Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
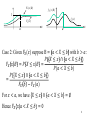
Random Variables and Stochastic Processes – 0903720 Dr. Ghazi Al Sukkar Email: [email protected] Office Hours: refer to the website Course Website: http://www2.ju.edu.jo/sites/academic/ghazi.alsukkar 1 Conditional Distributions • Conditional Probability. • Two cases for the conditioning event. • Total probability and Bayes’ Theorem. – Continuous version of Total probability Theorem – Continuous version of Bayes’ Theorem • A posteriori and a priori pdf s relation. Conditional Probability • For any two events A and B, we have defined the conditional probability of A given B as 𝑃(𝐴𝐵) 𝑃 𝐴𝐵 = ,𝑃 𝐵 ≠ 0 𝑃(𝐵) • Noting that the probability distribution function 𝐹𝑋 (𝑥) is given by 𝐹𝑋 𝑥 = 𝑃 𝑋 𝜁 ≤ 𝑥 . We may define the conditional distribution of the R.V 𝑋 given the event 𝐵 as: 𝑃 𝑋 𝜁 ≤𝑥 ∩𝐵 𝑃 𝑋 𝜁 ≤ 𝑥, 𝐵 𝐹𝑋 𝑥 𝐵 = 𝑃 𝑋 𝜁 ≤ 𝑥|𝐵 = = 𝑃(𝐵) 𝑃(𝐵) The event 𝑋 𝜁 ≤ 𝑥, 𝐵 consists of all outcomes 𝜁 such that 𝑋 𝜁 ≤ 𝑥 and 𝜁 ∈ 𝐵. 3 • Thus the definition of the conditional distribution depends on conditional probability, and since it obeys all probability axioms, it follows that the conditional distribution has the same properties as any distribution function. In particular: 𝑃 𝑋 ≤ +∞, 𝐵 𝑃(𝐵) 𝐹𝑋 +∞ 𝐵 = = =1 𝑃(𝐵) 𝑃(𝐵) 𝑃 𝑋 ≤ −∞, 𝐵 𝑃(∅) 𝐹𝑋 −∞ 𝐵 = = =0 𝑃(𝐵) 𝑃(𝐵) • Further 𝑃 𝑥1 < 𝑋 ≤ 𝑥2 , 𝐵 𝐹𝑋 𝑥1 < 𝑋 ≤ 𝑥2 𝐵 = 𝑃(𝐵) = 𝐹𝑋 𝑥2 𝐵 − 𝐹𝑋 𝑥1 𝐵 4 • The conditional density function is the derivative of the conditional distribution function. Thus: 𝑑𝐹𝑋 (𝑥|𝐵) 𝑃 𝑥 ≤ 𝑋 ≤ 𝑥 + ∆𝑥|𝐵 𝑓𝑋 𝑋 𝐵 = = lim ∆𝑥→0 𝑑𝑥 ∆𝑥 • And 𝑥 𝐹𝑋 𝑥 𝐵 = 𝑓𝑋 𝑢 𝐵 𝑑𝑢 −∞ • Also: 𝑥2 𝑃 𝑥1 < 𝑋 ≤ 𝑥2 |𝐵 = 𝑓𝑋 𝑥|𝐵 𝑑𝑥 𝑥1 5 Example: Toss a coin and 𝑋(𝑇) = 0, 𝑋(𝐻) = 1. Suppose 𝐵 = {𝐻} Determine 𝐹𝑋 (𝑥|𝐵). Solution: 𝐹𝑋 (𝑥) has the shown form. We need 𝐹𝑋 (𝑥|𝐵) for all 𝑥. - For 𝑥 < 0, 𝑋 ≤ 𝑥 = ∅, so that and 𝐹𝑋 𝑥 𝐵 = 0. 𝑋 ≤𝑥 ∩𝐵 =∅ - For 0 ≤ 𝑥 < 1, 𝑋 ≤ 𝑥 = {𝑇}, so that and 𝐹𝑋 𝑥 𝐵 = 0. - For 𝑥 ≥ 1, 𝑋 ≤ 𝑥 = {𝐻, 𝑇}, so that and 𝐹𝑋 𝑥 𝐵 = 1. 𝑋 ≤𝑥 ∩𝐵 = 𝑇 ∩ 𝐻 =∅ 𝑋 ≤ 𝑥 ∩ 𝐵 = 𝑆 ∩ 𝐻 = {𝐻} FX (x) FX ( x | B) 1 1 q 1 x 1 x 6 Two cases for the event B • Case 1: Given 𝐹𝑋 (𝑥) suppose 𝐵 = 𝑋(𝜁) ≤ 𝑎 • 𝐹𝑋 𝑥 𝐵 = 𝑃 𝑋 ≤ 𝑥|𝑋 ≤ 𝑎 = 𝑃 𝑋≤𝑥 ∩ 𝑋≤𝑎 𝑃(𝑋≤𝑎) • For 𝑥 < 𝑎 ⟹ 𝑋 ≤ 𝑥 ∩ 𝑋 ≤ 𝑎 = 𝑋 ≤ 𝑥 , then • 𝐹𝑋 𝑥 𝐵 = 𝑃 𝑋≤𝑥 𝑃(𝑋≤𝑎) = 𝐹𝑋 (𝑥) 𝐹𝑋 (𝑎) • For 𝑥 ≥ 𝑎 ⟹ 𝑋 ≤ 𝑥 ∩ 𝑋 ≤ 𝑎 = 𝑋 ≤ 𝑎 so that • 𝐹𝑋 𝑥 𝐵 = 1 • Thus • 𝐹𝑋 𝑥 𝑋 ≤ 𝑎 = 𝐹𝑋 (𝑥) ,𝑥 𝐹𝑋 (𝑎) <𝑎 1, 𝑥 ≥ 𝑎 • And hence • 𝑓𝑋 𝑥 𝑋 ≤ 𝑎 = 𝑑𝐹𝑋 (𝑥|𝑋≤𝑎) 𝑑𝑥 = 𝑓𝑋 (𝑥) 𝐹𝑋 (𝑎) = 𝑓𝑋 (𝑥) 𝑎 𝑓 −∞ 𝑋 𝑥 𝑑𝑥 ,𝑥 < 𝑎 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 7 FX ( x | B) f X ( x | B) 1 f X (x ) FX (x) a x x a Case 2: Given 𝐹𝑋 (𝑥) suppose B = 𝑎 < 𝑋 ≤ 𝑏 with 𝑏 > 𝑎: 𝑃 𝑋≤𝑥 ∩ 𝑎<𝑋≤𝑏 𝐹𝑋 𝑥 𝐵 = 𝑃 𝑋 ≤ 𝑥|𝐵 = 𝑃(𝑎 < 𝑋 ≤ 𝑏) 𝑃 𝑋≤𝑥 ∩ 𝑎<𝑋≤𝑏 = 𝐹𝑋 𝑏 − 𝐹𝑋 (𝑎) For 𝑥 < 𝑎, we have 𝑋 ≤ 𝑥 ∩ 𝑎 < 𝑋 ≤ 𝑏 = ∅ Hence 𝐹𝑋 𝑥 𝑎 < 𝑋 ≤ 𝑏 = 0 8 For 𝑎 ≤ 𝑥 < 𝑏 we have 𝑋 ≤ 𝑥 ∩ 𝑎 < 𝑋 ≤ 𝑏 = 𝑎 < 𝑋 ≤ 𝑥 and hence 𝑃 𝑎<𝑋≤𝑥 𝐹𝑋 𝑥 − 𝐹𝑋 (𝑎) 𝐹𝑋 𝑥 𝑎 < 𝑋 ≤ 𝑏 = = 𝐹𝑋 𝑏 − 𝐹𝑋 (𝑎) 𝐹𝑋 𝑏 − 𝐹𝑋 (𝑎) For 𝑥 ≥ 𝑏, we have 𝑋 ≤ 𝑥 ∩ 𝑎 < 𝑋 ≤ 𝑏 = 𝑎 < 𝑋 ≤ 𝑏 so that 𝐹𝑋 𝑥 𝑎 < 𝑋 ≤ 𝑏 = 1 ⟹ 𝑓𝑋 𝑥 𝑎 < 𝑋 ≤ 𝑏 = 𝑓𝑋 (𝑥) ,𝑎 𝐹𝑋 𝑏 −𝐹𝑋 (𝑎) <𝑥≤𝑏 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 f X ( x | B) f X (x ) a b x Note: In both cases the result is a new R.V. since we get new CDF and PDF. 9 Example • Determine the Conditional Density function 𝑓𝑋 (𝑥| 𝑋 − 𝜇 ≤ 𝑘𝜎 for 𝑁(𝜇, 𝜎 2 ) RV. Sol: 𝑓𝑋 𝑥 𝑋 − 𝜇 ≤ 𝑘𝜎 = 𝑓𝑋 𝑥 −𝑘𝜎 ≤ 𝑋 − 𝜇 ≤ 𝑘𝜎 = 𝑓𝑋 (𝑥| −𝑘𝜎 + 𝜇 ≤ 𝑋 ≤ 𝑘𝜎 + 𝜇 𝑓𝑋 (𝑥) , 𝜇 − 𝑘𝜎 < 𝑥 ≤ 𝜇 + 𝑘𝜎 1 = 𝐹𝑋 𝜇 + 𝑘𝜎 − 𝐹𝑋 (𝜇 − 𝑘𝜎) 2 2 𝑓𝑋 𝑥 = 𝑒 −(𝑥−𝜇) /2𝜎 0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 𝜎 2𝜋 𝑓𝑋 𝑥 = 1 2𝜋𝜎 𝑒 − 𝑥−𝜇 2 𝐹𝑋 𝜇 + 𝑘𝜎 = 𝐺 𝐹𝑋 𝜇 − 𝑘𝜎 = 𝐺 2 2𝜎2 𝜇+𝑘𝜎−𝜇 𝜎 𝜇−𝑘𝜎−𝜇 𝜎 = 𝐺(𝑘) = 𝐺(−𝑘) 𝑘 𝐹𝑋 𝜇 + 𝑘𝜎 − 𝐹𝑋 𝜇 − 𝑘𝜎 = 𝐺 𝑘 − 𝐺 −𝑘 = 2 0 𝜇 1 2𝜋 𝑒− 𝑘 𝑥 2 2 𝑑𝑥 10 Total probability and Bayes’ Theorem If {A1, A2, …, An} is a partition of the sample space of an experiment and 𝑃(𝐴𝑖) > 0 for i = 1,2,…, n, then for any event B of S, 𝑛 𝑃 𝐵 = 𝑃 𝐵 𝐴1 𝑃 𝐴1 + 𝑃 𝐵 𝐴2 𝑃 𝐴2 + ⋯ + 𝑃 𝐵 𝐴𝑛 𝑃 𝐴𝑛 = 𝑃 𝐵 𝐴𝑖 𝑃 𝐴𝑖 𝑖=1 Let 𝐵 = 𝑋 ≤ 𝑥 , ⟹ 𝑃 𝑋 ≤ 𝑥 = 𝑃 𝑋 ≤ 𝑥|𝐴1 𝑃 𝐴1 + 𝑃 𝑋 ≤ 𝑥|𝐴2 𝑃 𝐴2 + ⋯ + 𝑃 𝑋 ≤ 𝑥|𝐴𝑛 𝑃 𝐴𝑛 So 𝑛 𝐹𝑋 𝑥 = 𝐹𝑋 𝑥 𝐴1 𝑃 𝐴1 + 𝐹𝑋 𝑥 𝐴2 𝑃 𝐴2 + ⋯ + 𝐹𝑋 𝑥 𝐴𝑛 𝑃 𝐴𝑛 = And 𝐹𝑋 𝑥 𝐴𝑖 𝑃(𝐴𝑖 ) 𝑖=1 𝑛 𝑓𝑋 𝑥 = 𝑓𝑋 𝑥 𝐴1 𝑃 𝐴1 + 𝑓𝑋 𝑥 𝐴2 𝑃 𝐴2 + ⋯ + 𝑓𝑋 𝑥 𝐴𝑛 𝑃 𝐴𝑛 = 𝑓𝑋 𝑥 𝐴𝑖 𝑃(𝐴𝑖 ) 𝑖=1 11 • For any two events A and B, Bayes’ theorem gives 𝑃 𝐵 𝐴 𝑃(𝐴) 𝑃 𝐴|𝐵 = 𝑃(𝐵) • By setting 𝐵 = 𝑋 ≤ 𝑥 𝑃 𝑋 ≤ 𝑥 𝐴 𝑃(𝐴) 𝐹𝑋 𝑥 𝐴 𝑃 𝐴|𝑋 ≤ 𝑥 = = 𝑃(𝐴) 𝑃(𝑋 ≤ 𝑥) 𝐹𝑋 𝑥 • By setting 𝐵 = 𝑥1 < 𝑋 ≤ 𝑥2 𝑃 𝑥1 < 𝑋 ≤ 𝑥2 𝐴 𝑃(𝐴) 𝑃 𝐴|𝑥1 < 𝑋 ≤ 𝑥2 = 𝑃(𝑥1 < 𝑋 ≤ 𝑥2 ) 𝑥2 𝑓 𝑥 𝐴 𝑑𝑥 𝐹𝑋 𝑥2 𝐴 − 𝐹𝑋 𝑥1 𝐴 𝑥1 𝑋 = 𝑃 𝐴 = 𝑥2 𝑃(𝐴) 𝐹𝑋 𝑥2 − 𝐹𝑋 𝑥1 𝑓𝑋 𝑥 𝑑𝑥 𝑥 1 12 • Let 𝑥1 = 𝑥 and 𝑥2 = 𝑥 + ∆𝑥, ∆𝑥 > 0, So lim 𝑃 𝐴|𝑥 < 𝑋 ≤ 𝑥 + ∆𝑥 = 𝑃 𝐴|𝑋 = 𝑥 ∆𝑥→0 𝑃 𝑥 < 𝑋 ≤ 𝑥 + ∆𝑥 𝐴 ∆𝑥 ⇒ 𝑃 𝐴|𝑋 = 𝑥 = ∆𝑥→0 𝑃(𝐴) 𝑃 𝑥 < 𝑋 ≤ 𝑥 + ∆𝑥 lim ∆𝑥 ∆𝑥→0 𝑓𝑋 𝑥 𝐴 𝑃 𝐴|𝑋 = 𝑥 = 𝑃(𝐴) 𝑓𝑋 𝑥 lim • Or 𝑃 𝐴|𝑋 = 𝑥 𝑓𝑋 𝑥 𝑓𝑋 𝑥 𝐴 = 𝑃(𝐴) 13 Continuous version of Total probability Theorem • 𝑃(𝐴)𝑓𝑋 𝑥 𝐴 = 𝑃 𝐴|𝑋 = 𝑥 𝑓𝑋 𝑥 • 𝑃(𝐴) ∞ 𝑓 −∞ 𝑋 𝐹𝑋 𝑥 𝐴 𝑑𝑥 = ∞𝐴 ∞ { 𝑃 𝐴|𝑋 −∞ = =1 14 Continuous version of Bayes’ Theorem • 𝑓𝑋 𝑥 𝐴 = 𝑃 𝐴|𝑋=𝑥 𝑓𝑋 𝑥 𝑃(𝐴) ⟹ 𝑓𝑋 𝑥 𝐴 = 𝑃 𝐴|𝑋 = 𝑥 𝑓𝑋 𝑥 ∞ 𝑃 −∞ 𝐴|𝑋 = 𝑥 𝑓𝑋 𝑥 𝑑𝑥 15 A posteriori and a priori pdf s relation • Note: We can use the conditional pdf together with the Bayes’ theorem to update our a-priori knowledge about the probability of events in presence of new observations. Ideally, any new information should be used to update our knowledge. As we see in the next example, conditional pdf together with Bayes’ theorem allow systematic updating. 16 Example : Let 𝑝 = 𝑃 𝐻 represent the probability of obtaining a head in a toss. For a given coin, a-priori 𝑝 can possess any value in the interval (0,1). In the absence of any additional information, we may assume the a-priori pdf 𝑓𝑝 (𝑝) to be a uniform distribution in that interval. Now suppose we actually perform an experiment of tossing the coin 𝑛 times, and 𝑘 heads are observed. This is new information. How can we update 𝑓𝑝 (𝑝)? Solution: Let 𝐴 = {“𝑘 ℎ𝑒𝑎𝑑𝑠 𝑖𝑛 𝑛 𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐 𝑡𝑜𝑠𝑠𝑒𝑠”}. Since these tosses result in a specific sequence, f P ( p) P( A | P p ) p k q n k , 0 1 p 17 From Total probability theorem: 1 𝑃 𝐴 = 1 𝑝𝑘 𝑃 𝐴 𝑃 = 𝑝 𝑓𝑃 𝑝 𝑑𝑝 = 0 0 1−𝑝 𝑛−𝑘 𝑑𝑝 𝑛 − 𝑘 ! 𝑘! = 𝑛+1 ! The a-posteriori pdf 𝑓𝑃 (𝑝|𝐴) represents the updated information given the event A, 𝑃(𝐴|𝑃 = 𝑝)𝑓𝑃 (𝑝) 𝑛 + 1 ! 𝑘 𝑛−𝑘 𝑓𝑃 𝑝 𝐴 = = 𝑝 𝑞 , 0 < 𝑝 < 1 ~𝛽(𝑛, 𝑘) 𝑃(𝐴) 𝑛 − 𝑘 ! 𝑘! f P ( p | A) 0 1 Notice that the a-posteriori pdf of 𝑝 in is not a uniform distribution, but a beta distribution. We can use this 𝑓𝑃 𝑝 𝐴 a-posteriori pdf to make further predictions, For example, in the light of the above experiment, what can we say about the probability of a head occurring in the next (𝑛 + 1)𝑡ℎ toss? 18 p • Let B= {“head occurring in the (𝑛 + 1)𝑡ℎ toss, given that k heads have occurred in n previous tosses”}. Clearly 𝑃 𝐵 𝑃 = 𝑝 = 𝑝 • 𝑃 𝐵 = 1 𝑃 0 𝐵 𝑃 = 𝑝 𝑓𝑃 𝑝|𝐴 𝑑𝑝 • Notice that we have used the a-posteriori pdf to reflect our knowledge about the experiment already performed. • 𝑃 𝐵 = 1 𝑛+1 ! 𝑘 𝑞 𝑛−𝑘 𝑑𝑝 𝑝 𝑝 0 𝑛−𝑘 !𝑘! = 𝑘+1 𝑛+2 • Thus, if 𝑛 = 10, and 𝑘 = 6, then • 𝑃 𝐵 = 7 12 = 0.58 which is more realistic compare to 𝑝 = 0.5. 19 Summary: If the probability of an event X is unknown, one should make noncommittal judgment about its a-priori probability density function 𝑓𝑋 (𝑥), usually the uniform distribution is a reasonable assumption in the absence of any other information. Then experimental results (𝐴) are obtained, and our knowledge about 𝑋 must be updated reflecting this new information. Bayes’ rule helps to obtain the a-posteriori pdf of 𝑋 given 𝐴. From that point on, this a-posteriori pdf 𝑓𝑋 (𝑥|𝐴) should be used to make further predictions and calculations. 20