPLE (cont.): Using MATLAB we can draw the decision boundary: (to draw the decision boundary in MATLAB) >> s = 'x^2-10*x-4*x*y+8*y1+2*log(2)'; >> ezplot(s) EXAMPLE (cont.): Using MATLAB we can draw the decision boundary: EXAMPLE (cont.): Voronoi Tessellation Ri x : d ( x, x i ) d ( x, x j ) i j 34 Receiver Operating Characteristics Another measure of distance between two Gaussian distributions. found a great use in medicine, radar detection and other fields. Receiver Operating Characteristics Receiver Operating Characteristics Receiver Operating Characteristics Receiver Operating Characteristics • If both diagnosis and test are positive, it is called a true positive. The probability of a TP to occur is estimated by counting the true positives in the sample and divide by the sample size. • If the diagnosis is positive and the test is negative it is called a false negative (FN). • False positive (FP) and true negative (TN) are defined similarly. Receiver Operating Characteristics • The values described are used to calculate different measurements of the quality of the test. • The first one is sensitivity, SE, which is the probability of having a positive test among the patients who have a positive diagnosis. Receiver Operating Characteristics Specificity, SP, is the probability of having a negative test among the patients who have a negative diagnosis. Receiver Operating Characteristics • Example: Receiver Operating Characteristics • Example (cont.): Receiver Operating Characteristics • Overlap in distributions: BAYESIAN NETWORKS Bayes Probability Chain Rule p( x1 , x2 ,..., x ) p( x | x 1 ,..., x1 ) p( x 1 | x 2 ,..., x1 ) ... ... p( x2 | x1 ) p( x1 ) Assume now that the conditional dependence for each xi is limited to a subset of the features appearing in each of the product terms. That is: p( x1 , x2 ,..., x ) p( x1 ) p( xi | Ai ) i 2 where Ai xi 1 , xi 2 ,..., x1 45 For example, if ℓ=6, then we could assume: p( x6 | x5 ,..., x1 ) p( x6 | x5 , x4 ) Then: A6 x5 , x4 x5 ,..., x1 The above is a generalization of the Naïve – Bayes. For the Naïve – Bayes the assumption is: Ai = Ø, for i=1, 2, …, ℓ 46 A graphical way to portray conditional dependencies is given below According to this figure we have that: • x6 is conditionally dependent on x4, x5. • x5 on x4 • x4 on x1, x2 • x3 on x2 • x1, x2 are conditionally independent on other variables. For this case: p( x1 , x2 ,..., x6 ) p( x6 | x5 , x4 ) p( x5 | x4 ) p( x3 | x2 ) p( x2 ) p( x1 ) 47 Bayesian Networks Definition: A Bayesian Network is a directed acyclic graph (DAG) where the nodes correspond to random variables. Each node is associated with a set of conditional probabilities (densities), p(xi|Ai), where xi is the variable associated with the node and Ai is the set of its parents in the graph. A Bayesian Network is specified by: The marginal probabilities of its root nodes. The conditional probabilities of the non-root nodes, given their parents, for ALL possible combinations. 48 The figure below is an example of a Bayesian Network corresponding to a paradigm from the medical applications field. This Bayesian network models conditional dependencies for an example concerning smokers (S), tendencies to develop cancer (C) and heart disease (H), together with variables corresponding to heart (H1, H2) and cancer (C1, C2) medical tests. 49 Once a DAG has been constructed, the joint probability can be obtained by multiplying the marginal (root nodes) and the conditional (non-root nodes) probabilities. Training: Once a topology is given, probabilities are estimated via the training data set. There are also methods that learn the topology. Probability Inference: This is the most common task that Bayesian networks help us to solve efficiently. Given the values of some of the variables in the graph, known as evidence, the goal is to compute the conditional probabilities for some of the other variables, given the evidence. 50 Example: figure: Consider the Bayesian network of the P(y1) = P(y1|x1) * P(x1) + P(y1|x0) * P(X0) P(y1) = 0.40* 0.60+ 0.30* 0.40 P(y1) = 0.24 + 0.12 = 0.36 a) If x is measured to be x=1 (x1), compute P(w=0|x=1) [P(w0|x1)]. b) If w is measured to be w=1 (w1) compute P(x=0|w=1) 51 [ P(x0|w1)]. For a), a set of calculations are required that propagate from node x to node w. It turns out that P(w0|x1) = 0.63. For b), the propagation is reversed in direction. It turns out that P(x0|w1) = 0.4. In general, the required inference information is computed via a combined process of “message passing” among the nodes of the DAG. Complexity: For singly connected graphs, message passing algorithms amount to a complexity linear in the number of nodes. 52 53 Practical Labs On Moodle you will find two Baysian Classification examples: Image Classification Text Classification