Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
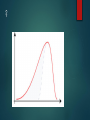
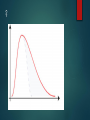
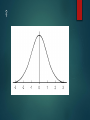
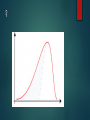
Lesson 6 NORMAL AND SKEWED DISTRIBUTION TYPE ONE AND TYPE TWO ERRORS Level of significance and errors Level of significance accepted in psychology? 0.05 - 5% 0.1 - 10% Too lenient 0.01 – 1% Too stringent but highly significant 0.1 – What is the problem with accepting the experimental hypothesis? 0.01 – what is the problem with rejecting the experimental hypothesis and accepting the null? Type 1 & 2 Errors There is a possibility that errors may have been made: Type 1 Error Deciding to reject the null when actually the results was due to chance or some other factor. Type 2 Error Deciding to retain the null when actually the result was caused by the IV. Too Low P = <0.10 Type 1 Error more likely Too High P = <0.001 Type 2 Error more likely Normal and Skewed Distribution Small samples – central tendency and standard deviation useful statistics Larger samples – useful to examine overall distribution formed by the data Examining distributions can show trends in the data and we can estimate the distribution of scores in the whole population Why is distribution important? Inferential statistics – non-parametric tests Parametric – mathematical calculations are used Used if there is normal distribution, interval or ration data and similarity of variance An outlier that affects the mean may distort the data So non-parametric tests are used if these conditions are not met Normal and Skewed Distribution If mean, median and mode are the same/similar and focus around he middle set of scores (median) then there is normal distribution Multi-modal – not normally distributed When mean, median and mode are not similar – distribution will be skewed Mainly below mean – negative skew Mainly above mean – positive skew Interval Data only Interval. Data that are measured on some kind of scale, often temporal (e.g., the days of the week, hours of the day) where the differences between adjacent scale numbers are equal. Ordinal. Elements of the data describe properties of objects or events that are ordered by some characteristic (e.g., how would you rank oranges as a snack food compared to tomatoes?) The order of the objects does not, however, provide any information about the distance along the continuum between any two adjacent items. Nominal. Categories. This is simply putting items together without ordering or ranking them Distribution – only considered for interval data So that mathematical calculations can be carried out Normal distribution Positively skewed distribution Negatively skewed distribution When scores are clustered around the mean and when the mean median and mode are similar When scores are clustered below the mean and the mode shows that When scores are clustered above the mean and the mode shows that Normal distribution, Negatively or positively skewed scores? Mean=? Median=? Mode=? 2. Provide a title Frequency for the……… Normal distribution, Negatively or positively skewed scores? Mean=? Median=? Mode=? 2. Provide a title Frequency for the……… Normal distribution, Negatively or positively skewed scores? Mean=? Median=? Mode=? 2. Provide a title Frequency for the……… Indicate the position of the mean median and mode Normal distribution, Negatively or positively skewed scores? Scores Scores Scores 2 2 2 3 3 3 3 4 5 3 5 6 4 6 6 5 7 9 6 8 9 6 8 9 9 12 11 11 12 11 12 12 13 13 16 16 Normal Distribution Bell shaped curve Mean, median and mode should be aligned around the mid -point Tail ends shouldn’t meet the horizontal axis We can estimate the % of people that fall under the curve at each standard deviation 68% of the population fall between one standard deviation and 2 standard deviations etc…. ? Imagine it is a whale! Whale swimming towards vertical axis – coming home positive Away from vertical axis – leaving home negative ? ? ? ? H/W Task 1. Work out the mean, median and mode for each set of scores (3 marks) 2. Is the set of scores for the ‘sound alike’ condition normally distributed? Explain your answer (2 marks)