Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Simulation Output
Analysis
Summary
Examples
Parameter Estimation
Sample Mean and Variance
Point and Interval Estimation
Terminating and Non-Terminating Simulation
Mean Square Errors
Example: Single Server Queueing System
S4
x(t)
S3
S1
1
S4
S3
S2
2
3
4
5
6
S5
S7
S4
7
8
S5
9
S6
10 11
12
S7
13
14
Average System Time
Let Sk be the time that customer k spends in the queue, then,
t
Example: Single Server Queueing System
x(t)
T0
T0
T1
1
2
3
4
5
2T2
6
7
T1
2T2
8
9
T1
T1
10 11
2T2
12
Let T(i) be the total observed time during which x(t)= i
Average queue length
Utilization
T1
13
Probability that x(t)= i
T1
2T2
3T3
14
t
Parameter Estimation
Let X1,…,Xn be independent identically distributed random
variables with mean θ and variance σ2.
In general, θ and σ2 are unknown deterministic quantities
which we would like to estimate.
Sample Mean:
Τhe sample mean can be used as an estimate of the
unknown parameter θ. It has the same mean but less
variance than Xi.
Estimator Properties
Unbiasedness:
An estimator ˆn is said to be an unbiased estimator of
the parameter θ if it satisfies
Bias:
In general, an estimator is said to be an biased since
the following holds
where bn is the bias of the estimator
If X1,…,Xn are iid with mean θ, then the sample mean is
an unbiased estimator of θ.
Estimator Properties
Asymptotic Unbiasedness:
An estimator ˆn is said to be an asymptotically
unbiased if it satisfies
Strong Consistency:
An estimator is strongly consistent if with probability 1
If X1,…,Xn are iid with mean θ, then the sample mean is
also strongly consistent.
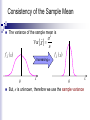
Consistency of the Sample Mean
The variance of the sample mean is
Var Xˆ
f X̂ x
n
Increasing n
θ
2
x
f X̂ x
θ
But, σ is unknown, therefore we use the sample variance
x
Recursive Form of Sample Mean and
Variance
Let Mj and Sj be the sample mean and variance after the
j-th sample is observed.
Also, let M0=S0=0.
j
j
Xi M j
2
Xi
Sj
Mj
j 1
i 1
i 1 j
The recursive form for generating Mj+1 and Sj+1 is
j
X j 1
Xi
M j 1 M j
Mj
j 1 i 1 j 1
Mj
X j 1 M j
j 1
S j 1
2
j 1
M
M
S j j 1 j 1
j
j
Example: Let Xi be a sequence of iid exponentially
distributed random variables with rate λ= 0.5 (sample.m).
Interval Estimation and Confidence
Intervals
Suppose that the estimator ˆ 1 then, the natural
question is how confident are we that the true parameter θ
is within the interval (θ1-ε, θ1+ε)?
Recall the central limit theorem and let a new random
variable
For the sample mean case Z n
ˆn
2 /n
Then, the cdf of Zn approaches the standard normal
distribution N(0,1) given by
1 x r2 / 2
x
e
dr
2
Interval Estimation and Confidence
Intervals
Let Z be a standard normal random variable, then
fZ(x)
Za / 2
0
Za / 2
x
Pr Z Za / 2 Pr Za / 2 Z Za / 2 1 a
Thus, as n increases, Zn density approaches the
standard normal density function, thus
Pr Za / 2 Zn Za / 2 1 a
Interval Estimation and Confidence
Intervals
fZ(x)
Substituting for Zn
ˆn
Pr Z a / 2
Za / 2 1 a
2
/n
Za / 2
0
Za / 2
x
Pr ˆn Za / 2 2 / n ˆn Za / 2 2 / n 1 a
Thus, for n large, this defines the interval where θ lies with
probability 1-a and the following quantities are needed
ˆ
The sample mean
n
The value of Za/2 which can be obtained from tables given a
The variance of ˆn which is unknown and so the sample variance is
used.
Example
Suppose that X1, …, Xn are iid exponentially distributed
random variables with rate λ=2. Estimate their sample
mean as well as the 95% confidence interval.
SOLUTION
n
1
The sample mean is given by ˆ X i
n i 1
From the standard normal tables, a =0.05, implies za/22
Finally, the sample variance is given by
Therefore, for n large,
Pr ˆn 2 Sˆn2 / n ˆn 2 Sˆn2 / n 0.95
SampleInterval.m
How Good is the Approximation
The standard normal N(0,1) approximation is valid as
long as n is large enough, but how large is good
enough?
Alternatively, the confidence interval can be evaluated
based on the t-student distribution with n degrees of
freedom
A t-student random variable is obtained by adding n iid
Gaussian random variables (Yi) each with mean μ and
variance σ2.
n
T
1
n
Y
i 1
i
2n
Terminating and Non-Terminating
Simulation
Terminating Simulation
There
is a specific event that determines when the
simulation will terminate
E.g., processing M packets or
Observing M events, or
simulate t time units,
...
Initial
conditions are important!
Non-Terminating Simulation
Interested
in long term (steady-state) averages
lim E X k
k
Terminating Simulation
Let X1,…,XM are data collected from a terminating
simulation, e.g., the system time in a queue.
X1,…,XM are NOT independent since
Xk=max{0, Xk-1-Yk}+Zk
Yk, Zk are the kth interarrival and service times respectively
Define a performance measure, say
Run N simulations to obtain L1,…,LN.
Assuming independent simulations, then L1,…,LN are
independent random variables, thus we can use the
sample mean estimate
Examples: Terminating Simulation
Suppose that we are interested in the average time it will
take to process the first 100 parts (given some initial
condition).
Let T100,j j=1,…,M, denote the time that the 100th part is
finished during the j-th replication, then the mean time
required is given by
Suppose we are interested in the fraction of customers
that get delayed more than 1 minute between 9 and 10 am
at a certain ATM machine.
Let be the delay of the ith customer during the jth
replication and define 1[Dij]=1 if Dij>1, 0 otherwise. Then,
Non-Terminating Simulation
Any simulation will terminate at some point m < ∞, thus the
initial transient (because we start from a specific initial
state) may cause some bias in the simulation output.
Replication with Deletions
The suggestion here is to start the simulation and let it run for a
while without collecting any statistics.
The reasoning behind this approach is that the simulation will
come closer to its steady state and as a result the collected data
will be more representative
0
r
m
time
Non-Terminating Simulation
Batch Means
Group
the collected data into n batches with m samples
each.
Form the batch average
Take
For
the average of all batches
each batch, we can also use the warm-up periods
as before.
Non-Terminating Simulation
Regenerative Simulation
Regenerative process: It is a process that is characterized by
random points in time where the future of the process becomes
independent of its past (“regenerates”)
Regeneration points divide the sample path into intervals.
Data from the same interval are grouped together
We form the average over all such intervals.
Example: Busy periods in a single server queue identify
regeneration intervals (why?).
In general, it is difficult to find such points!
Empirical Distributions and
Bootstrapping
Given a set of measurements X1,…,Xn which are
realizations of iid random variables according to some
unknown FX(x;θ), where θ is a parameter we would like to
estimate.
We can approximate FX(x; θ) using the data with a pmf
where all measurements have equal probability 1/n.
The approximation becomes better as n grows larger.
Example
Suppose we have the measurements x1,…,xn that came from
a distribution FX(x) with unknown mean θ and variance σ2.
We would like to estimate θ using the sample mean μ. Find
the Mean Square Error (MSE) of the estimator based on the
empirical data.
1
2/n
1/n
x1
x2
…
xn X
Empirical distribution
Example
n
1 n
xi pi xi
n i 1
i 1
2
n
1
MSEe Ee g X E
Xi
e
n i 1
2
2
n
1 n
1
1
Ee 2 X i 2 Ee X i 2 Vare X i
n i 1
n
i 1
n
1 n
2
Vare X i Ee X xi
n i 1
2
Therefore