Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Mining: A Database
Perspective
Raghu Ramakrishnan
Univ. of Wisconsin-Madison
1
Data Mining
Classification
ML/AI
DB
Clustering
K-means
Hierarchical methods
EM
Stats
MRDM/ILP pattern discovery
Optimization
Associations, sequential patterns
Time-series analysis
Horn rules; PRMs
Frequent item analysis
THE EDAM PROJECT
Decision trees
Regression
SVMs
Naïve Bayes
Meta-learners, ensembles
Linear and nonlinear dynamics
Collaborative filtering
Text, multimedia mining
University of Wisconsin-Madison
2
Mining at a Crossroads
Data Mining has drawn upon ideas and people
from many disciplines, and has grown rapidly.
As yet, no unifying vision of how these
disciplines leverage each other.
Stats
folks still do stats, ML folks still do ML, DB folks
still think about large datasets—and they rarely talk
amongst each other.
What are the applications that will pay the
piper?
THE EDAM PROJECT
University of Wisconsin-Madison
3
About this Talk
A database perspective on data mining and
its relationship to data management
How
can database-oriented thinking influence
research and practice in data mining?
What are the difficult problems with big payoffs?
The EDAM project at Wisconsin
Analyzing
streams of mass spectra and other
spatio-temporal data
Joint work with researchers in atmospheric
aerosols and climatology at UW-Madison and
Carleton College, funded by an NSF ITR
THE EDAM PROJECT
University of Wisconsin-Madison
4
Outline
A Database perspective
Recent extensions to relational systems
OLAP:
Cube, sequence queries
Data mining support
Relational approaches to mining
Relational
clustering
MRDM/ILP
The EDAM project
THE EDAM PROJECT
University of Wisconsin-Madison
5
A Database Perspective
THE EDAM PROJECT
University of Wisconsin-Madison
6
All the World’s a Table
All data is in a database.
If
not, it’s not important
Data mining is a class of analysis techniques
that complements current SQL data analysis
capabilities.
Data
is in a DBMS for reasons that go well beyond
the analysis capabilities of the DBMS, even if these
are often inadequate.
And if the past is any indication, the DB vendors
will try to expand SQL to support whatever DM
capabilities the market will pay for—and it’s not
clear that this is the right architecture.
THE EDAM PROJECT
University of Wisconsin-Madison
7
Scalability
Widely recognized as a characteristic DB concern, and
that it provides useful techniques to deal with scale.
However, the focus has been on one aspect of scale:
BIRCH—Scalable pre-clustering that borrows ideas from B+
trees
Rainforest—Framework for scaling decision tree construction
that borrows from hash joins
(There are also scalable algorithms based on EM and
Bootstrapping)
Size of training data
We also need scalability with respect to other problem
dimensions:
Size of hypothesis space
Rate of data capture and analysis
THE EDAM PROJECT
University of Wisconsin-Madison
8
Queries vs. Mining
From the point of view of the user, SQL queries
are one way to explore and understand the
data.
But
is it “data mining”?
The various data mining techniques are no more (or
less) than alternatives with different capabilities.
The query framework has some ideas worth
borrowing and generalizing:
Compositionality—more
flexibility, more automation
Usability—domain analysts, not tool experts
Query Optimization
THE EDAM PROJECT
University of Wisconsin-Madison
9
A Different Mindset …
Sometimes, just looking at the problem from a different
perspective may lead to useful reformulations:
“What does a query mean?” vs. “How do I characterize
my data?”
Frequent itemsets
Relational clustering
Stream analysis
Labeling spectra
Subset mining
Hopefully, not mutually exclusive!
Can raise very different concerns
E.g., Coverage, accuracy (ML), confidence bounds (Stats) vs.
query equivalence, compositionality (DB)
Combining multiple sources of information (e.g., multiple tables)
THE EDAM PROJECT
University of Wisconsin-Madison
10
Query Optimization
Driven by user’s query
Goal
is to find answers to this query efficiently
Search space for optimization
Defined
through equivalences to given query
Exploits compositionality!
“Goodness”
metric is estimated plan cost
Contrast this with the search spaces typical in, e.g.,
rule discovery or attribute selection
THE EDAM PROJECT
These are data-driven, not query-driven
Search space based on hypothesis refinement
“Goodness” metric based on coverage of training set
University of Wisconsin-Madison
11
Data Management
Management
Data storage and archival
Privacy, sharing, collaboration
Focus has been on managing data; however:
Queries can be stored in the DBMS
Views, or tables defined by queries
(Ownership, access control, re-optimization,
caching)
We need more support for managing analyses:
Managing analyses external to the DBMS
Provenance of data and analysis
Versioning and collaboration support
Support
for ongoing analyses: Impact of data changes
on analyses; monitoring; trend analysis over
warehouses; deploying results into operational system
THE EDAM PROJECT
University of Wisconsin-Madison
12
Data Co-Processor Architecture
Queries/Searches
Miner
Periodic
offline activity
Indexer
Large R/W
Small reads
Files, Logs
Warehouse
DBMS
RAID STORAGE
THE EDAM PROJECT
University of Wisconsin-Madison
13
SQL
Queries
Updates
OLAP
Queries
Text
Queries
SYNC
CUSTOMIZED ASYNCHRONOUS REPLICAS
THE EDAM PROJECT
University of Wisconsin-Madison
14
Recent Extensions of
Relational Queries
THE EDAM PROJECT
University of Wisconsin-Madison
15
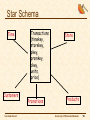
Star Schema
Time
Customers
THE EDAM PROJECT
Transactions
(timekey,
storekey,
pkey,
promkey,
ckey,
units,
price)
Promotions
Store
Products
University of Wisconsin-Madison
16
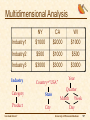
Multidimensional Analysis
NY
CA
WI
Industry1
$1000
$2000
$1000
Industry2
$500
$1000
$500
Industry3
$3000
$3000
$3000
Industry
Country=“USA”
Category
State
Product
City
THE EDAM PROJECT
Year
Quarter
Month
Week
Day
University of Wisconsin-Madison
17
Slice and Drill-Down
Category1
San
San Jose
Los
Francisco
Angeles
$300
$300
$400
Category2
$300
$300
$400
Category3
$100
$800
$100
Industry=“Industry3”
Country
Category
State=“CA”
Product
City
THE EDAM PROJECT
Year
Quarter
Month
Week
Day
University of Wisconsin-Madison
18
Comparison with SQL
SELECT SUM(S.sales)
FROM Sales S, Times T, Locations L
WHERE S.timeid=T.timeid AND S.timeid=L.timeid
GROUP BY T.year, L.city
SELECT SUM(S.sales)
FROM Sales S, Times T
WHERE S.timeid=T.timeid
GROUP BY T.year
THE EDAM PROJECT
SELECT SUM(S.sales)
FROM Sales S, Location L
WHERE S.timeid=L.timeid
GROUP BY L.city
University of Wisconsin-Madison
Visual Intuition: Cube
roll-up to category
roll-up to state
SH
SF
Product
LA
Product1
Product2
Product3
Product4
Product5
Product6
20
30
20
15
10
50
roll-up to week
M T W Th F S S
Time
50 Units of Product6 sold on Monday in LA
THE EDAM PROJECT
University of Wisconsin-Madison
20
CUBE Operator
For k dimensions, we have 2^k possible SQL
GROUP BY queries that can be generated
through pivoting on a subset of dimensions.
CUBE pid, locid, timeid BY SUM Sales
Equivalent
to rolling up Sales on all eight subsets
of the set {pid, locid, timeid}; each roll-up
corresponds to an SQL query of the form:
SELECT SUM(S.sales)
FROM Sales S
GROUP BY grouping-list
THE EDAM PROJECT
University of Wisconsin-Madison
Observation
When you need to consider several
related or overlapping computations
Think
of how to expose this space to the
user, and to get user input on what part of
the space might be interesting
Marketing
specialists can use OLAP interfaces to
do very complex queries easily
Think
of how to optimize by exploiting
commonality across computations
THE EDAM PROJECT
University of Wisconsin-Madison
22
Querying Sequences
SQL-92 supports queries over relations.
A relation
is a (multi) set of records.
No ordering of records in a relation!
Queries involving order are hard or impossible to
express, and typically, inefficiently evaluated.
Find
weekly moving average of the DJIA.
Compute % change of each stock during ‘97, and then
find stocks in the top 5% (those that changed most).
SQL:1999 supports the concept of windowing,
which effectively orders tuples for query
purposes.
THE EDAM PROJECT
University of Wisconsin-Madison
SRQL
(Ramakrishnan et al., SSDBM 98)
Proposed a sequencing operator as an
extension to relational algebra.
Applied to a table R,
with grouping attrs g
and sequencing attrs
s, it returns the
corresponding
composite
sequence.
THE EDAM PROJECT
g
s
v
ord
g
s
v
3
4
a
1
3
4
a
3
6
b
2
3
6
b
3
6
c
2
3
6
c
3
9
b
3
3
9
b
2
1
a
1
2
1
a
4
3
d
1
4
3
d
University of Wisconsin-Madison
Example
SELECT product, day, AVG(vol) OVER 0 TO 1
FROM Sales
GROUP BY product
SEQUENCE BY day
Find the 2-day moving average of volume sold
for each product:
In
effect, creates a sequence by day for each product,
and computes the moving average over each of these
sequences.
Observe how this generalizes SQL’s GROUP BY:
illustrates power of composite sequences and
aggregation.
THE EDAM PROJECT
University of Wisconsin-Madison
Variants of Aggregation
We can now introduce “running sum” and
other cumulative aggregate functions!
FIRST TO 0: This gives us “running”
or “cumulative” aggregates.
RANK() is CUMULATIVE COUNT(*)
PERCENTILE() is (RANK()/COUNT(*))*100
OVER
Elegant way to express concepts like
“give me the first few answers”.
SQL:1999 does all this and more (different syntax)
THE EDAM PROJECT
University of Wisconsin-Madison
Observation
Still much more limited than time-series
analysis and mining techniques available
elsewhere
No support for streams
THE EDAM PROJECT
University of Wisconsin-Madison
27
DBMS Support for Managing
Mining Models
THE EDAM PROJECT
University of Wisconsin-Madison
28
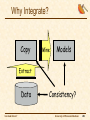
Why Integrate?
Copy
Mine
Models
Extract
Data
THE EDAM PROJECT
Consistency?
University of Wisconsin-Madison
29
Integration Objectives
Avoid isolation of
querying from mining
Difficult
to do “ad-hoc”
mining
Provide simple
programming
approach to creating
and using DM
models
Analysts (users)
THE EDAM PROJECT
Make it possible to
add new models
Make it possible to
add new, scalable
algorithms
DM Vendors
University of Wisconsin-Madison
30
DM Concepts to Support
Representation of input (cases)
Representation of models
Specification of training step
Specification of prediction step
Should be independent of specific algorithms
THE EDAM PROJECT
University of Wisconsin-Madison
31
Types of Columns
Cust
ID
Age
1
35
Single case!
Product Purchases
Marital
Wealth Produc
Status
Quantity
Type
t
M
380,00
0
TV
Coke
Ham a case
Keys: Columns that uniquely identify
Attributes: Columns that describe a case
6
Drink
3
Food
Value: A state associated with the attribute in a specific case
Attribute Property: Columns that describe an attribute
1 Applianc
e
Unique for a specific attribute value (TV is always an appliance)
Attribute Modifier: Columns that represent additional “meta”
information for an attribute
THE EDAM PROJECT
Weight of a case, Certainty of prediction
University of Wisconsin-Madison
32
Representing a DMM
Specifying a Model
Columns
it should predict
Algorithm to use
Special parameters
Model is represented as a nested table
Specification
= Create table
Training = Inserting data into the table
Predicting = Querying the table
THE EDAM PROJECT
University of Wisconsin-Madison
33
Training a DMM
Training a DMM requires passing it “known” cases
Use an INSERT INTO in order to “insert” the data
to the DMM
The
DMM will usually not retain the inserted data
Instead it will analyze the given cases and build the
DMM content (decision tree, segmentation model)
INSERT
[INTO] <mining model name>
[(columns list)]
<source data query>
THE EDAM PROJECT
University of Wisconsin-Madison
34
Making Predictions
SELECT [Customers].[ID],
MyDMM.[Hair Color],
PredictProbability(MyDMM.[Hair Color])
FROM
MyDMM PREDICTION JOIN [Customers]
ON MyDMM.[Gender] = [Customers].[Gender] AND
MyDMM.[Age] = [Customers].[Age]
THE EDAM PROJECT
University of Wisconsin-Madison
35
Research Directions
MRDM/ILP
THE EDAM PROJECT
University of Wisconsin-Madison
36
MRDM Accomplishments
ILP origins, hypothesis discovery
Classification
Clustering
Frequent itemsets
Equational discovery
Subgroup discovery
Extensions of Bayesian nets to multiple
relations via key-foreign key traversals
THE EDAM PROJECT
University of Wisconsin-Madison
37
Issues
Can we indeed capture the semantics
exactly for each of these classes of
patterns/models?
Taking
into account the details of the
underlying evaluation algorithm!
Is the performance comparable to
specialized algorithms? Is it acceptable
for a broad range of applications?
THE EDAM PROJECT
University of Wisconsin-Madison
38
Positives
Impressive! Quite a range of patterns/models are
shown to be expressible in this formalism
Importantly,
the added expressiveness allows new kinds
of patterns to be naturally formulated by a user
There is a (more or less) common computational
structure consisting of
Space
of patterns to search
Measure of support for a pattern
Enumeration and pruning strategy over search space
What tangible benefits can we derive from this generality?
THE EDAM PROJECT
University of Wisconsin-Madison
39
Challenges, Opportunities
If ILP notation is roughly analogous to relational
calculus, what is the appropriate algebra?
Equivalences,
compositionality
Cost-based optimization to find “optimal” evaluation
plans
What kind of user input/domain knowledge can
be used to focus computation, or help with
optimization?
THE EDAM PROJECT
University of Wisconsin-Madison
40
Research Directions
Relational Clustering
THE EDAM PROJECT
University of Wisconsin-Madison
41
Problem Statement
Goal: Discover clusters of attribute-values
Data: A table T with attributes drawn from domains
D1,…,Dn
A
B
C
Note: We expect
sizes of D1,…,Dn to
be small
a1
b1
a2
a3
a4
b2
b3
c1
c2
c3
c4
Thus,
a tuple of T consists of a value from each domain,
e.g., (a1,b2,c1)
T could be an arbitrary view over several tables!
THE EDAM PROJECT
University of Wisconsin-Madison
42
STIRR
(Gibson, Kleinberg, Raghavan, VLDB 98)
Intuition: Want to detect that “Honda and Toyota
are related because unusually high numbers of
both were sold in August.”
If
we also find that many Hondas and Nissans are
sold in Sept, and many dealers sell both Hondas and
Acuras, this leads to a cluster best described as “latesummer sales of Japanese cars”
Approach: Techniques for spectral graph
partitioning, generalized to hypergraphs.
Attribute
values as weighted vertices in a graph;
edges based on co-occurrence. Weights propagate
along links, leading to a non-linear dynamical system.
THE EDAM PROJECT
University of Wisconsin-Madison
43
CACTUS
(Ganti, Gehrke, Ramakrishnan, KDD 99)
Same motivation, different problem
formulation and approach
Precise definition of cluster, deterministic
algorithm that computes all clusters
Very efficient, scalable, SQL-based
algorithm
THE EDAM PROJECT
University of Wisconsin-Madison
44
Similarity Between Attributes
A
B
a1
b1
a2
a3
b2
b3
a4
b4
C
c1
c2
c3
c4
Not strongly connected
THE EDAM PROJECT
“similarity’’ between a1 and b1
support(a1,b1) = number of tuples
containing (a1,b1)
a1 and b1 are strongly connected
if support(a1,b1) is higher than expected
{a1,a2,a3,a4} and {b1,b2} are strongly
connected if all pairs are
University of Wisconsin-Madison
45
Similarity Within an Attribute
simA(b1,b2): Number of values of A which are
strongly connected with both b1 and b2
A
B
a1
b1
a2
a3
a4
b2
b3
b4
THE EDAM PROJECT
C
c1
c2
c3
c4
sim*(B)
(b1,b2)
(b1,b3)
(b1,b4)
(b2,b3)
(b2,b4)
thru A
thru C
4
0
0
0
0
University of Wisconsin-Madison
2
2
0
2
0
46
Cluster Definition
Region: A cross-product of sets of
attribute values: C1 x … x Cn
C=C1 x … x Cn is a cluster iff
1.
2.
3.
Ci and Cj are strongly connected, for all i,j
Ci is maximal, for all i
Support(C) > expected
Ci: cluster projection of C on Ai
THE EDAM PROJECT
University of Wisconsin-Madison
47
The CACTUS Algorithm
Summarize
Inter-attribute
summaries: Scan dataset
Intra-attribute summaries: Query IA
summaries
Clustering phase
Compute
cluster projections
Level-wise synthesis of cluster projections to
form candidate clusters
Validation
Requires
THE EDAM PROJECT
a scan of the dataset
University of Wisconsin-Madison
48
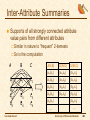
Inter-Attribute Summaries
Supports of all strongly connected attribute
value pairs from different attributes
Similar
in nature to “frequent’’ 2-itemsets
So is the computation
A
B
a1
b1
a2
a3
a4
b2
b3
b4
THE EDAM PROJECT
C
c1
c2
c3
c4
IJ(A,B)
IJ(A,C)
IJ(B,C)
(a1,b1)
(a1,c1)
(b1,c1)
(a1,b2)
(a1,c2)
(b1,c2)
(a2,b1)
(a2,c1)
(b2,c1)
(a2,b2)
(a2,c2)
(b2,c2)
(a3,b1)
(b3,c1)
…
…
University of Wisconsin-Madison
49
Intra-Attribute Summaries
simA(B): Similarities through A of attribute
value pairs of B
A
B
a1
b1
a2
a3
a4
b2
b3
b4
THE EDAM PROJECT
C
c1
c2
c3
c4
sim*(B)
(b1,b2)
(b1,b3)
(b1,b4)
(b2,b3)
(b2,b4)
thru A
thru C
4
0
0
0
0
University of Wisconsin-Madison
2
2
0
2
0
50
Experimental Evaluation
Compare CACTUS with STIRR [GKR98]
Synthetic datasets
Quasi-random
data [GKR98:STIRR]
Fix domain of each attribute
Randomly generate tuples from these
domains
Identify clusters and plant additional (5%)
data within the clusters
THE EDAM PROJECT
University of Wisconsin-Madison
51
Synthetic Datasets
{0,…9} x {0,…9}
{10,…,19} x {10,…,19}
0
9
10
Both CACTUS and STIRR identified
the two clusters exactly
19
20
…
99
THE EDAM PROJECT
University of Wisconsin-Madison
52
Synthetic Dataset (contd.)
{0,…,9} x {0,…,9} x {0,…,9}
{10,…,19} x {10,…,19} x {10,…,19}
{0,…,9} x {10,…,19} x {10,…,19}
0
9
10
19
20
…
Cactus identifies the 3 clusters
STIRR returns:
{0,…,9} x {0,…,19} x {0,…,9}
{10,…,19} x {0,…,19} x {10,…,19}
99
THE EDAM PROJECT
University of Wisconsin-Madison
53
Scalability with #Tuples
Time vs. #Tuples
Time (in seconds)
2500
2000
1500
1000
500
0
1
2
3
4
5
#Tuples (in millions)
CACTUS
STIRR
CACTUS is 10 times faster
THE EDAM PROJECT
#Attributes: 10
Domain Size: 100
University of Wisconsin-Madison
54
Scalability with #Attributes
Time vs. #Attributes
5000
4500
Time (in seconds)
4000
3500
3000
2500
2000
1500
1000
500
0
4
THE EDAM PROJECT
6
8
10
20
30
#Attributes
CACTUS
STIRR
40
50
1 million tuples
Domain size: 100
University of Wisconsin-Madison
55
Scalability with Domain Size
Time vs. Domain Size
Time (in seconds)
250
200
150
100
50
0
50
100
200
400
600
800
1000
#Attribute Values
CACTUS
THE EDAM PROJECT
STIRR
1 million tuples
#attributes: 4
University of Wisconsin-Madison
56
Bibliographic Data
Database and theory bibliographic entries
[Wie]—38500 entries
Attributes: first author, second author,
conference/journal, and year
Example cluster projections on the
conference attribute:
(1). ACM Sigmod, VLDB, ACM TODS, ICDE, ACM Sigmod Record
(2). ACMTG, CompGeom, FOCS, Geometry, ICALP, IPL, JCSS, …
(3). PODS, Algorithmica, FOCS, ICALP, INFCTRL, IPL, JCSS, …
THE EDAM PROJECT
University of Wisconsin-Madison
57
ROCK
(Guha, Rastogi, Shim, ICDE 99)
Each tuple is a node, and two nodes are
linked if within a threshold distance.
Similarity between two nodes is the
number of common neighbors.
ROCK does agglomerative hierarchical
clustering based on similarity.
THE EDAM PROJECT
University of Wisconsin-Madison
58
Research Directions
The EDAM Project
THE EDAM PROJECT
University of Wisconsin-Madison
59
Example Tasks
Label a spectrum to identify elements
Find common elements across (subsets of) spectra
Collected at multiple locations, and multiple conditions, and …
At different times, and over time periods
Find subsets of spectra (e.g., based on time periods
and locations) with
Unusually common elements
Interesting characteristics
Correlations to other spectral streams
Want to be able to reconstruct analysis done a year ago
and run it on different data
Want to share ongoing analysis with colleagues and
track changes and their impact
THE EDAM PROJECT
University of Wisconsin-Madison
60
[Slides omitted from this version]
THE EDAM PROJECT
University of Wisconsin-Madison
61
Conclusions
Database systems hold a lot of the data people
care about and want to mine, making them an
important part of the mining environment
Especially
for ongoing analysis and collaboration
Beyond this, there are a number of ideas and
techniques in the DB literature that can be
applied more broadly
Formulations
Algorithms
of mining tasks
Scalability is an important idea from databases
But
there are many more—compositionality, querydriven approach, set-oriented analyses
THE EDAM PROJECT
University of Wisconsin-Madison
62