Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
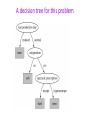
CES 514 – Data Mining Spring 2010 Sonoma State University Course Details: Instructor: Bala Ravikumar (Ravi) Email: [email protected], [email protected] Tel: (707) 664 3335 Office: Darwin Hall 116 I Course Web Page http://ravi.cs.sonoma.edu/~ravi/ces514sp10 Lecture time: 6 to 8:45 PM, Wednesdays Room: Salazar Hall 2003 Office hours: M 9 – 10, T 11 – 12, W 5 – 6 Prerequisites basic probability and statistics (probability distribution, random variable, conditional probability etc.) algorithms and data structures (sorting, hashing, binary trees, algorithm design techniques) Programming in high-level language (Java, Python, Matlab, c#, …) Linear algebra (vectors, linear independence, matrix rank, Gaussian elimination etc.) These topics will be reviewed. However, it will be helpful to spend some time on your own to familiarize yourself. Text book Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008. This book’s focus is on WEB DATA MINING Web site for the text: http://nlp.stanford.edu/IR-book/information-retrieval-book.html Additional references Mining the Web, S.Chakrabarti, MKP. Data Mining, Witten and Frank, MKP. The elements of statistical learning, Hastie, Tibshirani, and Friedman, Springer-Verlag. Web Data Mining: Exploring Hyperlinks, Contents and Usage data, Bing Liu, Springer-Verlag. Introduction to Data Mining, Pang-Ning Tan, Michael Steinbach, and Vipin Kumar, Pearson/Addison Wesley. Overlapping fields Statistics Artificial intelligence (machine learning) Data base and Information retrieval Natural language processing Algorithm design and analysis Grading Quiz: 10% Home Work: 25 % Midterm: 15% One mid-term, in-class, open book/notes? Final Exam: 25% In-class or take-home? Project: 25% Individual, design and implementation Example Projects from Fall 2005 and 2007 Strategy for predicting the winner in a game similar to Jai Alai. Hand-written character recognition classify the type of disease based on some test results classification of e-mail (junk vs. useful, personal vs. business vs. family etc.) classification of questions in a multiple choice test based on the responses of students identifying the author from a sample text implement an association rule mining algorithm implement a visualization algorithm that provides various options for viewing the data classifying mushroom into edible and poisonous based on a number of attributes – such as color, length of the stem, width etc. classifying web site based on content Project is done individually, and is semester long - implement, test, write a paper, present in class. Today’s lecture Overview of the course Chapter 1 of the text Overview of Topics Web data organization Web search Classification (supervised learning) Clustering (unsupervised learning) Association rule mining Language models for information retrieval Vector space models SVM and other tools LSI and tools from linear algebra Link analysis Other applications – e.g. bioinformatics What is data mining? Data mining is also called knowledge discovery Data mining is extraction of useful patterns from data sources, e.g., databases, texts, web, images, etc. Patterns must be: valid, novel, potentially useful, understandable Our focus will be on text data (in particular web) Some sample problems in Data Mining Extract useful knowledge from the vast data and information available on the web. (e.g. tagging of web sites, labeling images, predict the needs of a web surfer from pattern of clicks.) Using the financial record of a person, determine the risk involved in giving a loan. (decision could be yes or no. more generally, it could be the type of loan – interest rate, duration etc.) movie (book etc.) recommendation based on prior choices. prediction of weather, traffic pattern, outcome of an event etc. From the items recorded in the check-out counter of a super market, determine any correlation between items being sold. (used to decide which ones to put on sale.) study and understand of social networks. rank web page according to significance. Classic data mining tasks Classification mining patterns that can classify future (new) data into known classes. Association rule mining mining any rule of the form X Y, where X and Y are sets of data items. Clustering identifying similar groups in the data Regression analysis Classic data mining tasks (contd) Sequential pattern mining: A sequential rule: A B, says that event A will be immediately followed by event B with a certain confidence Deviation detection: discovering the most significant changes in data Data visualization: using graphical methods to show patterns in data. Why is data mining important? Computerization of businesses produce huge amount of data How to make best use of data? Knowledge discovered from data can be used for competitive advantage. Online businesses generate even larger data sets Online retailers (e.g., amazon.com) are largely driven by data mining. Web search engines are information retrieval and data mining companies Why is data mining necessary? Make use of your data assets There is a big gap from stored data to knowledge; and the transition won’t occur automatically. Many interesting things you want to find cannot be found using database queries “find me people likely to buy my products” “Who are likely to respond to my promotion?” “Which movies should be recommended to each customer?” Why data mining now? The data is abundant. The computing power is not an issue. Data mining tools are available The competitive pressure is very strong. Almost every company is doing (or has to do) it Socio-political exigencies Detecting terrorism activities New technologies Streaming data, mobile computing, wireless networks Related fields Data mining is an multi-disciplinary field: Machine learning/artificial intelligence Statistics Databases Information retrieval Visualization Natural language processing Game theory etc. Data mining applications Marketing: customer profiling and retention, identifying potential customers, market segmentation. Engineering: identify causes of problems in products. Scientific data analysis: weather prediction, financial data analysis, image analysis etc. Fraud detection: identifying credit card fraud, intrusion detection. Text and web: a huge number of applications … Bioinformatics: structure prediction, classification, microarray analysis etc. Any application that involves a large amount of data … Structural descriptions Example: if-then rules If tear production rate = reduced then recommendation = none Otherwise, if age = young and astigmatic = no then recommendation = soft Age Spectacle prescription Astigmatism Tear production rate Recommended lenses Young Myope No Reduced None Young Hypermetrope No Normal Soft Prepresbyopic Hypermetrope No Reduced None Presbyopic Myope Yes Normal Hard … … … … … Classification vs. association rules Classification rule: predicts value of a given attribute (the classification of an example) If outlook = sunny and humidity = high then play = no Association rule: predicts value of arbitrary attribute (or combination) If temperature = cool then humidity = normal If humidity = normal and windy = false then play = yes If outlook = sunny and play = no then humidity = high If windy = false and play = no then outlook = sunny and humidity = high A decision tree for this problem Predicting CPU performance Example: 209 different computer configurations Cycle time (ns) Main memory (Kb) Cache (Kb) Channels Performance MYCT MMIN MMAX CACH CHMIN CHMAX PRP 1 125 256 6000 256 16 128 198 2 29 8000 32000 32 8 32 269 208 480 512 8000 32 0 0 67 209 480 1000 4000 0 0 0 45 … Linear regression function PRP = -55.9 + 0.0489 MYCT + 0.0153 MMIN + 0.0056 MMAX + 0.6410 CACH - 0.2700 CHMIN + 1.480 CHMAX Spam filter software Given below are the % of occurrences of a few select words in spam and genuine e-mail messages: A decision list may be used to identify spam. Text mining Data mining on text Due to a huge amount of online texts on the Web and other sources Text contains a huge amount of information of any imaginable type! A major direction and tremendous opportunity! Main topics Text classification and clustering Information retrieval Information extraction Opinion mining and summarization Example: Opinion Mining The Web has dramatically changed the way that people express their opinions. One can post their opinions on almost anything at review sites, Internet forums, discussion groups, blogs, etc. Product reviews Benefits of Review Analysis Potential Customer: No need to read many reviews Product manufacturer: market intelligence, product benchmarking Feature Based Analysis & Summarization Extracting product features (called Opinion Features) that have been commented on by customers. Identifying opinion sentences in each review and deciding whether each opinion sentence is positive or negative. Summarizing and comparing results. An example GREAT Camera., Jun 3, 2004 Reviewer: jprice174 from Atlanta, Ga. I did a lot of research last year before I bought this camera... It kinda hurt to leave behind my beloved nikon 35mm SLR, but I was going to Italy, and I needed something smaller, and digital. The pictures coming out of this camera are amazing. The 'auto' feature takes great pictures most of the time. And with digital, you're not wasting film if the picture doesn't come out. … …. Summary: Feature1: picture Positive: 12 The pictures coming out of this camera are amazing. Overall this is a good camera with a really good picture clarity. .... Negative: 2 The pictures come out hazy if your hands shake even for a moment during the entire process of taking a picture. Focusing on a display rack about 20 feet away in a brightly lit room during day time, pictures produced by this camera were blurry and in a shade of orange. Feature2: battery life Visual Comparison Summary of reviews of Digital camera 1 + _ Picture Comparison of reviews of + Digital camera 1 Digital camera 2 _ Battery Zoom Size Weight Information retrieval – Ch 1 Boolean query Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers). Sec. 1.1 Unstructured data in 1680 Which plays of Shakespeare contain the words Brutus AND Caesar but NOT Calpurnia? One could grep all of Shakespeare’s plays for Brutus and Caesar, then strip out lines containing Calpurnia? Why is that not the answer? Slow (for large corpora) NOT Calpurnia is non-trivial Other operations (e.g., find the word Romans near countrymen) not feasible Ranked retrieval (best documents to return) Later lectures 31 Sec. 1.1 Term-document incidence Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 1 1 0 0 0 1 Brutus 1 1 0 1 0 0 Caesar 1 1 0 1 1 1 Calpurnia 0 1 0 0 0 0 Cleopatra 1 0 0 0 0 0 mercy 1 0 1 1 1 1 worser 1 0 1 1 1 0 Brutus AND Caesar BUT NOT Calpurnia 1 if play contains word, 0 otherwise Sec. 1.1 Incidence vectors So we have a 0/1 vector for each term. To answer query: take the vectors for Brutus, Caesar and Calpurnia (complemented) bitwise AND. 110100 AND 110111 AND 101111 = 100100. 33