Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Ontologies & Databases:
Similarities & Differences
Ontolog Panel
Dr. Leo Obrst
MITRE
Information Semantics
Center for Innovative Computing & Informatics
October 12, 2006
Summary
• Databases:
–
–
–
–
Focus on local semantics that have only aspects of the real world
Typically keep that semantics implicit
Use logic structurally
Their schemas are not generally reusable
• Ontologies:
– Focus on global semantics of the real world
– Make that semantics explicit
– Enable machine interpretability by using a logic-based modeling
language
– Are reusable as true models of a portion of the world
2
Tightness of Coupling & Semantic
Explicitness
Explicit, Loose
Far
Performance = k / Integration_Flexibility
Semantics Explicitness
EA Ontologies
EA Brokers
Proof, Rules, Modal Policies: SWRL, FOL+
Internet
Semantic Mappings
Semantic Brokers
OWL-S
Agent Programming
Enterprise Ontologies
RDF/S, OWL
EA
Peer-to-peer
Web Services: UDDI, WSDL
Web Services: SOAP
Community
Applets, Java
XML, XML Schema
N-Tier Architecture SOA
Workflow
Ontologies
EAI
Same Intranet
Conceptual Models
Enterprise
Middleware Web
Data Marts
Same Wide Area Network Client-Server
Data Warehouses
Same Local Area Network
Federated DBs
Distributed Systems OOP
Systems of Systems
Same DBMS
Same OS
Same
Same CPU
From Synchronous Interaction to
Linking
Address
Same Programming Language
Asynchronous Communication
Space
Compiling
Same Process Space
1 System: Small Set of Developers
Local
Implicit, TIGHT
Looseness of Coupling
3
Ontology Spectrum: One View
strong semantics
Modal Logic
First Order Logic
Logical Theory
Is Disjoint Subclass of
with transitivity
Description Logic
DAML+OIL, OWL
property
UML
Conceptual Model
RDF/S
XTM
Extended ER
Thesaurus
ER
Relational
Model, XML
weak semantics
Semantic Interoperability
Has Narrower Meaning Than
DB Schemas, XML Schema
Taxonomy
Is Subclass of
Structural Interoperability
Is Sub-Classification of
Syntactic Interoperability
4
Ontology Spectrum: Application
Concept- based
Ontology
weak
Expressivity
Term- based
strong
Logical Theory
Conceptual
Model
Thesaurus
Taxonomy
Categorization,
Simple Search &
Navigation,
Simple Indexing
Synonyms,
Enhanced Search
(Improved Recall)
& Navigation,
Cross Indexing
Enterprise Modeling
(system, service, data),
Question-Answering
(Improved Precision),
Querying, SW Services
Application
Real World Domain Modeling, Semantic Search
(using concepts, properties, relations, rules),
Machine Interpretability (M2M, M2H semantic
interoperability), Automated Reasoning, SW
Services
5
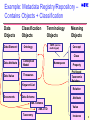
Example: Metadata Registry/Repository –
Contains Objects + Classification
Data
Objects
Data Element
Classification
Objects
Terminology
Objects
Term (can be
Ontology
multi-lingual)
Meaning
Objects
Concept
Class
Data Attribute
Conceptual
Model
Data Value
Thesaurus
Namespace
Property
Privileged
Taxonomic
Relation
Keyword List
Relation
Documents
Data Schema
Attribute
XML Schema
XML DTD
Taxonomy
Value
Instance
6
Approximate Cost/Benefit of Moving
up the Ontology Spectrum
Cost
Higher
Initial
Costs
Higher
initial
costs
at each
step
up
Increasingly greater benefit
because of increased
semantic interoperability,
precision, level machinehuman interaction
Logical Theory
Time
Much lower
eventual
costs
because of
reuse, less
analyst labor
Thesaurus Conceptual Model
Taxonomy
Cost
Benefit
7
What Problems Do Ontologies Help
Solve?
• Heterogeneous database problem
– Different organizational units, Service Needers/Providers have radically
different databases
– Different syntactically: what’s the format?
– Different structurally: how are they structured?
– Different semantically: what do they mean?
– They all speak different languages
• Enterprise-wide system interoperability problem
– Currently: system-of-systems, vertical stovepipes
– Ontologies act as conceptual model representing enterprise consensus
semantics
– Well-defined, sound, consistent, extensible, reusable, modular models
• Relevant document retrieval/question-answering problem
– What is the meaning of your query?
– What is the meaning of documents that would satisfy your query?
– Can you obtain only meaningful, relevant documents?
8
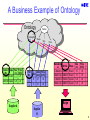
A Business Example of Ontology
Ontology
Catalog No.
Catalo Shape Size Price …
g No.
(in) ($US)
XAB023 Round 1.5 .75
XAB035 Square 1.25 .25
Supplier A
Washer
Shape
Size
Part
Diam Price
Geom.
…
No.
(mm) ($US)
55029
R
37
.35
6
55029
S
31
.45
8
Supplier
B
Price
Manufactur
er
E-Machina
iMetal Corp.
E-Machina
iMetal Corp.
Size
(in)
550296 Round 1.5
XAB023 Round 1.5
550298 Square 1.25
XAB035 Square 1.25
Mfr No. Shape
Price
…
($US)
.35
.75
.45
.25
Buye
r
9
Ontologies & the Data Integration
Problem
• DBs provide generality of storage and efficient access
• Formal data model of databases insufficiently semantically
expressive
• The process of developing a database discards meaning
– Conceptual model Logical Model Physical Model
– Keys signify some relation, but no solid semantics
– DB Semantics = Schema + Business Rules + Application Code
• Ontologies can represent the rich common semantics that spans
DBs
AMilitary Example of Ontology
– Link the different structures
– Establish semantic properties
of data
– Provide mappings across
data based on meaning
– Also capture the rest of the
meaning of data:
• Enterprise rules
• Application code
(the inextricable semantics)
Ontology
Identifier
Tid
Type
CNM023
MIG-29
CNM035
Tupolev
TU154
Aircraft
Signature
Location Time Observed
LongLat Tstamp …
121.135°
121.25°
13458
13465
S-code
Model
330296
F-14D
Coord SenseTime …
Identifier
Signature
Location
Time
Observed
Navy
330296
F-14D
121°8'6"
2.35
13458
Army
CNM023
MIG-29
121.135°
121°8'6"
2.35
Navy
330298
121°2‘2"
2.45
330298 AH-1GC 121°2‘2"
2.45
Army
CNM035
AH-1GC
Tupolev
TU154
121.25°
13465
…
Sexigesimal
Decimal
Army
Service
UTM
Coordinate
Geographic
Coordinates
Navy
Commander,
S2, S3
10
Background on Relational Calculus for
Databases
• Relational Calculus
– Tuple Relational Calculus (TRC)
• More like a pre-relational file structure format
– Domain Relational Calculus (DRC)
• Similar to logic as a modeling language
– Relational Algebra (RA)
– Roughly equivalent expressivity: all the above
– SQL: slightly more powerful because of some
computation, ordering, etc.
• These use the syntax of FOL but only a
very simplified semantics
11
Ontologies & Databases
•
•
•
•
•
Ontologies are about vocabularies and their meanings, with an explicit, expressive, and
well-defined semantics, possibly machine-interpretable
Ontologies try to limit the possible formal models of interpretation (semantics) of those
vocabularies to the set of meanings a modeler intends, i.e., close to the human
conceptualization
None of the other "vocabularies" such as database schemas or object models, with less
expressive semantics, does that
The approaches with less expressive semantics typically assume that humans will look
at the "vocabularies" and supply the semantics via the human semantic interpreter (your
mental model)
Additionally a human developer will code programs to enforce the local semantics that
the database/DBMS cannot
– They may or may not get it right
– Other humans will have to read that code, interpret it, and see if it's actually doing what
everyone thinks it should be doing
– The higher you go in terms of data warehouses, marts, etc., the more human interpreted
semantic error creeps in
•
•
Ontologies model generic real world concepts and their meanings, unlike either
database schemas or object models, which are typically very specific to a particular set
of applications and represent limited semantics
A given ontology cannot model completely any given domain
– However, in capturing real world (and imaginary, if you wish, i.e., you might want a theory of
unicorns and other fantastic beasts) semantics, you are thereby enabled to reuse, extend,
refine, generalize, etc., that semantic model
12
Ontologies & Databases
•
It's suggested you reuse ontologies
– You cannot reuse database schemas
– You might be able to take a database conceptual schema and use that as the basis of an
ontology, but that would still be a leap from an Entity-Relation model to a Conceptual Model
(say, UML, i.e., a weak ontology) to a Logical Theory (strong ontology)
– In much the same way, you can start with a taxonomy or a thesaurus and migrate it to an
ontology
– But logical and physical schemas are typically pretty useless, since they incorporate non real
world knowledge (and in non-machine-interpretable form)
– By the time you have the physical schema, you just have relations and key information: you've
thrown away the little semantics you had at the conceptual schema level
•
The methodology for ontologies and databases are similar (as for all models in the
Ontology Spectrum) insofar as the database designer or knowledge/ontology engineer
has to consider an information space that captures certain kinds of knowledge
– However, a database designer does not care about the real world, per se, but about
constructing a specific local container/structure of data that will hold his/her user's data in an
access-efficient way
– A good database designer will sit down with users and generate use cases/scenarios based on
interaction with the users. Similarly, for ontologists: they'll sit down with domain experts/SMEs
and get a sense of the semantics of the part of the world that these folks are knowledgeable
about
– A good ontologist will analyze the data available (if available; bottom up) and also analyze what
the domain expert says (top down)
– In many cases (intelligence analysis, e.g.), the ontologist won't ask the SME what kinds of
questions that person asks for their tasks, but also what kinds of questions they would like to
ask and which are impossible to get answered currently by using mainstream database and
system technology
13
The Database Design Process:
3 Stages
1) In interaction with prospective users and stakeholders of the proposed database, the
database designer will create a conceptual schema, usually using a modeling language
and tools based on Entity-Relation models, extended ER models, or recently, on objectoriented models using UML
2) Once this conceptual schema is captured, the designer will refine to become a logical
schema, sometimes called a logical data model, still in an ER language or UML. The
logical schema typically results by refining the conceptual schema using normalization
and other techniques to move closer to the so-called physical model that will be
implemented to create the actual database - by normalizing the relations (and attributes,
if the conceptual schema contains these) using the same ER and UML languages
3) Finally, refining the logical schema to become the physical schema, where the tables,
columns, keys, etc., are defined, and then the physical table optimized in terms of which
elements to index, which sectors in the database to place the various data elements
– A data dictionary may be created for the database; this expresses in natural language
documentation, what the various elements of the database are intended to mean
– The data dictionary is only semantically interpretable by human beings, since it is written in
natural language
– The most expressive real-world semantics of the database creation process thus exists in the
conceptual schema and the data dictionary
– The conceptual schema, may be kept around, as part of the documentation of the process of
developing the database, an artifact of that process
– The data dictionary, will typically be kept as documentation
– Unfortunately, the underlying physical database and its schema may be changed dramatically without the original conceptual schema and the data dictionary being comparably changed
– This is also typically the case with UML models used to create object-oriented systems and
sometimes to defined enterprise architectures
14
The Database Design Process
•
•
Databases typically try to enforce 3 kinds of integrity
1) Domain integrity (and note that this is not the same notion of "domain" we use in general in
logic/ontologies): domains are usually datatype domains, i.e., integers, strings, real numbers, or
column-data domains.
–
–
•
2) Referential integrity: this refers to key relationships, primary and foreign
–
•
–
•
•
This kind of integrity is structural, making sure that if a key gets updated, that any key in any other place that's dependent on it gets
updated appropriately to. Add, Delete, Update (usually considered an initial Delete, followed by an Add)
3) Semantic integrity: this is the hardest part. Represents real-world constraints/etc., sometimes
called "business rules" that you want to hold over your data
–
•
Typically you don't have any symbolic objects at all in a database, just strings
So on data entry or update say of a row, some program (or the DBMS) will make sure that if a column is defined to contain only integer
data, that the user can only enter integer data
Databases and DBMSs can't usually do this (even with active and passive triggers), and so auxiliary programming code usually has to
enforce this
Example:"no other employee can make more than the CEO", or other cross-dependencies.
You can't really check consistency of a database in the same way you can for an ontology in a logical
knowledge representation language
For databases, you can just enforce as best as you can the above 3 kinds of integrity
For an ontology, you can check consistency in two ways:
–
–
–
Syntactically (proof theory)
Semantically (model-theory)
But you can do this at two levels: (1) prove that your KR language is sound and complete, i.e., at the meta-level
•
•
•
•
•
–
–
Sound ('Phi |- A' implies 'Phi |= A'): the proof system will not prove anything that is not valid
Complete ('Phi |= A' implies 'Phi |- A'): the proof system is strong enough to prove everything that's valid
'Phi |- A' means something like: A follows from or is a consequence of Phi
'Phi |= A' means that A is a semantic consequence or entailment of Phi in some model (or valuation system) M (with truth values, etc.) I.e., the
argument is valid
Both |- and |= are called turnstyles, syntactic and semantic respectively
Check the consistency of a theory (ontology), i.e., at the object level
This is usually something like Negation consistency: there is no A such that both 'Phi |- A' and 'Phi |- ~A', i.e., a contradiction
15
Ontology Design
• If you are creating common knowledge (as opposed to deep domain
knowledge), you can in fact use your own intuition and understanding
of the world to develop your ontology
• It certainly helps to have a good background in formal ontology or
formal semantics, because then you've already learned
–
–
–
–
1) a rigorous, systematic methodology
2) formal machinery for expressing fine details of world semantics
3) an appreciation of many alternative analyses, pitfalls, errors, etc.
4) complex knowledge about things in the world and insight into your pretheoretical
knowledge
– In linguistics we say that although everyone knows how to use natural language like
English, very few know how to characterize that knowledge nor about prospective
theories about that knowledge
– Naive speakers don't have good subjective insight into how they do things; they just
do them
16
Ontologies vs. Databases
•
•
•
•
•
•
•
•
•
•
As is so often the case with non-ontological approaches to capturing the semantics of data, systems,
and services, the modeling process stops at a syntactic and structural model, and throws even the
impoverished semantic model away, to act as historical artifact, completely separated from the
evolution of the live database, system, or service, and still only semantically interpretable by a
human being who can read the documents, interpret the graphics, supply the real world knowledge
of the domain, and understands how the database, system, or service will actually be implemented
and used
Ontologists want to shift some of that "semantic interpretative burden“ to machines and have them
eventually mimic human semantics, i.e., understand what we mean
The result would be to bring the machine up to the human, not force the human to the machine level
By "machine semantic interpretation" we mean: by structuring and constraining in logical, axiomatic
language the symbols humans supply, the machine will conclude via an automated inference
process roughly what a human would in comparable circumstances
The knowledge representation language that enables this automated inference must be a language
that both makes fine modeling distinctions and has a formal or axiomatic semantics for those
distinctions, so no direct human involvement will be necessary – the meaning of "automated
inference"
Databases primary purpose is for storage and ease of access to data, not complex use
Software applications (with the data semantics embedded in nonreusable code via programmers)
and human beings must focus on data use, manipulation, and transformation, all of which require a
high degree of interpretation of the data"
Extending the capabilities of a database often requires significant reprogramming and restructuring
of the database schema
Extending the capabilities of an ontology can often be done by adding to its set of constituent
relationships
In theory, this may also include relationships for semantic mapping whereas semantic mapping
between multiple databases will require external applications
17