Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
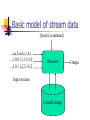
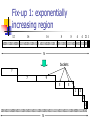
A survey on stream data mining Roadmap The basic model of the stream data mining Counting bit problem Counting distinct element Basic idea Exponentially increasing region DGIM method Flajolet-Martin approach Calculating how “uneven” the elements in the stream are The idea of “moment” and AMS method Basic model of stream data Data input rapidly The system cannot store entire data Queries tend to ask information about recent data The scan never “turn back” Basic model of stream data Queries (command) …,a,a,b,a,d,c,c,b,c …,1,0,0,1,1,1,0,1,0 …,3,0,1,1,2,3,1,0,2 Processor Input streams Limited storage Output Applications Is there any telephone calls from a certain department of the company to the other department in the past 5 minutes? Which channels are the most popular ones in the past 30 minutes? The answers to this kind of queries are varied over time Sliding windows A mechanism that stores the most recent N elements of the stream N: window size N may be too large to store the entire stream in the system Window size: N Timestamps 7 6 5 4 3 2 1 Arrival time 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 1 0 1 0 1 1 0 0 0 1 0 1 0 1 0 1 1 0 1 0 1 1 1 1 1 0 Elements N Counting bit problem How many 1s in the recent k bits? (given that a stream contains only 0s and 1s) Stores the latest N bits (when N>=k) Advantage: accurate answer Drawback: Storage space (when N is too small or k is too large…) Response time? Fix-up 1: exponentially increasing region 32 16 16 8 8 4 4 211 1001010110001011010101010101011010101010101110101010111010100010110010 N buckets ? 7 9 5 5 1 3 0 10 1001010110001011010101010101011010101010101110101010111010100010110010 N Bucket update 32 32 16 8 4 4 2 1 1 32 32 16 8 4 4 2 1 1 1 32 32 16 8 4 4 2 2 1 32 32 16 8 4 4 2 2 1 1 32 32 16 8 4 4 2 2 1 1 1 32 32 16 8 4 4 2 2 2 1 32 32 16 8 4 4 4 2 1 32 32 16 8 8 4 2 1 •http://vc.cs.nthu.edu.tw/ezLMS/show.php?id=246 •http://vc.cs.nthu.edu.tw/ezLMS/show.php?id=252 Fix-up 2: DGIM* method Representing buckets The error of the last part is smaller Update method is similar At least 1 of size 16. Partially beyond window. 2 buckets of size 8 2 buckets 1 bucket 2 buckets of size 4 of size 2 of size 1 1001010110001011010101010101011010101010101110101010111010100010110010 N *: Datar, Gionis, Indyk, and Motwani Counting distinct elements How many different web pages does a customer request last week? How many different channels does a customer watch yesterday? What if we don’t have enough space to store the complete set? Flajolet-Martin approach (1/4) A probabilistic counting algorithm Used to estimate number of distinct elements in a large file originally Use little memory Single pass only Based on statistical observation made on bits of hashed values Flajolet-Martin approach (2/4) Hash function h: map n elements to log2n bits uniformly bit(y, k) = kth bit in the binary representation of y y bit ( y, k ) 2 ( y ) min [bit ( y, k )] 0 if y>0 k 0 ( y ) L if y=0 k k 0 Flajolet-Martin approach (3/4) for (i:=0 to L-1) do BITMAP[i]:=0; for (all x in M) do begin index:=ρ(h(x)); if BITMAP[index]=0 then BITMAP[index]:=1; end R := the largest index in BITMAP whose value equals to 1 Estimate := 2R Flajolet-Martin approach (4/4) If the final BITMAP looks like this: 0000,0000,1100,1111,1111,1111 The left most 1 appears at position 15 We say there are around 215 distinct elements in the stream Moment Let mi be the number of times value i occurs in a stream The kth moment is the sum of (mi)k for all i 0th moment: the problem we just considered 1st moment: length of the stream 2nd moment: measure how uneven the distribution is (surprise number) 5,5,5,5,5 surprise number = 125 9,9,5,1,1 surprise number = 189 AMS* method Works for all moments Ex: (stream length n ,2nd moment: ) X=n*((twice the number of as in the stream starting at the chosen time) – 1) E(X)=(1/n)*(Σall times t of n*(twice the number of times the stream element at time t appears from that time on)-1) =Σa (1/n)(n)(1+3+5+…+2ma-1) =Σa(ma)2 (= the 2nd moment) Compute as many variables X as can fit in available memory *: Alon, Matias, and Szegedy Conclusion Under stream data model… Basic counting (0s and 1s only) Fix-ups to basic counting Exponentially increasing region DGIM method Distinct element counting How “uneven” of the distribution Discussion There seems no arbitrary token counting algorithm under stream data mining model yet… References Data mining course in Stanford: http://www.stanford.edu/class/cs345a/ Stanford InfoLab hompage: http://www-db.stanford.edu/ Maintaining stream statistics over sliding windows, ACM SIAM Journal on Computing 2002 Maintaining variance and k-medians over data stream windows, ACM PODS 2003 Probabilistic counting algorithms for data base applications, Journal of Computer and System Sciences 1985 The space complexity of approximating the frequency moments, ACM Symposium on Theory of Computing 1996