Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
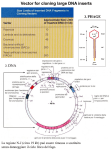
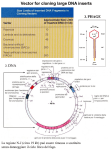
Genomic and cDNA libraries DNA Libraries …collections of cloned DNA fragments, – genomic, – cDNA (coding sequences). Genomic Library Construction • Cloning all fragments of an organisms genome = genomic library – Each fragment in a vector transformed into a bacterial cell = Book – The collection of all of the clones (thousands) is the genomic library – requirement: *random * bigger is better Genomic Library Construction DNA fractioning • DNA shearing • to ensure that DNA fragments are of size suitable for cloning – Digest with enzyme with 4bp recognition site – One site every 256bp (1/4 x 1/4 x 1/4 x 1/4) – Do a partial digestion (not all sites cleaved) – Ligate fragments to vector – Transform into E. coli Genomic Sequences and Coverage N = ln(1 - P) ln(1 - f) N = number of clones P = probability of recovering a sequence, f = fraction of the genome of each clone f = genome lenght average lenght of insert Probability 0.99 0.95 0.9 0.8 Insert lenght 15kb 40kb 860000 560000 430000 300000 320000 210000 160000 115000 Results for the human genome Making a genomic DNA library. Production of overlapping restriction fragments by partial digestion of human genomic DNA with Sau3A. This restriction endonuclease recognizes the 4-bp sequence GATC and produces fragments with single-stranded sticky ends with this sequence on the 5 end of each strand. A hypothetical region of human genomic DNA showing the Sau3A recognition sites (red) is shown at the top. Partial digestion of this region of DNA would yield a variety of overlapping fragments (blue) ≈20 kb long. Use of such overlapping fragments increases the probability that all sequences in the genomic DNA will be represented in a l library. Partial Digest Cosmid Cloning Cloning in Cosmids Production of overlapping restriction fragments by partial digestion of human genomic DNA with Sau3A. CHROMOSOME WALKING CHROMOSOME WALKING Chromosome ‘Walking’ DNA Libraries …collections of cloned DNA fragments, – genomic, – cDNA (coding sequences). Cloning euykaryotic genes in prkaryotes require special "tricks" because eukaryotic genes have introns which are removed in the nucleus of eukaryotic cells prior to translation Introns can account for more than 90% of the length of a eukaryotic gene. It is hard to clone very long DNA segments. In addition, intron-containing eukaryotic genes cannot be expressed in a bacterial host because prokaryotes lack splicing apparatus. To overcome these problems, instead of directly cloning a gene, one can clone cDNA, a DNA copy of gene mRNA. An enzyme, reverse transcriptase, is used to produce cDNA cDNA …DNA synthesized from an mRNA template with the enzyme reverse transcriptase. Reverse Transcriptase 1. RNA dependent, DNA synthesis. 2. RNA Degradation. 3. DNA dependent, DNA Synthesis. Basically two types: - AMV (aviary myeloblastosis) - MMLV (Moloney Murine Leukemia Virus) Error Rate: 1 in 20,000 nucleotides. Isolation of mRNA by oligo-dT affinity chromatography. cDNA Construction in vitro RNA degradation by alkali DNA pol and second strand synthesis Cleavege of hairpin by Nuclease S1 Terminal transferase and ligation into vector cDNA Strategy to synthetize double strand cDNA B) cDNA Synthesis mRNA AAAAAn Anneal oligo dT primer primed mRNA AAAAAn TTTTT Reverse Transcriptase and dNTPs mRNA/cDNA hybrid AAAAAn TTTTT Gubler Hoffman cDNA Synthesis mRNA/cDNA hybrid AAAAAn TTTTT RNase H nicked RNA AAAAAn TTTTT DNA Pol I nicked RNA used as primers by Pol AAAAA TTTTT Gubler Hoffman cDNA Synthesis 2nd strand cDNA in pieces AAAAA TTTTT E. coli DNA Ligase AAAAA ds cDNA TTTTT Clone into vector cDNA Library cDNA Libraries …provide a ‘snap-shot’ of the genes expressed in a particular cell, at a particular time, or under specific condition, …however, do not provide regulatory sequences. cDNA Libraries Limits: …using a oligo dT, library has 3’-rich sequences Using random examers it’s possible overcome this drawbacks, but the average length of sequences is reduced. …hard to isolate long and full-lenght transcripts. CAPture method: AAA Full cDNA incomplete cDNA AAA TTT AAA TTT Rnase A AAA TTT AAA TTT Chromatography for elF-4E AAA TTT Elution of full-lenght cDNA BAP= Alkaline phosphatase TAP= acid pyrophosphatase 5’ - RACE Rapid Amplification Complementary Ends mRNA 7-mG AAAAA-3’ Sintesi primo filamento cDNA Trascrittasi inversa + GSP1 7-mG GSP1 Aggiunta coda omopolimera al primo filamento cDNA GSP1 5’ P TTTT P TTTTT 3’ TTTTT GSP1’ 3’ 3’ P TTTTT P’ AAAAA GSP1 5’ complementarietà al primer GSP1 GSP1 5’ I° gruppo di amplificazioni 5’ P GSP2 P TTTTT 3’-AAAAAAAAA 5’ Trasferasi terminale + dATP 3’-AAAAAAAAA Sintesi secondo filamento cDNA AAAAA-3’ II° gruppo di amplificazioni GSP1’ 3’ GSP1 5’ complementarietà al primer P(dT) 5’ P TTTTT GSP1’ 3’ 3’ P’ AAAAA GSP1 5’ 5’ P TTTTT GSP2’ 3’ 3’ P’ AAAAA GSP2 5’ Prodotto PCR finale 3’ - RACE Rapid Amplification Complementary Ends mRNA 7-mG AAAAAAAA-3’ Sintesi primo filamento cDNA Trascrittasi inversa + P(dT) 7-mG AAAAAAAA-3’ TTTTT Sintesi secondo filamento cDNA GSP1 P complementarietà al primer P(dT) GSP1 3’ TTTTT complementarietà al primer GSP1 P 5’ I° gruppo di amplificazioni 5’ GSP1 AAAAA P’ 3’ 3’ GSP1’ TTTTT P 5’ II° gruppo di amplificazioni 3’ GSP1’ GSP2 5’ GSP1 TTTTT P TTTTT P AAAAA P’ 5’ 3’ 5’ GSP2 AAAAA P’ 3’ 3’ GSP2’ TTTTT P 5’ Prodotto PCR finale Identification of a specific clone from a library by membrane hybridization to a radiolabeled probe Source of the DNA Probe? • Probe DNA must have complementarity with target DNA • Two sources – Related organism - heterologous probe – Reverse translate protein sequence DNA Probe • Probe from Related Organism – sequences are related evolutionarily – not identical but similar enough – Heterologous Probe – Use yeast gene to isolate Human gene DNA Probe • Reverse translate protein sequence – Use knowledge of Genetic Code to obtain DNA sequence(s) based on protein seq. – MET = AUG in RNA ATG in DNA (or 5’ CAT) Genetic Code Table Reverse Translation of Protein Seq. MET-TRP-TYR-GLN-PHE-CYS-LYS-PRO ATG-TGG-TAT-CAA-TTT-TGT-AGA-CCN C G C C G 32 Different oligonucleotides for this peptide sequence (due to degeneracy of code) Radiolabeling of an oligonucleotide at the 5 and with phosphorus-32. The three phosphate groups in ATP are designated the a, b, and g phosphates in order of their position away from the ribose ring of adenosine (Ad). ATP containing the radioactive isotope 32P in the g-phosphate position is called [g-32P]ATP. Kinase is the general term for enzymes that transfer the gphosphate of ATP to specific substrates. Polynucleotide kinase can transfer the 32P-labeled g phosphate of [g-32P]ATP to the 5 end of a polynucleotide chain (either DNA or RNA). This reaction is commonly used to radiolabel synthetic oligonucleotides. Labelling of PCR products using a radioactive dNTP! Designing oligonucleotide probes based on protein sequence. The determined sequences then are analyzed to identify the 6- or 7-aa region that can be encoded by the smallest number of possible DNA sequences. Because of the degeneracy of the genetic code, the 12-aa sequence (light green) shown here theoretically could be encoded by any of the DNA triplets below it, with the possible alternative bases at the same position indicated. For example, Phe-1 is encoded by TTT or TTC; Leu-2 is encoded by one of six possible triplets (CTT, CTC, CTA, CTG, TTA, or TTG). The region with the least degeneracy for a sequence of 20 bases (20-mer) is indicated by the red bracket. There are 48 possible DNA sequences in this 20-base region that could encode the peptide sequence 3 9. Since the actual sequence of the gene is unknown, a degenerate 20-mer probe consisting of a mixture of all the possible 20-base oligonucleotides is prepared. If a cDNA or genomic library is screened with this degenerate probe, the one oligonucleotide that is perfectly complementary to the actual coding sequence (blue) will hybridize to it. Colony PCR 2. Si mette su una reazione di PCR per ogni clone che si vuole analizzare, risospendendo nella mix di PCR una parte della colonia.Si utilizza una coppia di primers specifica per l’inserto clonato 1. Si piastra, come al solito, una trasformazione. I cloni trasformanti possono contenere il solo vettore o il vettore più l’inserto M 1 2 3 4 5 _ + I cloni 1,2,3 e 4 contengono l’inserto. Il clone 4 contiene solo il vettore. “-” e “+” sono controlli negativo e positivo Immunological Screening • Antibodies to the protein encoded by the desired gene can be used to screen a library Immunological Screen master plate matrix 1 6 transfer cells cells protein 2 lyse cells bind protein subculture cells from master plate 3 positive signal 5 4 Add substrate Add 2°Ab-Enzyme wash Add 1°Ab; wash Immunological Screen of Library substrate detectable product reporter enzyme 2° Ab 1° Ab target protein matrix o---- Cloning strategies ----o I. II. Making DNA “libraries” (from genomic DNA, mRNA “transcriptome”) Screening to identify a specific clone (the needle in the haystack) -- by the sequence of the clone -- by the structure or function of the expressed product of the clone Course reading: #28 (and 29) Overview of strategies for cloning genes 1) 2) 3) Get DNA Ligate to vector Transform or transfect Look for the gene… 4) 1) Get DNA Genomic DNA RNA Ligate to vector: how to make this reaction favorable? This yields a “library”, a representative set of all the pieces of DNA that make up a genome (or all the cDNAs that correspond to the “transcriptome”) cDNAs from different tissues reflect the different RNA populations that you find in distinct cell types: Hence “liver” vs. “brain” vs. “heart” cDNA libraries There are lots of ways to identify a particular gene… Overview of strategies for cloning genes